





Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Recently, the group target tracking (GTT) problem has become increasingly important and drawn great attention, which is an integral part of many applications in different fields, including battlefield surveillance [1], traffic control [2], robotics [3], ecology [4], etc. When compared to multi-target tracking groups not only suffers the difficulties such as missed detections, clutter, measurement origin uncertainty [5, 6], but also encounters the group structure uncertainty caused by group merging or splitting [7], which result in more complex issues related to data association, filtering, and computation.
Benefiting from the rapid development in communication and sensing technologies, the sensor network consisting of multiple interconnected sensors with sensing, communication and processing capabilities provides a desirable platform for the challenging target tracking applications, since the network system provides more information in time and space and makes it possible to overcome the lack of target observability from individual sensors with limited FoVs. In particular, distributed sensor network (DSN) has aroused tremendous interest as a result of its attractive merits such as scalability, flexibility, and robustness to faulty sensors. The optimal fusion rule is given in [8], while the computational difficulty of the common information among sensors limits its use, promoting the development of robust suboptimal fusion rules. Consensus provides a powerful tool for the distributed computation over networks, which aims to achieve the global fusion over the DSN by iterating local fusion steps among neighboring sensors. From a probability density perspective, consensus-based distributed fusion is actually an iterative calculation of the local Kullback-Leibler average (KLA) of the state probability density functions (pdfs) among neighboring sensors [9]. The KLA fusion rule [9] is also known as the generalized covariance intersection (GCI) [10, 11] or the exponential mixture density (EMD) [12, 13], belonging to the type of geometric average fusion of local pdfs. Furthermore, some studies focus on another type of arithmetic average fusion can refer to [14, 15]. Regarding the two fusion types, geometric average fusion is more sensitive to missed detections, whereas arithmetic average fusion is more sensitive to clutter [16]. Based on the robust fusion rule, a variety of distributed MTT methods have been investigated, e.g., probability hypothesis density (PHD) with EMD [13], cardinalized PHD with KLA [17], Labeled multi-Bernoulli with GCI [18], etc. Most of the aforementioned studies are presented without FoV limitations, while the conventional KLA fusion rule performs poorly when sensors in the network have limited and different FoVs [19]. To overcome this issue, some improvement methods are proposed [20, 21].
Recently, a powerful BP method has attracted substantial attention in the target tracking community[22]. The BP method can efficiently compute the approximations of the marginal posterior pdfs or probability mass functions (pmfs) for the random variables of interest, providing a scalable solution to the challenging probabilistic data association problem in MTT [23]. Based on the BP scheme, various scalable target tracking algorithms have been proposed for MTT from different perspectives, e.g., scalable MTT methods for tracking unknown number of targets [24, 23], maneuvering MTT [25, 26], simultaneous cooperative self-localization and MTT [27], etc. Recently, a variant of the LMB-GCI method for DMTT, which does not have FoV limitations, has been proposed by integrating BP to address soft (i.e., probabilistic) label association [28]. This approach demonstrates better performance compared to those using a hard label association scheme. Additionally, other BP-based algorithms for extended target tracking can be found in [29] and [30]. In the context of GTT, a group expectation maximization BP method has been proposed for tracking coordinated group targets [31]. To deal with group targets and ungrouped targets seamlessly, a scalable group target belief propagation (GTBP) method is proposed [32]. Given its strengths in estimation accuracy, computational complexity, and implementation flexibility [24], BP could prove to be a highly effective tool for addressing the challenges in DGTT.
In this paper, we consider the DGTT problem under sensors with limited and different FoVs, and our main contributions are outlined below:
We present a consensus-based distributed GTBP algorithm (DGTBP) for DSN. To address the target identity inconsistency among local sensors due to varying FoVs, we incorporate the undetected targets inside the FoV and new targets outside the FoV for track association. We then efficiently compute the marginal track association probabilities using BP, which are utilized for the consensus fusion in a probabilistic manner.
We clarify the computational complexity and scalability of DGTBP. It exhibits computational scalability that scales linearly in the numbers of group partitions, local measurements and neighboring sensors, while scaling quadratically in the number of targets. Numerical results verify the effectiveness and scalability of DGTBP.
The remainder of this paper is outlined as follows. Section 2 introduces the problem background and methodology. Section 3 presents the proposed consensus-based DGTT method, followed by a particle-based algorithm implementation given in Section 4. The numerical experiments and comparison results are shown in Section 5. To the end, we conclude this paper in Section 6.
This paper considers the GTT problem in a DSN, where the sensors have limited and different FoVs. Generally, there is no fusion center in the DSN, and each sensor is restricted to processing local data and exchanging information with its neighboring sensors. For ease of representation, the DSN is described by a directed graph , where and are the set of nodes and the set of edges between nodes, representing sensors and sensor connections, respectively. Here, if and only if sensor can receive information from sensor . For each sensor , we denote as the set of its neighboring sensors, i.e., these sensors in the network that may transmit information to sensor . According to the definition, belongs to for any , and thus for any . The FoV of sensor is denoted by .
