



Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]


Infrared and visible light sensor imaging technologies detect the essential characteristics and differences of scenes and targets through different radiation physical characteristics and detection mechanisms respectively, and there is a great complementarity between the two. Visible video contains texture information that is more suitable for visual perception, while infrared image can capture rich thermal radiation information in low light and other extreme harsh environments. Therefore, dual-channel video fusion can give full play to the complementary advantages of different imaging, reduce data redundancy, and be more conducive to all-weather target detection, tracking and recognition. It has important value in practical applications such as dangerous event monitoring in industrial areas, intelligent obstacle avoidance, medical imaging, and situation awareness [1, 2].
At present, the existing video fusion algorithms can be divided into two categories, static frame-by-frame fusion algorithms and overall fusion algorithms based on spatio-temporal information. Static frame-by-frame fusion algorithms include multi-scale transform fusion algorithms [3], sparse representation fusion algorithms [4], subspace-based methods [5], etc., and their real-time requirements are difficult to guarantee. The overall fusion algorithm based on spatio-temporal information uses spatio-temporal energy matching, spatio-temporal domain structure tensor, high-order SVD and other three-dimensional non-separable transformations [6, 7], and fully considers the spatio-temporal characteristics and temporal characteristics between each frame to ensure the stability and consistency of video data in the temporal domain. Most of the existing dual-channel video fusion algorithms rely on "prior knowledge" to select the fusion strategy. However, in the actual target detection process, due to the dynamics of the detection scene and the variability of the imaging environment, especially the types, amplitudes, frequencies and other characteristics of different features and their changes are more complex. The existing fusion model based on predefined is difficult to adapt to the changes of the "dynamic" difference features. Therefore, the traditional fusion algorithm has become the bottleneck of the performance improvement of the two kinds of video fusion.
In addition, in the current dual-channel video fusion method, most scholars only pay attention to the fusion effect of the algorithm on a single attribute of the difference feature or a single class of the difference feature, but ignore the influence of multiple attributes of the difference feature and the correlation between the features [8, 9] on the selection of the algorithm, resulting in problems such as poor semantic interpretation of the fusion process and difficulty in improving the fusion effect. Therefore, it is very important to study the influence of dynamic changes of multiple attributes such as difference feature types and amplitude between dual-channel videos and the correlation relationship between features on the fusion results for accurate video fusion.
It is found that under different algorithms, the effectiveness of video difference feature fusion has the characteristics of non-probability and interval variation. Generally, it is predicted and estimated based on the fusion strategy of existing and similar scenes, and the possibility distribution has significant advantages in solving the measurement of small sample uncertain information. Distributed composition theory can effectively solve the coordination and combination problem driven by multiple differences. Therefore, this paper proposes a two-way video mimic fusion algorithm based on possibility distribution synthesis theory to solve the problems that the current fusion model cannot adjust the fusion strategy according to the difference information between videos, and lacks of considering the synergy between the difference feature information. The complex relationship between the difference features, fusion strategy and fusion effect is established. It provides a new idea for effectively improving the fusion quality of infrared and visible video [10].
The remainder of this paper is structured as follows. Section 2 presents related work. Section 3 introduces our dual-channel video mimic fusion method. Experiments and discussions are shown in section 4. Subsequently, the conclusion is provided in Section 5.
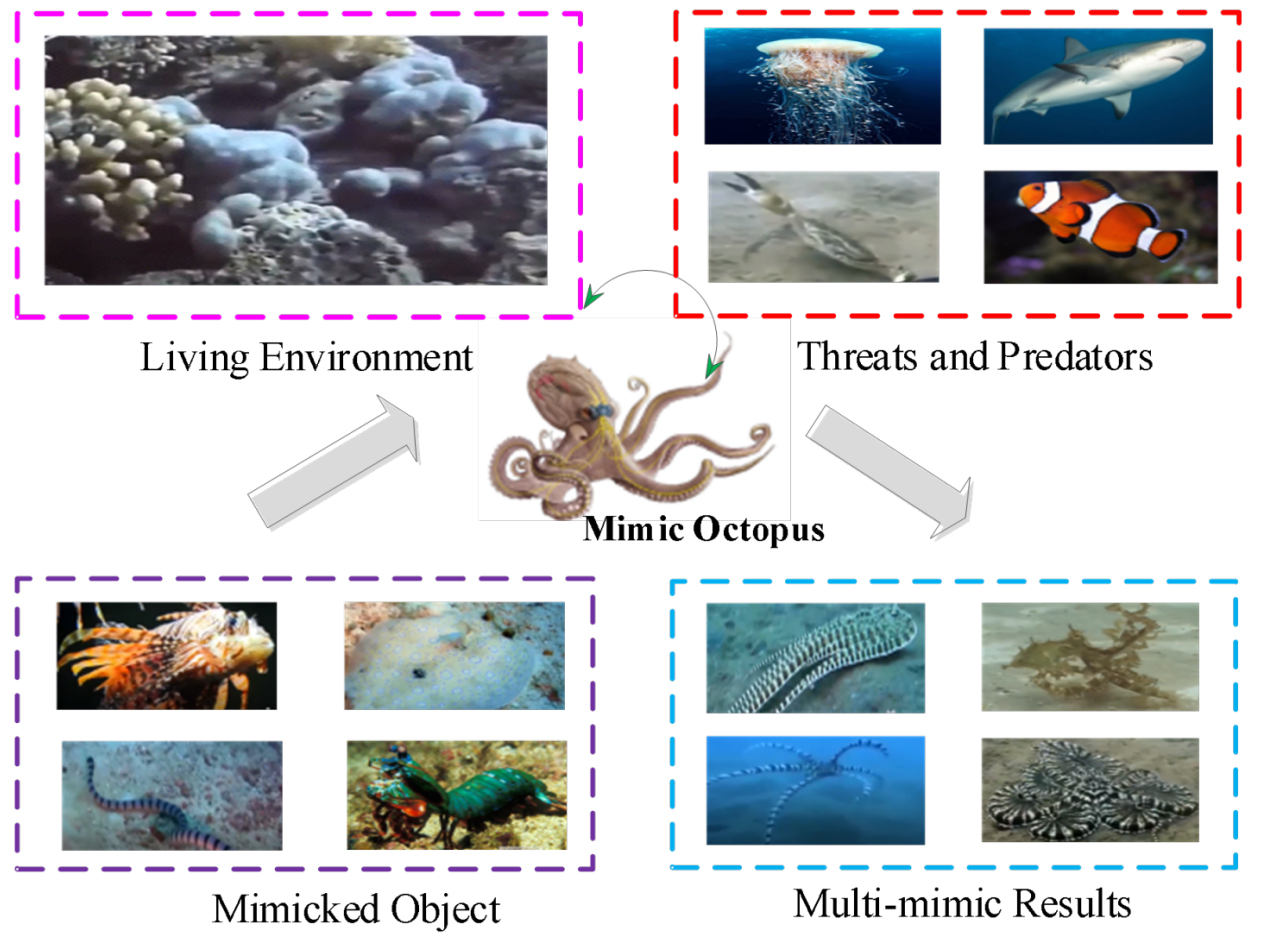
Mimicry [11] refers to an ecological adaptation phenomenon in which an organism disguises itself as another organism in terms of behavior, color or morphology, so as to benefit one or both of them. It is the product of long-term evolution of organisms in nature. Multiple mimicry bionics [12] refers to the bionic science that mimics the mechanism and structure of the bionic system based on the study of biological polymorphism characteristics.
