ICCK Transactions on Intelligent Systematics | Volume 2, Issue 4: 203-212, 2025 | DOI: 10.62762/TIS.2025.610574
Abstract
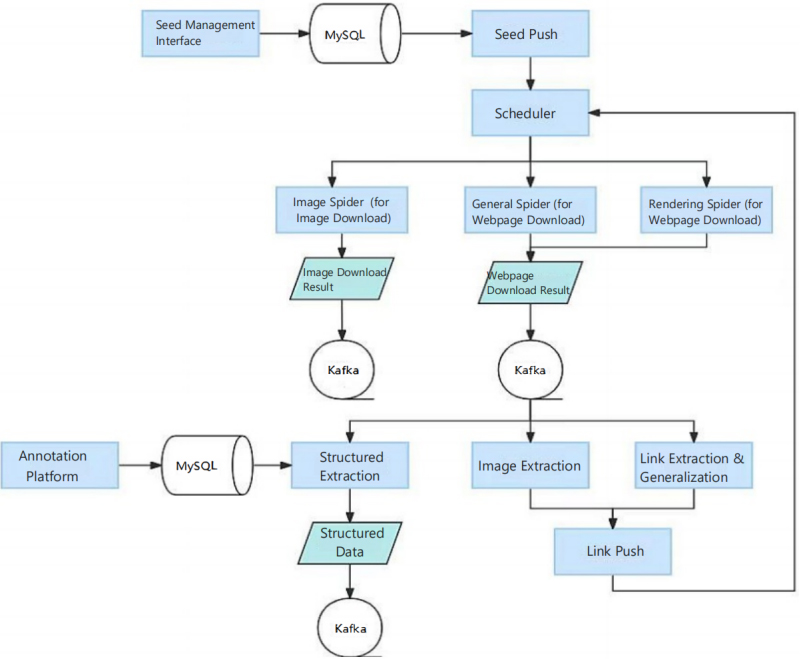
With the rapid development of multimodal large language models (MLLMs), structured event extraction (EE) has emerged as a critical intelligent information processing task, with increasing demand across multilingual and multimodal application scenarios. However, significant
challenges remain in zero-shot multimodal and cross-language scenarios, including inconsistent cross-language outputs and the high computational
cost of full-parameter fine-tuning. This study takes VideoLLaMA2 (VL2) and its improved version VL2.1 as the core models, and builds a multimodal
annotated dataset covering English, Chinese, Spanish, and Russian (including 5,728 EE samples). It systematically evaluates the... More >
Graphical Abstract