Consensus algorithms provide a powerful tool for distributed averaging, which aim to reach a consensus over the DSN by iteratively performing the local fusion of each sensor among its neighboring sensors. Suppose that at each sensor of the DSN, a pdf representing the local information is available, where is a random vector of interest. The weighted KLA pdf among these local pdfs is defined by [9]:
where the weights satisfying and , and is the Kullback-Leibler Divergence between the pdfs and ,
Further, the KLA pdf defined in (1) is given by
which requires all local pdfs . From a distributed way, the following consensus iteration updates the local average of each sensor by fusing the local information of its own and the received information from its neighboring sensors.
where are suitable non-negative weights satisfying for , denotes the number of iterations, and the iteration is initialized by setting .
At time , each potential target (PT) of a local sensor is either a legacy PT (i.e., a PT survived from time to time ) or a new PT (i.e., a newly detected target at time ). That is, the PTs can be divided into two categories at each time step, namely the legacy PTs and the new PTs. Let be the state vector of the legacy PT at time , consisting of the target position and possibly further parameters (e.g., velocity and acceleration), where and is the number of the legacy PTs at time . The detections of the legacy PTs are modeled by the binary existence variables , i.e., exists at time if and only if . We denote and as the joint state vector and existence vector of the legacy PTs at time , respectively. Let denotes the indicator function that if is inside the FoV of sensor and otherwise .
Assume that at time , sensor receives measurements and the joint measurement vector is denoted as . To incorporate the newly detected targets at time , new PT states , are introduced, where each corresponds to the measurement . The detections of the new PTs are also modeled by the binary existence variables , i.e., a measurement is generated by a new PT if and only if . We denote and as the joint state vector and existence vector of the new PTs, respectively. Notably, the new PTs at time become the legacy PTs when receiving new measurements at time , which means that the number of the legacy PTs at time is updated by Since the number of PTs would increase with the accumulation of sensor measurements, we consider at most PTs at any time for sensor and perform a pruning step at each time step to remove unlikely PTs.
In GTT, the group structure describes the connection between targets, which is a premise of the modeling of the evolution of targets. In this paper, we make the convention that at any time , only the group structure of the confirmed legacy PTs (that have been declared to exist at the current time) is considered, and each confirmed legacy PT can be partitioned to only one group in a possible group structure. Concretely, we use a group partition vector to denote the group structure of all legacy PTs at time , where the element if is confirmed and otherwise. Furthermore, the group structure of the new PTs at time is denoted by the vector with zero entries, and we denote the number of groups partitioned by as .
The unknown association between legacy PTs and measurements at time can be described by a target-oriented association vector , where the element if the PT generates the measurement at time and otherwise. Following [22, 24, 23], we also use a measurement-oriented association vector , where the element if the measurement originates from the PT and otherwise. The expression of is redundant with , that is, one of the two association vectors is determined and the other is determined as well.
We denote the joint vectors of all the PT state, the existence variable and the group partition at time as , and , respectively. Let , and be the sets of all possible , and , respectively. For notational convenience, we define the augmented state vectors for the legacy PTs and the new PTs as and , respectively. The joint augmented state vector at time is given by .
The factor graph (FG) is a graphical model to describe the factorization of pdfs [22]. We denote and as the index sets of the variable node and the factor node in a FG with respect to the random variable and the factor , respectively. In a FG, the variable node and the factor node are connected by an edge if and only if is an argument of . Let and denote the sets of the factor nodes connected with the variable node and the variable nodes connected with the factor node , respectively. Consider that a posterior pdf can be factorized as [22]
where and are the stacked vectors of and , respectively. According to the factorization, BP provides an efficient way to approximate the marginal distributions, which computes the message of each node in the FG and passes the node's message to the connected nodes [22]. Specifically, if the variable node is connected with the factor node , we denote the message passed from the variable node to the factor node and the message passed from the factor node to the variable node as and , respectively, which are computed by
where the symbol "" indicates the flow of the message, is short for , and is denoted as the integration over except . Eventually, for each variable node , a belief is obtained by the product of all the incoming messages with the normalizing constraint, which provides an approximation of the marginal pdf .
Let , , , and denote the stacked vectors of joint augmented state, group partition, target-oriented association, measurement-oriented association and measurements up to time , respectively. Herein, the subscript representing the sensor node is omitted for notational convenience when there is no confusion. Following some regular assumptions [23, 32], the joint posterior pdf is written as
with
where the calculation of is provided in [32], and the augmented state and group structure transition pdf can be written as
Let denote the index set of PTs included in the group in the group partition and use to denote the joint augmented state of the PTs . Then, we have
where is given by
and the pdf , describing the augmented state transition density of the group in the group partition can be factorized as
where is the index set of survival PTs in the group , is the survival probability, and represents the joint state of the group . Here, the group transition density describes the evolution of the group , and there are several studies on group dynamics models that can be referenced [4, 33, 34, 35]. For the group structure transition pmf , a pseudo group structure transition pmf is constructed as follows by introducing a scoring function [32, 35],
By using BP, the scalable GTBP method is developed, providing an approximation of the posterior pdf . For further implementation details, please refer to [32].
The KLA fusion rule provides an efficient and robust way for distributed fusion over the network. However, when executing KLA fusion, there exists a premise that the targets from different local sensors are correctly matched. For the DGTT problem, the fusion may be problematic for the following reasons:
In practice, sensors may have different sensing capabilities and FoVs, leading to the difference in the numbers of detected targets.
Moreover, since each sensor in the network processes its own data locally, the identities of the same target may be different at these sensors.
Particularly, GTT suffers more difficulties in data association, filtering and computation than MTT, and these challenges may be further complicated in the DSN.