Mimic Octopus [13, 14] is a species of Mimic Octopus in the Octopus family, it was first discovered in the waters of Sulawesi Island in Southeast Asia in 1998, the mimetic octopus's anti-sky camouflage function can select the simulated object according to the type of predator it encounters. At present, it can simulate 15 different kinds of creatures such as lionfish, flounder, crinoids, sea snakes, sea anemones, jellyfish, etc., and has super multi-mimicking ability, as shown in Figure 1. For example, when it encounters large predatory fish, it chooses to imitate the venomous creatures of its highly venomous relatives, the blue-ringed octopus, jellyfish and lionfish, to scare off predators. When the mimic octopus disguised as a lionfish and encountered a real lionfish, it immediately switched and disguised as a flounder; when it encountered a flounder, it turned into a sea snake again, when it encountered a real sea snake, it transformed into the surrounding sandy land color, buried itself in the sand directly.
Hu et al. [15] proposed mimic computing by bionic mimic octopus, and developed the world's first mimic computing system aiming at the change and diversity of service objects, which can select and generate multi-functional equivalent computable entities according to dynamic parameters, and also proposed the concept of mimic defense. Gao et al. [16] built a mimic signal processing system based on mimic computing to effectively improve the processing performance and high flexibility of radar signal systems in multiple working modes, aiming at the requirements of high performance, high efficiency and high flexibility of signal processing under the condition of multi-functional integration of distributed opportunistic array radar. Inspired by the imitation ability of the mimic octopus, Xu [17] took advantage of its flexible and bendable advantages to propose a method of segmenting the bionic flexible arm, and established a flexible bionic arm model, which provided an exploration direction for the improvement of the imitation ability of the flexible robot. These methods provide ideas for the difference feature driven fusion in this paper.
Mimic fusion [18] refers to a biomimetic fusion method that imitates the multi-mimic behavior of a variety of organisms according to the survival needs of the mimic octopus, and establishes a variable structure of the fusion model, in order to solve the problem of poor effect or even failure when the fixed model fuses the dynamic scene sequence images, it perceives and extracts the difference features of the corresponding video frames according to the two types of imaging characteristics, and dynamically maps out the optimized fusion algorithm, so that difference features and fusion algorithm are closely combined.
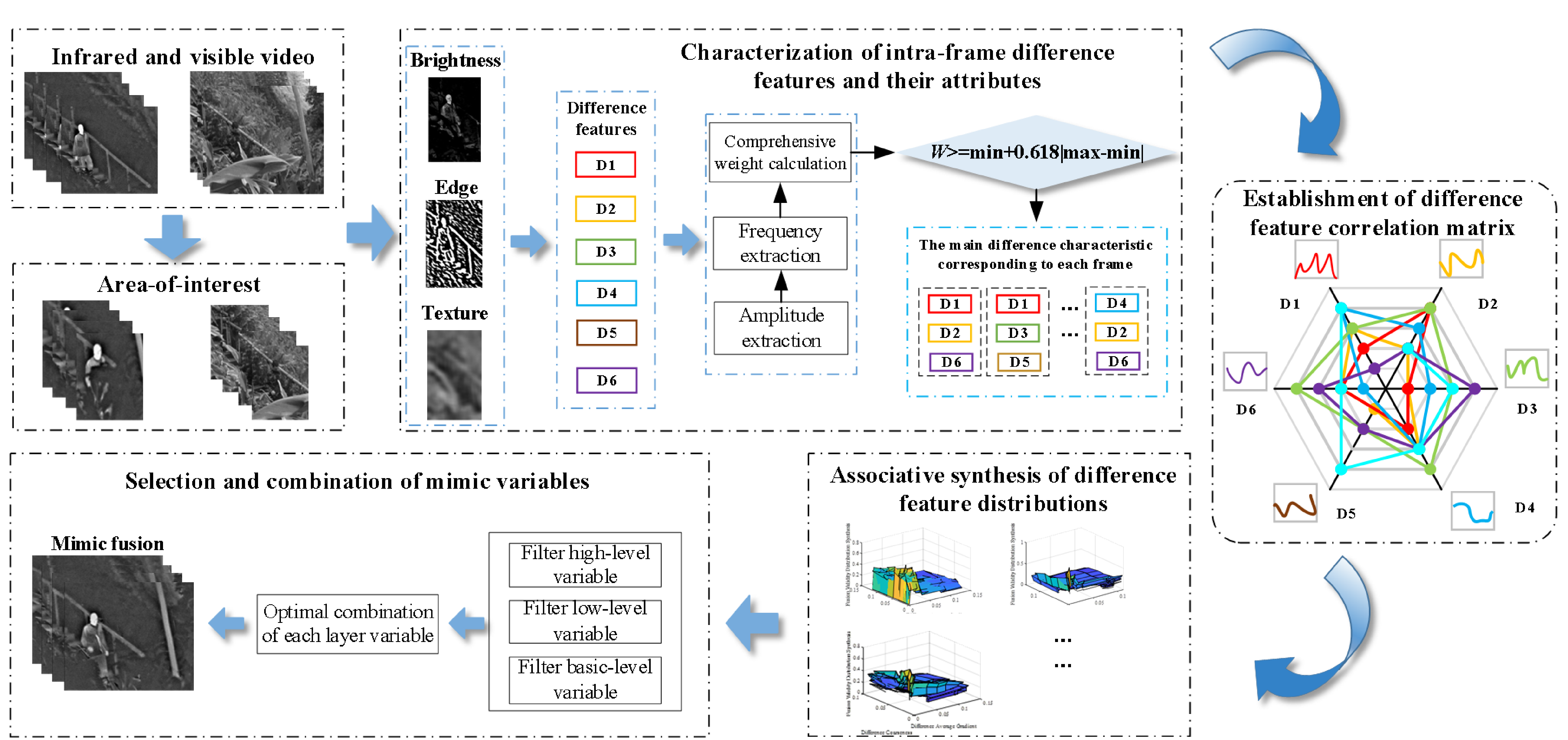
The flow chart of the dual-channel video mimic fusion method based on possibility synthesis theory proposed in this paper is shown in Figure 2, which mainly includes the representation of the difference features and their attributes in the infrared and visible video frames, the establishment of the difference feature correlation matrix, the correlation synthesis of the difference feature distribution, and the selection and combination of the mimic variables. The main process is as follows:

Firstly, the region of interest in the dual-channel video was roughly divided according to the fusion requirements, and six difference features were constructed to quantitatively describe the amplitudes of the three significant types of difference complementary information in the video. The frequency distribution of difference features is obtained using KNN [19, 20], and then the amplitude and frequency of difference features are used to construct comprehensive weights to coordinate the relationship between multiple attributes of difference features. According to the results, the main difference features of each frame are determined. Secondly, the Pearson correlation coefficient was used to measure the correlation between any two different features to obtain the feature correlation matrix. Then, based on the similarity measure, the effective degree distribution of each level variable for different difference features is constructed, and the possibility distribution synthesis rule is used to realize the association synthesis between different class difference feature distributions. Finally, the mimic variables are optimized according to the correlation synthesis results to realize the mimic fusion of the two videos.
The main differences between infrared and visible video are in three aspects: brightness, edge, and texture details (as shown in Figure 3). In order to effectively quantify these three types of differences, Mean Gray (GM), Edge Intensity (EI), Standard Deviation (SD), Average Gradient (AG), Coarseness (CA), and Contrast (CN) were used as its representation, and the gray mean was used to quantify the brightness information. Standard deviation, average gradient, and edge intensity are used to represent contrast information, edge clarity, and edge amplitude intensity information of edge information respectively. Contrast and roughness characterize the overall layout of pixel intensity contrast and the roughness of texture information, respectively, and constitute the difference feature set .
The difference feature amplitude represents the absolute difference degree of the features in the corresponding frames of the two videos, as shown in Equation (1), , respectively represent feature amplitude of feature to the th frame for infrared video and visible video.
From a macro perspective, the frequency attribute of difference feature reflects the extensiveness of certain difference feature distribution range in the imaging scene, from a microscopic perspective, it reflects the density distribution of a specific feature in the imaging scene with the change of the feature amplitude. Using the K-nearest neighbor nonparametric estimation method (KNN), the probability density distribution of the magnitude of the difference feature can be obtained, thereby obtaining the frequency attribute distribution of the difference feature.
In order to describe the distribution of various feature information of video, we use mn smooth window to perform non-overlapping block processing on the bimodal video sequence frame by frame to extract the corresponding feature information. After the segmentation, the amplitude points of various difference features in each frame of video are all M, which constitute a feature amplitude sample set {}. Because the difference feature sample set belongs to small sample information, it is necessary to expand the sample information set to meet the needs of non-parametric probability density estimation. The moving step of is set to step, after interpolation expansion, we got {}, where is the left boundary of the amplitude sample set, and is the right boundary, Samples are taken arbitrarily from {}, so the probability density estimate of difference feature is , shown in Equation (2).
where
and the probability density value of each amplitude point can be gradually obtained. Using complex trapezoidal integration in each difference feature amplitude sub-interval, approximately obtain the difference feature frequency value of each amplitude interval, shown in Equation (3). The amplitude interval is divided into sub-intervals, and each sub-interval is also divided into the same operation, the step size is set to , and difference feature amplitude probability density values are included in each sub-interval.
The comprehensive weight of the difference feature is a dynamic function of the proportion of the different attributes of the feature to the whole image, which represents the relative importance of different attributes. As shown in Equation (4), where is the difference feature comprehensive weight.
The main difference feature refers to the fact that for a group of images of different modalities, the difference information of this type of feature is more obvious and prominent than other features, and it is practical feasible and important to use it to guide the late mimic fusion. Since the comprehensive weight of difference features is used to coordinate the relationship between multiple attributes of difference features, its value is more reasonable and apparent comprehensive. In order to accurately judge the main difference features of each frame of dual-mode video, the golden section number is introduced into the comprehensive weight of difference features, and the feature judgment criterion is defined, see Equation (5). Then the main difference features of each frame are determined according to the screening results.
where represents comprehensive weight value of the corresponding feature of the th frame in the video sequence.
| corr | Correlation of | operator |
|---|---|---|
| Extremely negative correlation | ||
| Negative correlation | ||
| Irrelevant | ||
| Weak positive correlation | ||
| Positive correlation | ||
| Extremely positive correlation |
Pearson product-moment correlation coefficient (PPMCC) [21], as shown in Equation (6), is used to measure the linear correlation between two variables x and y. Here, it is used to describe the pairwise association relationship between different features. Thus, the feature correlation matrix is obtained, as shown in Equation (7), where k represents a total of k kinds of difference feature, represents the correlation value of difference features and .
Distribution synthesis [22, 23] is to synthesize the distribution of multi-source information according to a certain synthesis rule to obtain a more accurate expression and estimation of information. operator is suitable for the case of large intersection of various types of information, and can effectively deal with redundant information. In this paper, the operator is used to establish the association synthesis rules of the comprehensive weights of different difference features, and the corresponding synthesis results are obtained. The operator is defined as follows:
Let be a binary function defined in , for , if it satisfies the boundedness,monotonicity, commutative law. The rules are as follows:
The feature correlation matrix obtained based on Pearson correlation coefficient is combined with the operator to obtain the specific calculation formula of the operator, as shown in Table 1. That is, according to the obtained correlation matrix element values, the corresponding operator is selected for distribution synthesis, so as to establish the difference feature comprehensive weight association synthesis based on multi-rule combination.
By establishing the distribution synthesis between the comprehensive weight of heterogeneous difference features and multiple mimic variables, the projection axis direction of the synthesis distribution is determined by analyzing the importance degree of different attributes of the difference features, so as to obtain the correlation shadow of the fusion effectiveness of multiple mimic variables of heterogeneous difference feature weight function. The fusion effectiveness is to measure the quality of the fusion effect of the mimic variable on a certain difference feature, and the evaluation function of the fusion effectiveness is defined based on the similarity measure, as shown in Equation (8).The larger the value, the more effective the fusion is, and representation of the feature of the pixel block corresponding to the fusion result of the frame of the video sequence obtained based on the variable .
where and represent the weights of infrared and visible video frames, respectively.

The mimic variables included in the experiment in this paper refer to high-level variable sets, low-level variable sets and Basic-level variable sets, which are as follows:
High-level variable set: We select seven algorithms in the multi-scale fusion framework, including curvelet transform (CVT) [24], non-subsampling Shearlet transform (NSST) [25], non-subsampling contourlet transform (NSCT) [26], wavelet packet transform (WPT) [27], static wavelet transform (SWT) [28], Laplacian pyramid (LP) [29] and dual-tree complex wavelet transform (DTCWT) [30], which are denoted as in turn.
Low-level variable set: The low-level variables in the multi-scale fusion framework were mainly divided into high-frequency rules and low-frequency rules, and the low-frequency rules mainly included simple average weighted (SAW), coefficient maximization (CM), based on window energy (WE). The high-frequency rules mainly include: maximum absolute value of coefficients (MAC), maximum coefficient (MC), based on window energy (WE), where the low and high frequency fusion rules can be arbitrarily combined in pairs [31, 32].
Basic-level variable set: The basic variable in the multi-scale fusion framework of this paper mainly refers to the number of multi-scale decomposition levels and the type of filters in the algorithm. The number of decomposition levels and filters are set according to the algorithm itself.
Based on Equation (8), the mimic variable corresponding to the one with the highest fusion effectiveness is selected as the best mimic variable of the difference feature. The mimic variable with the highest fusion effectiveness and all the mimic variables with the deviation less than 0.05 are considered as the best mimic variable. In addition, the ablation experiment is used in the experiment process, that is, when only the correspondence between the difference features and the high-level variables is studied, the same low-level variables should be used in the fusion process to maintain their consistency. When studying the relationship between difference features and low-level variables and basic-level variables, high-level variables should be fixed.
Two public data sets are used as examples to demonstrate the rationality of the proposed method. The first dataset is the OTCBVS dataset [33], which contains 17089 different scenes, in which 200 image pairs selected for the experiment are from OSU Color-Thermal change. The second dataset is the TNO Image Fusion dataset [34], which includes multispectral nighttime images related to military phase scenes under different weather conditions, and the Nato_camp_sequence containing 32 image pairs, all 360×270 images, is selected for validation.