In this paper, we consider solving these problems within the BP framework, where the flowchart of the proposed method is shown in Figure 1. Specifically, for each sensor in the DSN, the GTBP method is used to track the group targets locally and then obtains the local posterior pdf [32]. After exchanging the information between sensors and their neighbors, the track association problem is formulated by a FG and we obtain the track association probabilities by running BP. Finally, the KLA fusion is performed iteratively at each sensor according to the received local posterior pdfs from its neighbors and corresponding track association probabilities. Notably, our proposed method for DGTT using limited FoV sensors does not rely on any specific local tracker, other GTT methods can also be used. Details of the proposed DGTT method are presented in the following subsections.
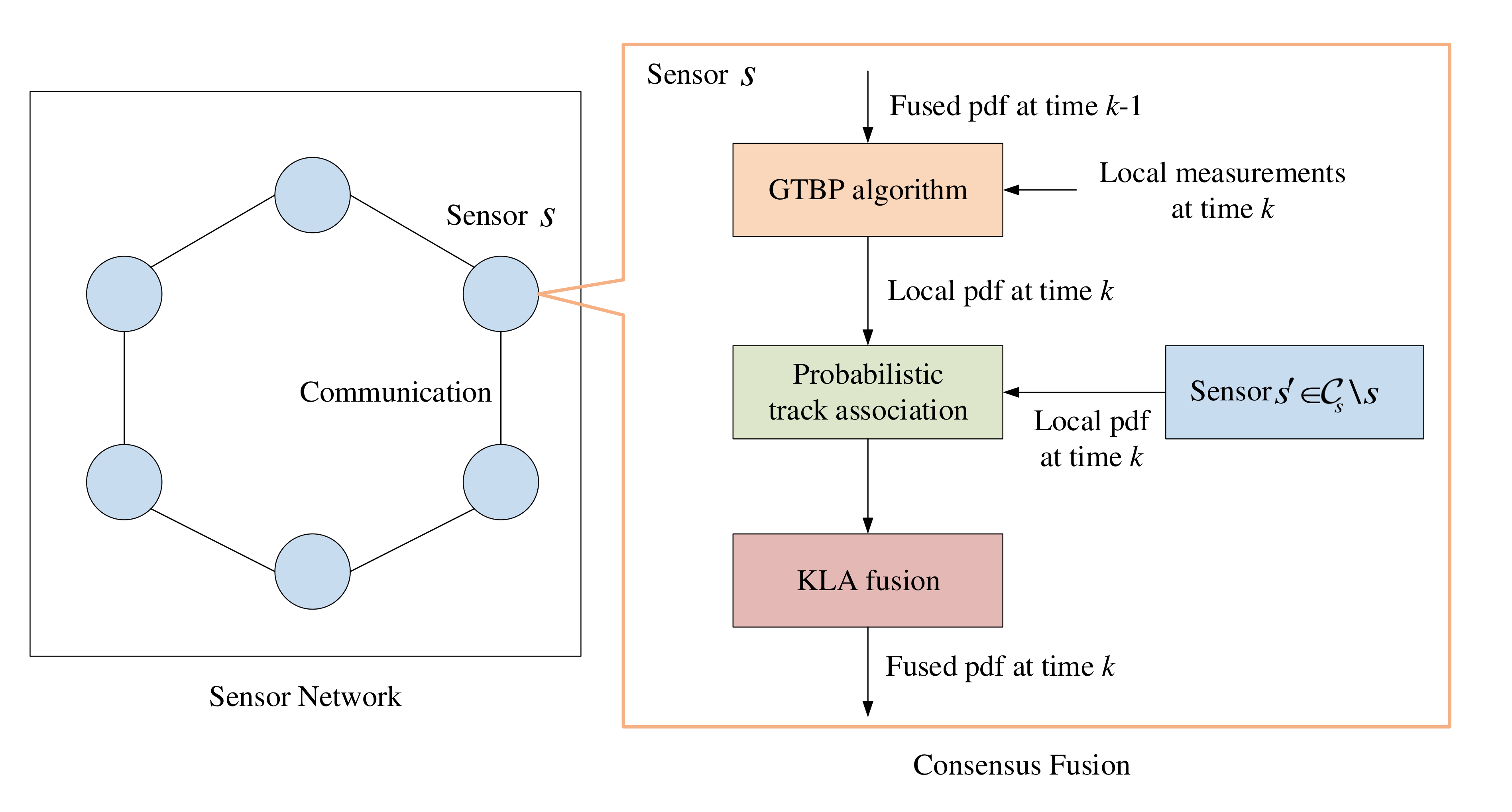
For simplicity, let us consider the track association between two sensors and the consensus fusion at sensor 1 (reference sensor), which receives the local pdfs from sensor 2 (neighboring sensor). Note that under the setting of limited FoVs of sensors, the KLA fusion rule cannot preserve the information difference and tends to discard the targets located outside the overlapping FoV [16]. To address this issue, we consider dynamically introducing the undetected targets inside the FoV (UTIF) and new targets outside of the FoV (NTOF) of the reference sensor. Specifically, subsections 3.2.1-3.2.2 propose the track association and consensus fusion between the targets inside the FoV of the reference sensor, and subsection 3.2.3 presents the consensus fusion for targets outside the FoV of the reference sensor.