| The comprehensive weight of the difference feature | |||||||
| Video frame | Discriminant value | GM | SD | AG | EI | CN | CA |
| 3 | 0.2873 | 0.2924 | 0.1895 | 0.2915 | 0.2891 | 0.1492 | 0.3726 |
| 5 | 0.2758 | 0.3103 | 0.2219 | 0.2739 | 0.2742 | 0.1654 | 0.3431 |
| 9 | 0.2904 | 0.2234 | 0.2719 | 0.3181 | 0.3078 | 0.2309 | 0.3310 |
| 19 | 0.2463 | 0.1736 | 0.2632 | 0.2911 | 0.2844 | 0.2350 | 0.2461 |
| GM | SD | AG | EI | CA | |
|---|---|---|---|---|---|
| GM | 1.0000 | 0.1506 | 0.1485 (T3) | 0.1883 | -0.1345 (T2) |
| SD | 0.1506 | 1.0000 | 0.7439 | 0.6596 | 0.0924 |
| AG | 0.1485 (T3) | 0.7439 | 1.0000 | 0.9486 | 0.0542 (T3) |
| EI | 0.1883 | 0.6596 | 0.9486 | 1.0000 | 0.0327 |
| CN | 0.1551 | 0.9657 | 0.6914 | 0.6152 | 0.0804 |
| CA | -0.1345 (T2) | 0.0924 | 0.0542 (T3) | 0.0327 | 1.0000 |
| GM | SD | AG | EI | CA | |
|---|---|---|---|---|---|
| GM | 1.0000 | 0.2043 | 0.1629 | 0.1900 | 0.0689 |
| SD | 0.2043 | 1.0000 | 0.7330 | 0.6997 | 0.0065 |
| AG | 0.1629 | 0.7330 | 1.0000 | 0.9549 (T6) | -0.1628 (T2) |
| EI | 0.1900 | 0.6997 | 0.9549 (T6) | 1.0000 | -0.1897 (T2) |
| CN | 0.2160 | 0.9690 | 0.6665 | 0.6544 | 0.0197 |
| CA | 0.0689 | 0.0065 | -0.1628 (T2) | -0.1897 (T2) | 1.0000 |
| GM | SD | AG | EI | CN | CA | |
|---|---|---|---|---|---|---|
| GM | 1.0000 | 0.3681 | 0.3234 | 0.3402 | 0.3726 | -0.0558 |
| SD | 0.3681 | 1.0000 | 0.8470 | 0.8253 | 0.9646 | 0.0921 |
| AG | 0.3234 | 0.8470 | 1.0000 | 0.9678 | 0.8091 | 0.0201 (T3) |
| EI | 0.3402 | 0.8253 | 0.9678 | 1.0000 | 0.8098 | -0.0446 |
| CN | 0.3726 | 0.9646 | 0.8091 | 0.8098 | 1.0000 | 0.0716 |
| CA | -0.0558 | 0.0921 | 0.0201 (T3) | -0.0446 | 0.0716 | 1.0000 |
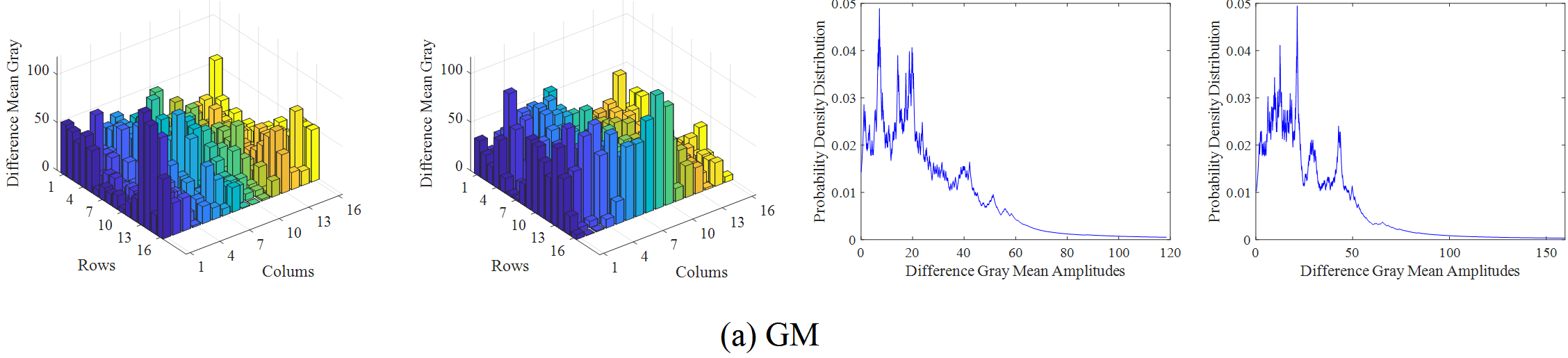
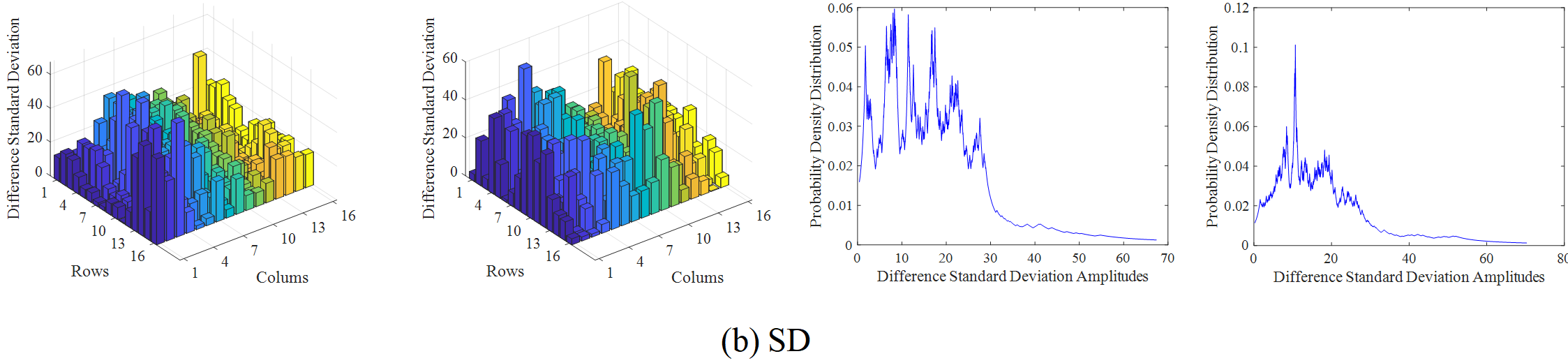
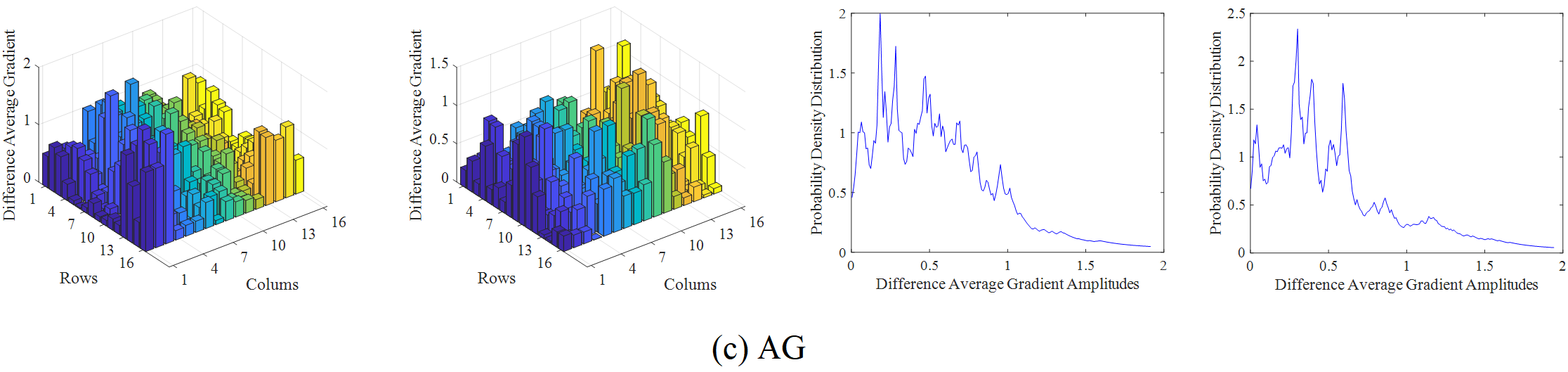
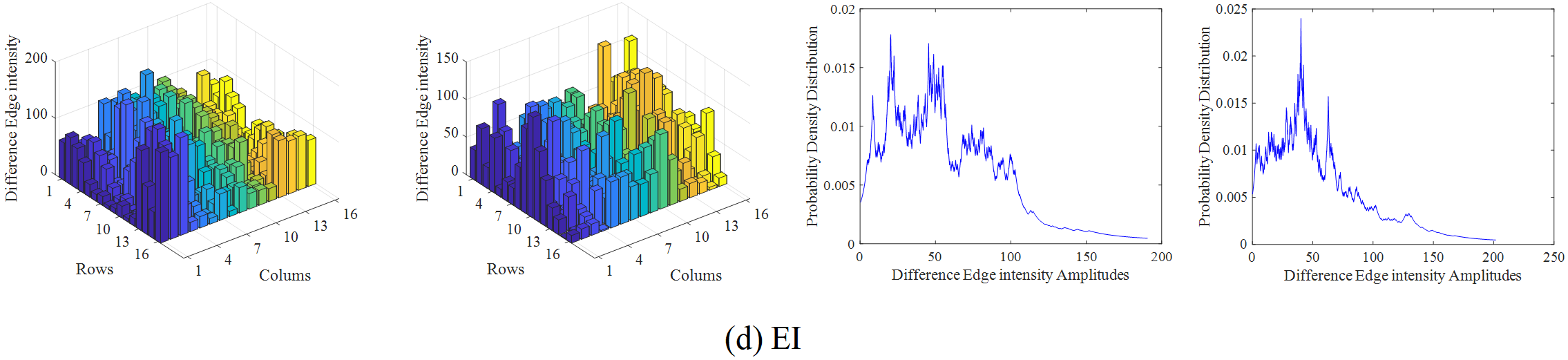
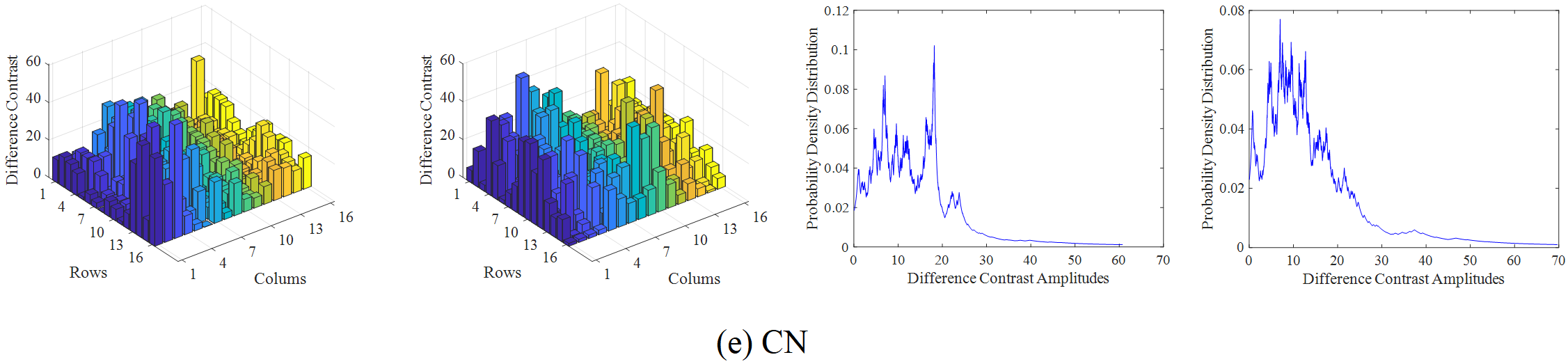
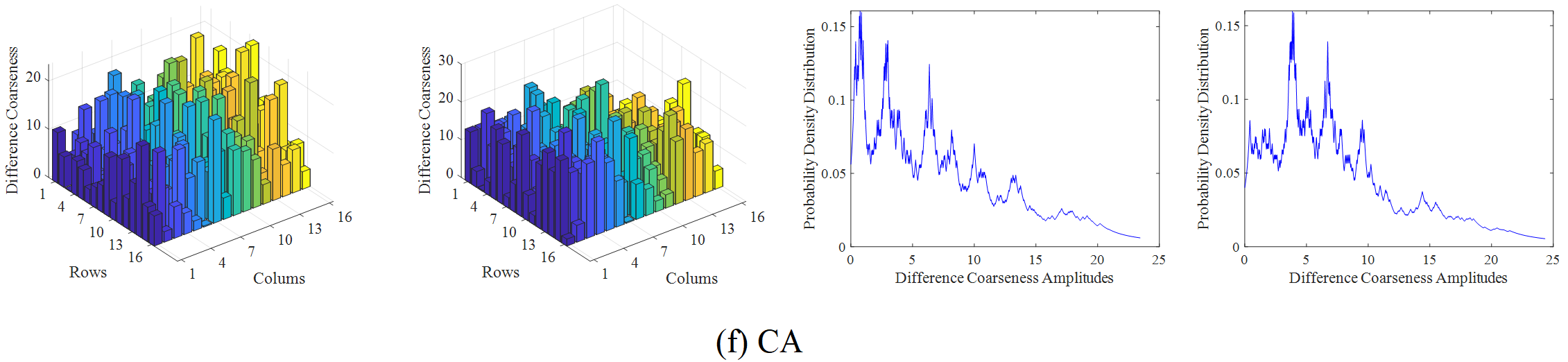
The infrared and visible video selected from the OTCBVS dataset is taken as an example to illustrate the overall process of the proposed method. Firstly, the region of interest is divided, as shown in Figure 4, and then the amplitude of various difference features in each frame of the video sequence is calculated by using formula (1), where m=n=16. Secondly, the probability density distribution of the difference feature amplitude is obtained based on KNN. Here, the step size of the difference feature amplitude point movement is set to, and the sample set is expanded by interpolation, so as to obtain the frequency distribution of the difference feature. The amplitude and frequency distribution results of the difference features are shown in Figure 5.
Calculate the comprehensive weight value of difference features according to Equation (4). For each video frame, the calculated comprehensive weight value of various difference features is filtered and sorted based on the feature discrimination condition, so as to determine the main difference features corresponding to each frame. The results are shown in Table 2, showing the results of frame 3, frame 5, frame 9, and frame 19. The features in red and bold in each row are the main difference features of the frame.