In this subsection, we mainly consider the fusion between the targets inside the FoV of sensor 1. According to the FoV of sensor 1, the targets of its own and received from sensor 2 can be divided into two disjoint sets (i.e., inside or outside the FoV of sensor 1), respectively. We denote as the index sets of targets at sensor that are inside the FoV of sensor 1, and the corresponding local posterior pdfs are denoted as , where is the corresponding number of targets. Similar to the introduction of new PTs at local sensors, the UTIF at sensor 1 are modeled by introducing new PTs (that may be available from sensor 2), i.e., . Let denote the joint augmented state at sensor 1 to be fused, and denote the corresponding index set of targets, where . Herein, the target indices are ordered, i.e., corresponds to the original target (at sensor 1) for , or the introduced new PT for .
The track association between sensors 1 and 2 is described by an association vector for sensor 1, where the entries are defined as
and for the introduced new PT , if the target indicated at sensor 2 is the UTIF at sensor 1. Otherwise, , which means the target does not exist. Analogously, it is assumed that a PT at sensor 1 can be associated with at most one PT at sensor 2, and vice versa. We denote and as the set of all possible and its subset satisfying the constraint, respectively. Let be the reordered vector of according to . Note that is the dummy state introduced for the indices with , and thus has matched dimension with . Then, the KLA fusion rule with given for sensors 1 and 2 can be rewritten as
where , the pdf is short for of sensor , and the coefficient is given by
where . Note that , and if , we abbreviate and as and , respectively. Here, the pdf represents the dummy pdf when . We denote as
with
and can be rewritten as
Thus, Equation (1) can be rewritten as
Notably, the coefficient can be used for measuring of similarity between the local densities to be fused. Under given , the larger is the coefficient among the local densities, the more the corresponding KLA fusion is coherent with the Principle of Minimum Discrimination of Information. Thus, given local densities to be fused, different track association vectors result in different coefficients, and a larger indicates that the corresponding track association vector is more likely. Based on this motivation, we consider the track association problem in a probabilistic way, where the track association vector is random and the pmf of is defined as
where . Consequently, the fused posterior pdf is obtained by
where is the conditional fused posterior pdf. The second equality uses the definition that if . Similar to [28], we use the product of the marginal pmfs of to approximate the pmf , i.e.,
where denotes the marginal pmf of the track association vector . Thus, the fused posterior pdf is approximated by
with , and the second equality uses the fact that
Since the knowledge of UTIF is unknown at sensor 1, we construct the prior pdf of UTIF as follows. Let denote the index set of targets at sensor 2 that are UTIF of sensor 1, the pdf is given by the following Gaussian mixture model
where is the expectation operator, and is a prior covariance. The existence probability of UTIF is a parameter, which may be set to a value related to the detection ability of sensor 1 and the existence probability of the corresponding PT received from sensor 2. Furthermore, if the new PT at sensor 1 is matched with a dummy PT at sensor 2 (i.e., ), then it does not exist and is represented by a dummy pdf .
To perform the probabilistic fusion rule (7), it is necessary to calculate marginal pmfs of . In this subsection, we obtain the approximate marginal pmfs of by running BP on the FG devised for track association. According to (5), we have
where if and otherwise. Similarly, we introduce the association vector for sensor 2, where the entries . Herein, we make convention that means that the target indicated by at sensor 2 is the UTIF at sensor 1, i.e., . The association vector for sensor 2 is redundant with for sensor 1, that is, one of the two association vectors is determined and the other is determined as well. By introducing , can be stretched and equivalently expressed as