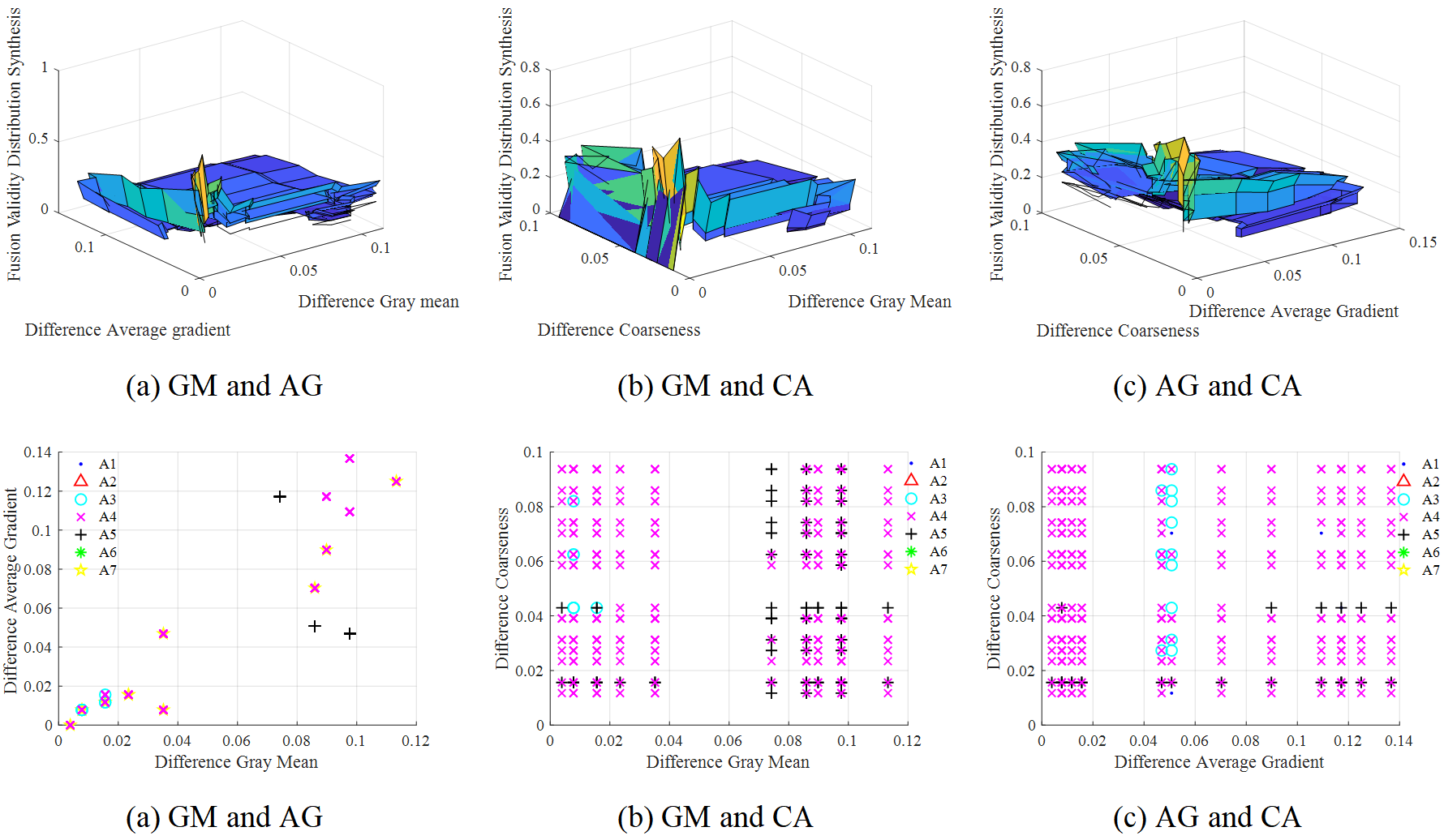
Then, according to PPMCC (see Equation (6)), the correlation relationship between the comprehensive weights of the six types of difference features was calculated respectively, so as to obtain the corresponding feature correlation matrix of each frame. The correlation relationship between features was expressed digitally by using table instead of matrix, as shown in Tables 3, 4 and 5. The feature correlation matrix values of frame 3, frame 5 and frame 19 are shown respectively, where the red bold is the main difference feature corresponding to the video frame, which is in one-to-one correspondence with the selected features in Table 3. In addition, the correlation The values between the comprehensive weights of the main difference features in each frame are bold in blue font, and the appropriate operator is selected according to the obtained correlation matrix element values, as shown in the brackets in Table 3, the main difference features selected according to the third frame are GM, AG and CA, where , and . , that is, the difference features GM and AG, AG and CA are not correlated, the corresponding T-modulus operator is T3, while , that is, GM and CA are negatively correlated, T2 operator is selected, and the same is true for other frames.
Finally, the feature fusion effectiveness under different mimic variables was synthesized by pairwise correlation according to the corresponding T-mode operator selected between the main difference features in each previous frame. For the fusion effectiveness synthesis value points corresponding to the comprehensive weights of the two types of difference features, the mimic variable with the largest fusion effectiveness in the mimic variable set was selected by using the disjunction operator. The correlation shadow of the difference feature synthesis results under different mimic variables is established, and then it is mapped to the combination surface of the corresponding two types of difference feature comprehensive weight values.
It is worth noting that if there is only one main difference feature for a video frame, the two steps of calculating the feature correlation matrix and constructing the feature correlation shadow are directly skipped, and the mimic algorithm variables are directly selected through the fusion effectiveness of the difference features under different mimic variables to realize the mimic fusion. If the main difference features of a video frame are (greater than or equal to two), it is necessary to consider the pairwise association of all elements in the main difference feature set, that is, including , , .
The clusters with the fusion effectiveness of the comprehensive weight function of various difference features in the associated shadow map greater than or equal to 0.1 were divided into significant fusion information areas. The number of occurrences of each mimic variable in the significant fusion information area of the comprehensive weight of various difference features and the corresponding fusion effectiveness value were counted, and the weighted statistics method was used to perform mathematical statistics on the results. Thus, the fusion proportion and average fusion effectiveness of the variable Ai of the mimic algorithm in this region are calculated, and the fusion score index is constructed, as shown in Equation (11). The fusion score indexes of different mimic variables under the comprehensive weight association method of various differences are summed up, and the mimic variables are determined according to the evaluation, and finally the mimic fusion is realized.
| Feature Association | Index | |||||||
| 0.0186 | 0 | 0.0217 | 0.8168 | 0.1180 | 0 | 0.0248 | ||
| 0.1717 | 0 | 0.1668 | 0.3316 | 0.1729 | 0 | 0.1717 | ||
| GM and AG | 0.0032 | 0 | 0.0036 | 0.2708 | 0.0204 | 0 | 0.0033 | |
| 0 | 0 | 0.0218 | 0.8836 | 0.0945 | 0 | 0 | ||
| 0 | 0 | 0.2468 | 0.2827 | 0.1944 | 0 | 0 | ||
| GM and CN | 0 | 0 | 0.0054 | 0.2498 | 0.0184 | 0 | 0 | |
| 0.0258 | 0 | 0.0115 | 0.9026 | 0.0602 | 0 | 0 | ||
| 0.1440 | 0 | 0.1359 | 0.2985 | 0.2248 | 0 | 0 | ||
| AG and CN | 0.0037 | 0 | 0.0016 | 0.2694 | 0.0135 | 0 | 0 | |
| Sum | 0.0069 | 0 | 0.0106 | 0.7901 | 0.0523 | 0 | 0 |