where
Thus, the pmf in (9) can be rewritten as
A FG representation of the factorization (10) is shown in Figure 2, which enables the use of efficient BP scheme for the track association problem.
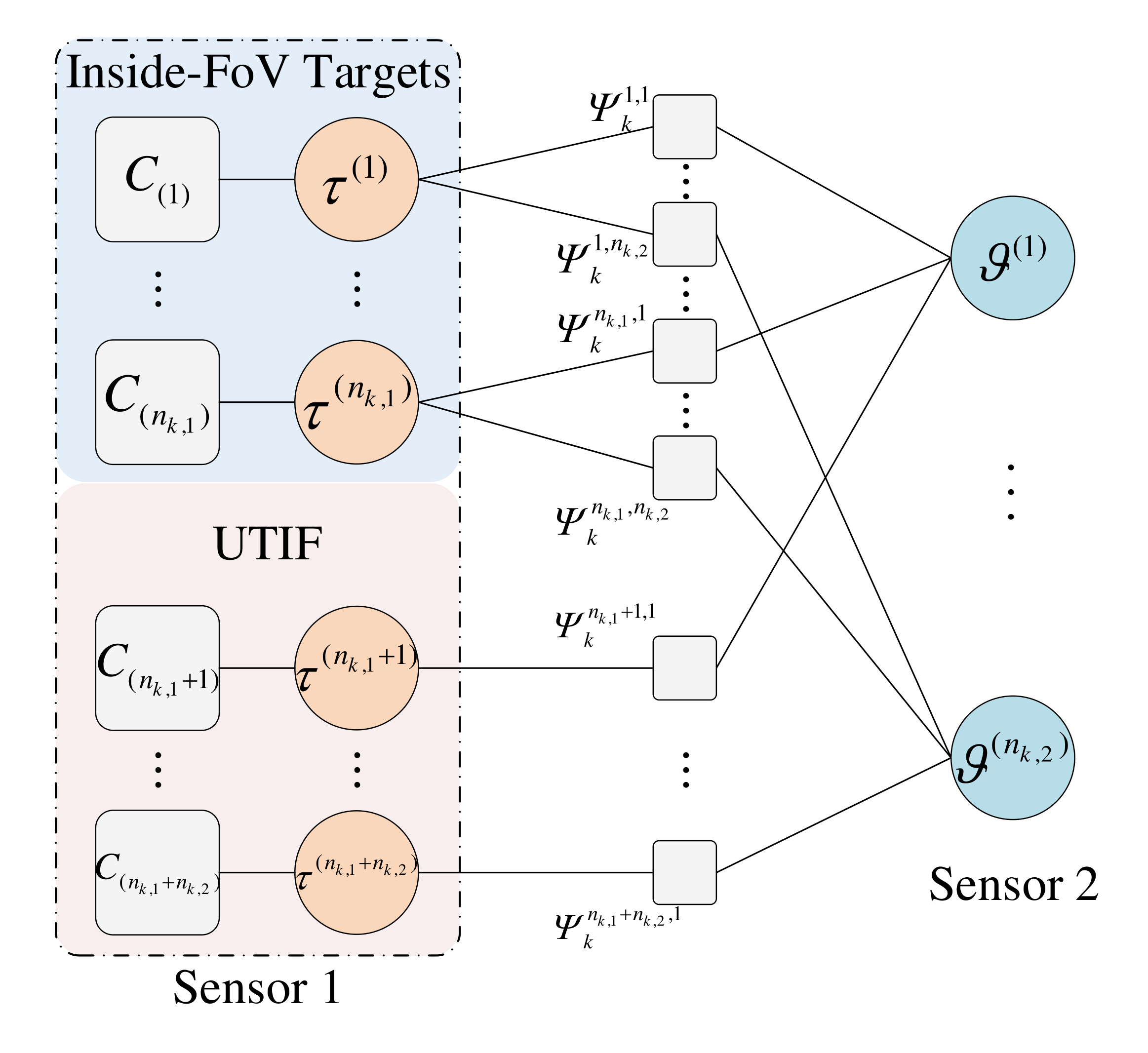
Specifically, once the incoming messages to the track association part have been calculated, the iterative message calculation between , and are performed. In the iteration, the messages , and are iteratively updated, where the superscript denotes the number of iterations. Hereafter, we abbreviate them as and for notational convenience. The calculation of for and are given by
and with for . Similarly, the messages for and are computed by
and with for . The iterative loop of (11)-(12) is initialized by setting
The implementation and termination of the iteration (11)-(12) is analogous to the iteration data association at local sensors [32]. We denote the number of iterations when meeting the stopping criteria as , then the beliefs approximating the marginal pmfs of are obtained as
with for and , and
for . We summarize the BP-based probabilistic track association algorithm as follows:
Let denote the index sets of targets at sensor , which are outside the FoV of the reference sensor 1. We present the fusion scheme for targets and that are outside the FoV of the reference sensor 1 as follows.
Step 1: For each target (maintained at sensor 1) that received from sensor 2 at the previous time step, update it by corresponding new information received from sensor 2 at the current time step.
Step 2: For the rest of targets (in ) at sensor 1, perform the track association and consensus fusion with the rest of targets (in ) received from sensor 2 (as described in subsections 3.2.1-3.2.2).
Step 3: For the unmatched targets (in ) received from sensor 2, maintain them at sensor 1.
As presented before, Equation (7) provides the fusion rule for two sensors in a probabilistic way, where the track association problem can be efficiently solved by running BP on the devised FG. While in practical distributed fusion system with multi-sensor, it is often that more than two local posterior pdfs to be fused and a common method is to perform the pairwise fusion. Thus, the fusion of sensors can be implemented by sequentially using the BP-based track association method and the pairwise fusion (7) times. Specific procedure is summarized in Algorithm 2.
for do
Divide the targets at sensors and into two disjoint sets according to the FoV of sensor , respectively;
For the targets at sensors and that are inside the FoV of sensor , compute the marginal track association probabilities by Algorithm 1 using local pdfs (at sensors and ), and compute the fused pdf at sensor via (7);
For the targets at sensors and that are outside the FoV of sensor , performing the consensus fusion scheme as described in subsection 3.2.3;
Substitute the fused pdf for the local pdf at sensor ;
end for
return the fused pdf at sensor ;
Thus, the main steps of the overall DGTBP algorithm is concluded as follows:
GTBP for local sensors: Each local sensor receives the local measurements at time , and runs GTBP [32] to obtain the local posterior pdf;
Iterative consensus fusion for each local sensor: After the processing of local sensors, consensus iterations are performed over the DSN. In each iteration, each sensor receives the local pdfs from its neighboring sensors . After the information exchange, each sensor performs the consensus-based fusion via Algorithm 2. Note that the original local posterior pdf at each sensor is replaced by corresponding fused pdf after running Algorithm 2, which is used in the next consensus iteration.
State estimation and pruning: After performing consensus iterations, the state estimations and existence probabilities are obtained for each sensor through the corresponding fused pdf. Finally, a pruning step is performed at each local sensor to remove unlikely PTs based on the existence probabilities.