| Feature Association | Index | |||||||
| 0 | 0.1191 | 0 | 0.2742 | 0.3795 | 0.1330 | 0.0942 | ||
| 0 | 0.2462 | 0 | 0.4331 | 0.3376 | 0.3218 | 0.1979 | ||
| AG and EI | 0 | 0.0293 | 0 | 0.1188 | 0.1281 | 0.0428 | 0.0186 | |
| 0.0470 | 0.0043 | 0 | 0.0812 | 0.6154 | 0.2521 | 0 | ||
| 0.2763 | 0.1480 | 0 | 0.2191 | 0.2728 | 0.2273 | 0 | ||
| AG and CA | 0.0130 | 0.0006 | 0 | 0.0178 | 0.1679 | 0.0573 | 0 | |
| 0.7943 | 0.0348 | 0 | 0.1709 | 0 | 0 | 0 | ||
| 0.2172 | 0.3216 | 0 | 0.3976 | 0 | 0 | 0 | ||
| EI and CA | 0.1725 | 0.0112 | 0 | 0.0679 | 0 | 0 | 0 | |
| Sum | 0.1855 | 0.0412 | 0 | 0.2045 | 0.2960 | 0.1001 | 0.0186 |
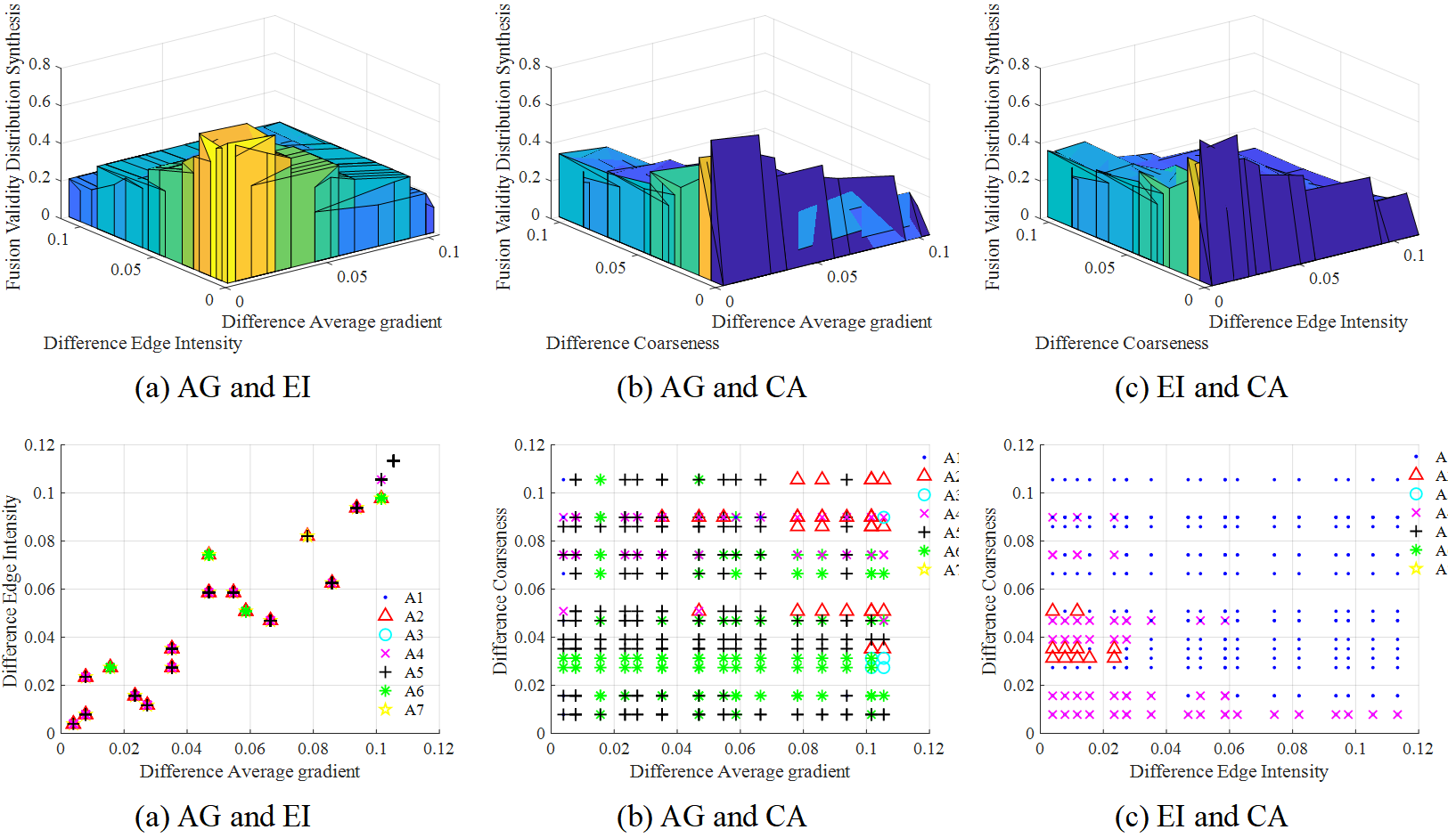

| Feature Association | Index | |||||||
|---|---|---|---|---|---|---|---|---|
| 0.4290 | 0.0195 | 0.0334 | 0.1031 | 0.3510 | 0.0641 | 0 | ||
| 0.2655 | 0.3524 | 0.1604 | 0.3184 | 0.3008 | 0.4372 | 0 | ||
| AG and CA | 0.1139 | 0.0069 | 0.0054 | 0.0328 | 0.1056 | 0.0280 | 0 |
| Evaluation Index | ||||||||
|---|---|---|---|---|---|---|---|---|
| Source Database | Method | MI | VIFF | RCF | ||||
| CVT | 0.4381 | 0.4954 | 0.6685 | 0.2307 | 2.0139 | 0.2706 | 27.4243 | |
| DTCWT | 0.3362 | 0.4283 | 0.5968 | 0.2233 | 1.8850 | 0.1558 | 27.0096 | |
| LP | 0.3689 | 0.4630 | 0.6235 | 0.2350 | 2.0329 | 0.2009 | 18.4434 | |
| NSCT | 0.4004 | 0.4571 | 0.6399 | 0.2390 | 2.2304 | 0.1942 | 18.5130 | |
| NSST | 0.4742 | 0.4879 | 0.7221 | 0.2663 | 2.2226 | 0.3412 | 27.4072 | |
| SWT | 0.3043 | 0.4578 | 0.5569 | 0.1988 | 2.1979 | 0.1876 | 19.4402 | |
| WPT | 0.2911 | 0.3961 | 0.5024 | 0.1518 | 1.8995 | 0.1319 | 18.8553 | |
| OTCBVS | Ours | 0.4727 | 0.4899 | 0.7238 | 0.2732 | 2.2318 | 0.3498 | 27.5825 |
| Evaluation Index | ||||||||
|---|---|---|---|---|---|---|---|---|
| Source Database | Method | MI | VIFF | RCF | ||||
| CVT | 0.3533 | 0.4755 | 0.6365 | 0.1606 | 1.9663 | 0.2530 | 12.1603 | |
| DTCWT | 0.3970 | 0.4389 | 0.6348 | 0.1791 | 1.8331 | 0.1981 | 12.6673 | |
| LP | 0.3775 | 0.3037 | 0.5225 | 0.1382 | 1.6262 | 0.1782 | 13.4800 | |
| NSCT | 0.4785 | 0.4653 | 0.6938 | 0.2105 | 1.7680 | 0.2072 | 13.4329 | |
| NSST | 0.4605 | 0.4076 | 0.6487 | 0.2379 | 1.7639 | 0.2362 | 16.7363 | |
| SWT | 0.3542 | 0.4680 | 0.6368 | 0.1654 | 2.0711 | 0.2718 | 10.8920 | |
| WPT | 0.3267 | 0.4369 | 0.5954 | 0.1544 | 1.8690 | 0.2064 | 11.6804 | |
| TNO | Ours | 0.5228 | 0.4980 | 0.7609 | 0.2223 | 1.8563 | 0.2156 | 16.7423 |
| Method | OTCBVS | TNO |
|---|---|---|
| CVT | 2.925 | 2.333 |
| DTCWT | 1.477 | 1.816 |
| LP | 3.101 | 4.455 |
| NSCT | 2.528 | 2.643 |
| NSST | 1.483 | 1.470 |
| SWT | 2.331 | 2.314 |
| WPT | 2.505 | 2.218 |
| Ours | 1.360 | 1.609 |
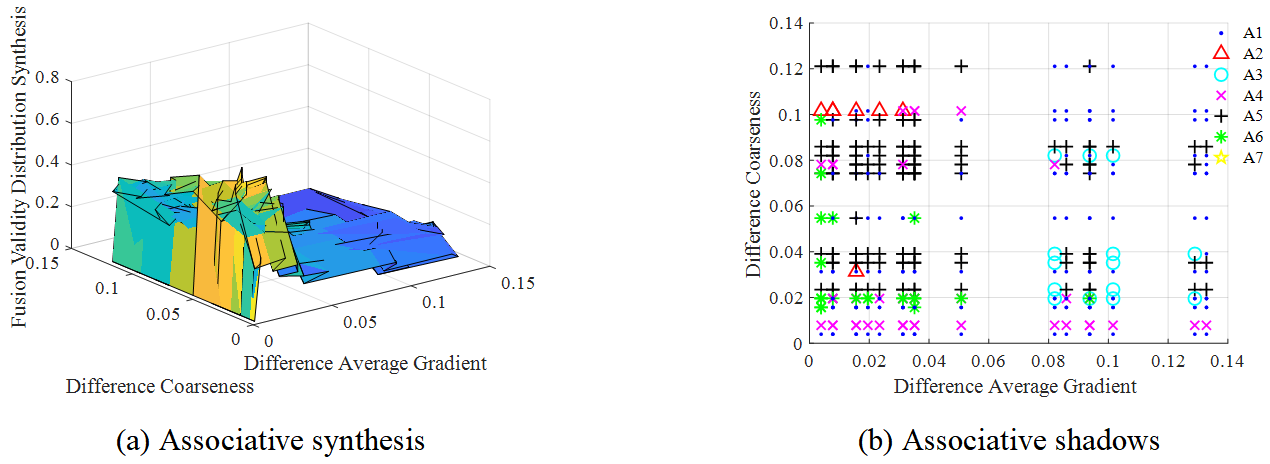
Taking the high-level variables as an example, Figure 6 shows the fusion effectiveness distribution correlation synthesis results of the three main difference features (GM, AG and CA) in the third frame. It is also obvious from Figure 6 that when the weight values of the difference features are equal, the fusion effectiveness points of different high-level variables are relatively densely distributed. That is, the effective information of image fusion is mainly distributed in the part of the associated drop shadow map with smaller comprehensive weight value of features. Table 6 shows the fusion score index values of different algorithms in the three association results, and from the index and size of the last row, it can be concluded that the optimal mimicry high-level variable selected in the first frame is . Figure 7 show the feature correlation synthesis and feature correlation shadow results of the three main difference features (AG, EI and CA) in the fifth frame. Based on this, the fusion score index and of various high-level variables are calculated, as detailed in Table 7. is selected as the optimal high-level variable to realize mimic fusion. Figure 8 shows the feature association shadow map of frame 19. Since there are only two main difference features in frame 19: AG and CA, there is only one association mode. Combining the results in Table 8 and Figure 8, it is obvious that high-level variable is superior to other variables and has better fusion performance, as well as the operation of low-level variables and grassroots variables.