By exploiting the scalability of BP, we propose a DGTBP method. For ease of representation, we analyze the computational complexity of DGTBP under the assumption of a fixed number of BP iterations, and we use the maximum possible number of PTs appearing in the DSN to analyze how the computational complexity scales in the number of PTs. In fact, this upper bound will not be reached in most cases due to the FoV limitations. Specifically, for each sensor , the overall computational complexity mainly contains the following two parts:
The computational complexity of GTBP: As shown in [32], the prediction of the group structure requires to be computed times, that is, its computational complexity scales as . Furthermore, the computational complexity of the measurement evaluation and iterative data steps association scales as .
The computational complexity of consensus fusion: Each sensor requires to perform times of the pairwise consensus fusion based on Algorithm 2. Thus, the computational complexity of performing consensus fusion at sensor scales as . Since the maximum possible number of PTs is , the computational complexity of (4), (11), and (12) scales as in each pairwise fusion.
Thus, the overall computational complexity of DGTBP at each sensor scales linearly in the numbers of group partitions, local measurements, and its neighboring sensors, and quadratically in the number of PTs.
For the suitability of general nonlinear and non-Gaussian dynamic system, we consider the Monte Carlo (MC) implementation of the proposed DGTBP method in this section. Due to limited space, we mainly present the details of the particle-based probabilistic track association and consensus fusion (i.e., step 3 in Algorithm 2), where the particle implementation of -best GTBP for local sensors is provided in [32].
Let denote the particle representation of the belief approximating the local posterior pdf , , where is the number of particles. Note that the summation provides an approximation of the marginal posterior pmf . Before performing the consensus fusion (7), the beliefs and the pdfs are required to be computed. However, since each sensor has its own particle-based implementation with its own support, the particle representation of the fused pdf cannot be directly computed. A natural and common way is to use the union of the particles as the support, and adopt the kernel density estimation (KDE) method[13]. A KDE approximation of is given by
where , is a Kernel function, is the bandwidth, and is the volume of which depends also on . The use of a Gaussian KDE and corresponding choice of the bandwidth can be seen in [13].
Let denote the union of the particles11 to represent in (3), which can be seen as the samples drawn from the following the mixture important sampling density,
and the weights for particles are given by
By using the KDE approximation (1), the weights can be approximated computed as follows:
where is the normalization constant that provides an approximation of the integral of ,
The particles with weights provide a particle representation of . Thus, a particle-based approximation of in (4) is given by
Substituting for in (11) and (13), and then the track association between sensors are implemented by running (11)-(12) iteratively. After the iteration terminated, the beliefs approximating the marginal pmfs of are obtained by (14)-(15). Let denote the union of the sets of particles with . Therefore, the fused posterior pdf in (7) can be represented by the particles , where each particle equals to one of the particle belonging to , and the corresponding weight is given as follows:
Next, a resampling step is performed to reduce the particles to uniformly weighted particles at sensor 1, which are used for the next time of the pairwise fusion.
We simulate three GTT scenarios using different DSNs of increasing complexity to verify the performance of the proposed method. Specifically,
Scenario 1 simulates two sensor nodes with limited FoVs, merging and splitting group targets, which is applied to validate the capability of handling group splitting and merging of the proposed method.
Scenario 2 simulates multiple sensor nodes with limited FoVs, multiple group targets, and ungrouped targets, which is used for evaluating the tracking performance of the proposed method.
Scenario 3 simulates a large number of sensors with limited FoVs and is used to validate the scalability of DGTBP.
These scenarios are simulated in the 2-D case with 100 time steps and the time sampling interval s, where the individual targets are described by the state vectors of planar position and velocity. The numbers of group targets and ungrouped targets are time-varying, and the ground truths are simulated using the constant velocity (CV) model and the coordinate turn (CT) model [5]. The target generates a measurement by sensor if and only if and it is detected by sensor , where is the location of sensor at time and is a zero-mean Gaussian process noise with and m. The clutter pdf is assumed uniform in the FoV of sensor . Furthermore, we employ the same birth pdf constructed by using the measurements at the previous time step [36] for the fair comparison of all tested methods. The Poisson mean numbers of clutter measurements and new PTs for each sensor are set to and in these scenarios, respectively.
We consider the particle-based implementation of DGTBP, which adopts the algorithm paradigm in Figure 1 for networks of sensors with limited FoVs. To verify the performance of DGTBP, we compare it with the distributed BP (DBP) method, which can be obtained by employing the same algorithm paradigm as DGTBP with the BP method [23] substituted for GTBP executing at local sensors. Furthermore, we also consider a centralized GTBP (CGTBP) method, which is a generation of the GTBP method [32] to multi-sensor case by using a sensor-sequential processing summarized in [23] (cf. Section IX-B). The results of BP, GTBP for local sensors are provided as well. Due to the settings of limited FoVs, we adopt the following detection probability at any sensor , where and is the summation of normalized weights of these particles inside . Herein, the coefficient is used to handle the case that targets move across the boundaries of limited FoVs, which makes the detection probability more adaptive. The number of particles (for representing each legacy PT or new PT state), the survival probability, and the thresholds for target declaration and pruning are set to , , , and , respectively. In all simulations, a target is pruned if its existence probability is less than . Since DBP and DGTBP do not require sharing FoV information between sensors, an additional pruning rule is also used for DBP and DGTBP, i.e., a target is pruned if it is not associated with local sensor measurements and other sensors' targets in consecutive time steps. Furthermore, we use the CV model with the process noise for filtering, where m/s2 and
In the iterative data association for local trackers and track association between sensors, the iteration is stopped if the difference in the Frobenius norm of the beliefs is less than in two consecutive iterations or reaches the maximum number 100 of iterations. Furthermore, these methods perform message censoring (described in remark 2) with thresholds 0.3 and 0.1 for the data association at local sensors and track association between sensors, respectively. In the implementation of GTBP, 5-best group partitions are preserved at each time step. For DBP and DGTBP, 3 consensus fusion iterations are performed at each time step22. More specifically, in each fusion iteration, the conversion of particles and Gaussian pdfs mentioned in Remark 3 is applied, and only the approximate pdfs of targets with existence probabilities exceeding the threshold for target declaration are transmitted.
To compare the tracking performance, we use the OSPA distance and the OSPA(2) distance as the performance metrics, which is capable of capturing a variety of tracking errors, including location and cardinality errors, track switching and fragmentation [38, 39]. The cutoff parameter, the order parameters, and the window length are set to , , , and (with uniform weights), respectively.

In scenario 1, we consider tracking an unknown number of group targets with group splitting and merging by using two sensors with limited FoVs. The simulated ground truths, sensor locations, and FoVs are shown in Figure 3. The two sensors are positioned at and with the radius being 2000 m, respectively. Targets 1, 2, and 3 are born at the time step in the FoV of sensor 1 and then merge into one group and traverse the overlapping FoV. Followed by the group splitting, the three targets die at in the FoV of sensor 2. Moreover, the group targets 4 and 5 are born at and die at in the FoV of sensor 1, respectively. Target 6 is born at in the FoV of sensor 2 and dies at in the FoV of sensor 1. The maximum possible number of PTs is set to when using CGTBP, and otherwise . The pruning length threshold is set to in the implementations of DBP and DGTBP.
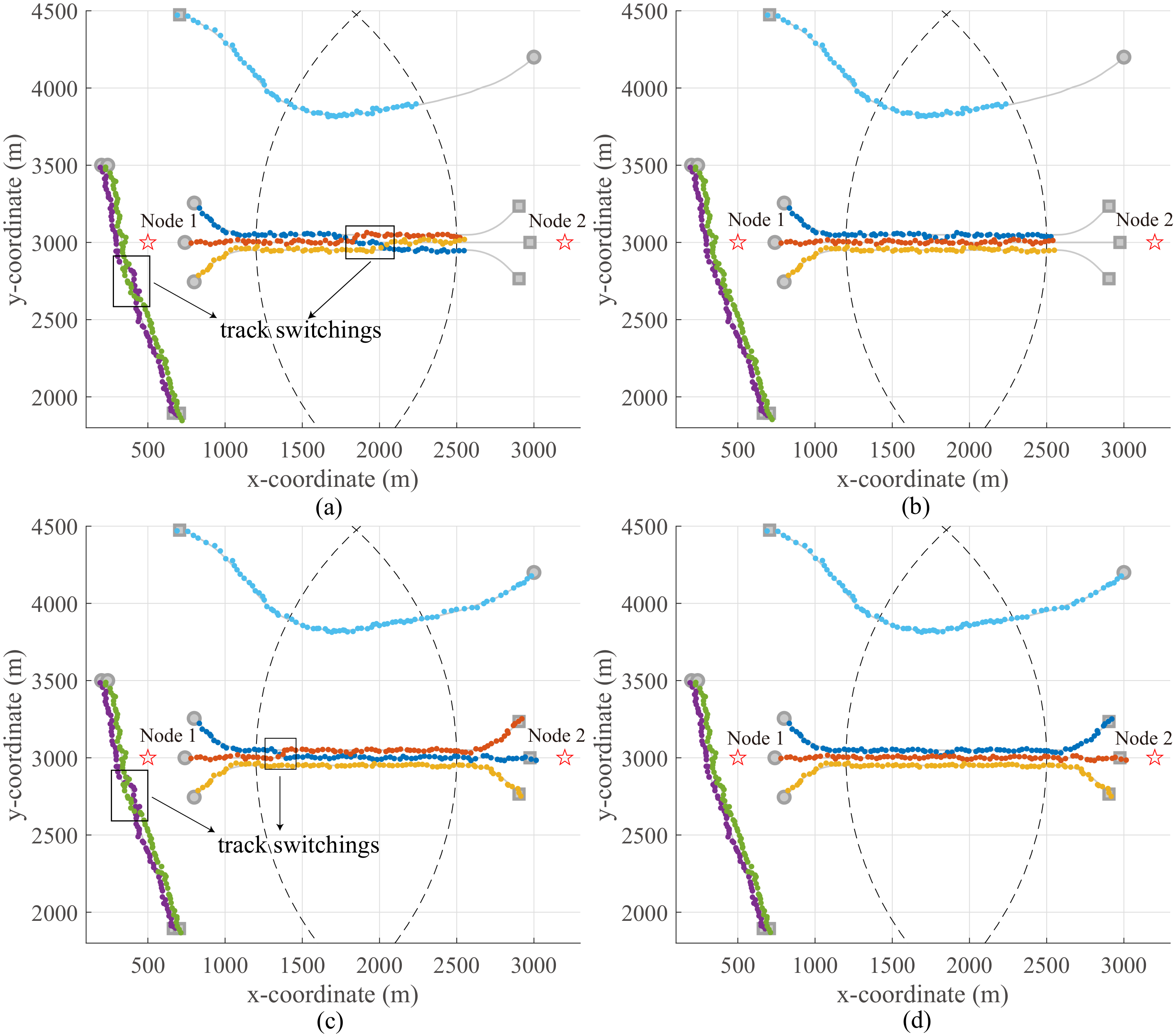
Figures 4(a)-4(d) plot the true trajectories and the estimated trajectories tracked by BP, GTBP, DBP, and DGTBP at sensor 1 of one example run, respectively. As shown in Figures 4(a)-4(b), BP and GTBP only can detect targets in the FoV of sensor 1 due to the limitation of FoV, and GTBP obtains better tracking performance (e.g., fewer track switchings) than BP for the reasons of jointly estimating the group structure uncertainty and enabling flexible modeling of group motions and single-target motions. Figures 4(c)-4(d) show that DBP and DGTBP can successfully detect and track all targets inside and outside the FoV of sensor 1 with the complement information from sensor 2, which significantly improve the tracking performance than BP and GTBP used for a single limited FoV sensor. Simultaneously, benefiting from the merits of GTBP for tracking group targets, DGTBP has fewer track switchings and can handle group splitting and merging more accurately than DBP, thereby obtaining better tracking accuracy, which is further verified in Figure 5.