In order to verify the rationality and effectiveness of the proposed method, we compare it with some classical fusion algorithms, and the parameter Settings of the fusion algorithm are set according to the reference [35]. At the same time, because the subjective evaluation is easily affected by the individual psychological factors and mental state of the evaluators, there is a certain degree of subjective initiative. Seven objective evaluation indicators [36, 37, 38] are used to evaluate the fusion results of various aspects of the algorithm. These include,, mutual information (MI), VIFF and Spatial frequency (RCF). The higher the index value, the better the fusion performance. In the experiments, red bold and black bold are used to highlight the optimal and suboptimal values. The experiment platform of this paper is Intel (R) Core (TM) i5-5200U operating system of Windows 11.
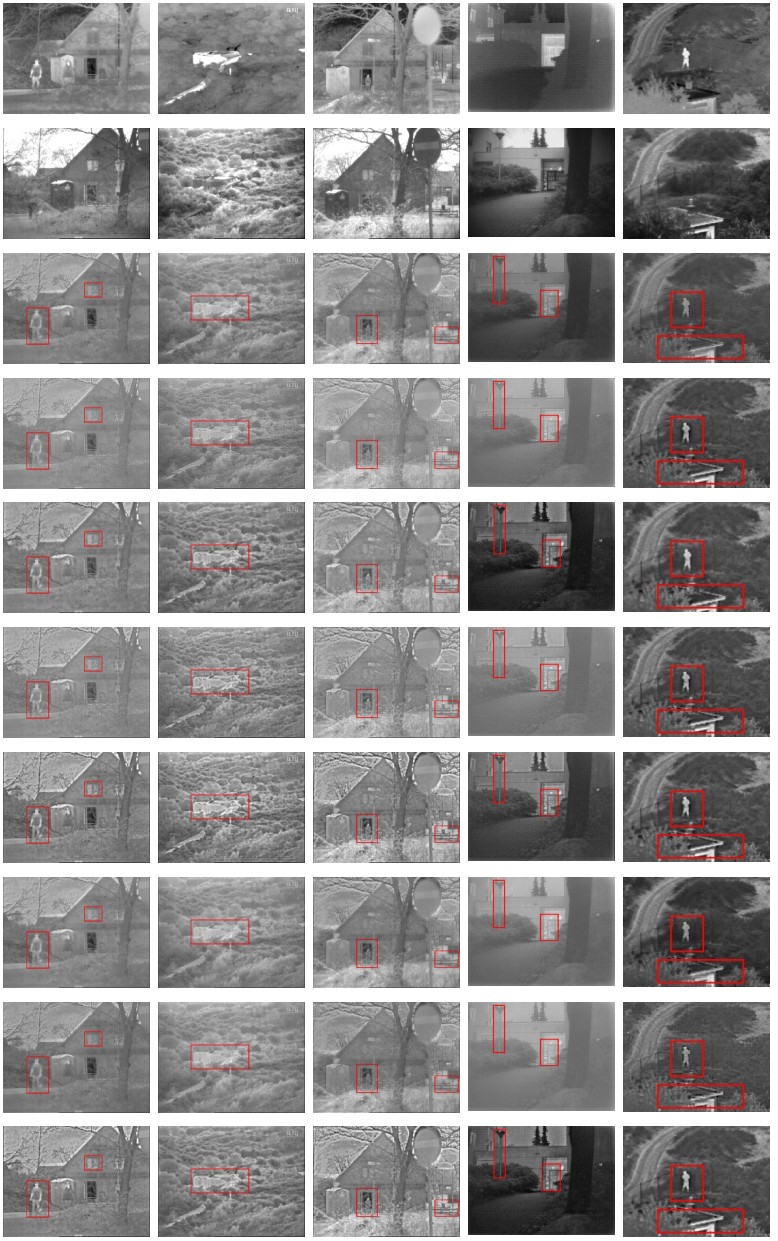
Figure 9 and Figure 10 show the partial fusion results of OTCBVS and TNO datasets respectively. Subjectively, a single fusion algorithm cannot maintain good fusion performance on all data sets. With the change of scene content, the brightness of pedestrians, the edge of buildings and the contour of trees will randomly lose information. On the other hand, the proposed method can better retain the target brightness and detail information, showing stronger intensity distribution, and more realistic and clear texture on moving objects. In the qualitative evaluation of the results, the proposed method has obvious advantages in retaining the details of infrared targets and visible light. Table 9 and Table 10 show the objective quantitative analysis results of OTCBVS and TNO datasets, respectively. In Table 9, the proposed method achieves the best values in MI, VIFF and RCF, and is second only to NSST and CVT in and . In Table 10, the proposed method achieves the best values in terms of , and RCF, which is second only to NSST in . It shows that the proposed method contains rich texture information and salient information in the fused image, retains more useful feature information in the source image pair, and has better fusion performance than other methods, which is consistent with the above subjective qualitative evaluation. From Table 11, it is obvious that the proposed method also meets the real-time fusion requirements in terms of time efficiency.
In this paper, we propose a mimic fusion algorithm for dual channel video based on possibility distribution synthesis theory, which is inspired by the multi-mimic idea of mimic octopus. Ours method establishes the corresponding set-value relationship between the correlation synthesis distribution of different features and the mimic variables, solves the problem that the existing fusion model cannot dynamically adjust the fusion strategy according to the correlation between the multiple attributes of different features in the video frame and the mimic variables, so as to ensure the full play of the fusion performance. The fusion results of OTCBVS and TNO datasets show that the proposed method retains the typical infrared target and visible structure details as a whole, and the fusion performance is significantly better than other single fusion methods.
 Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/