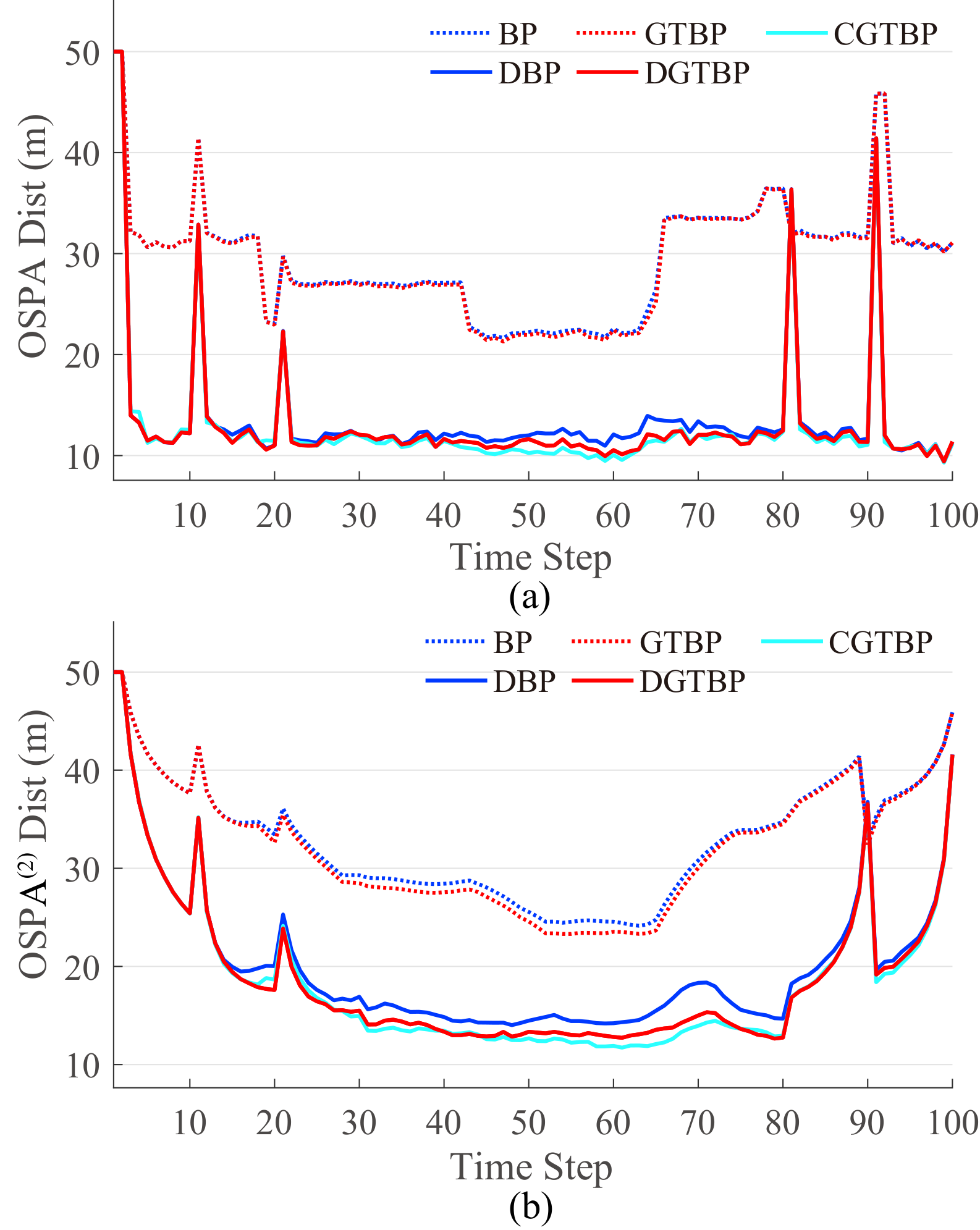
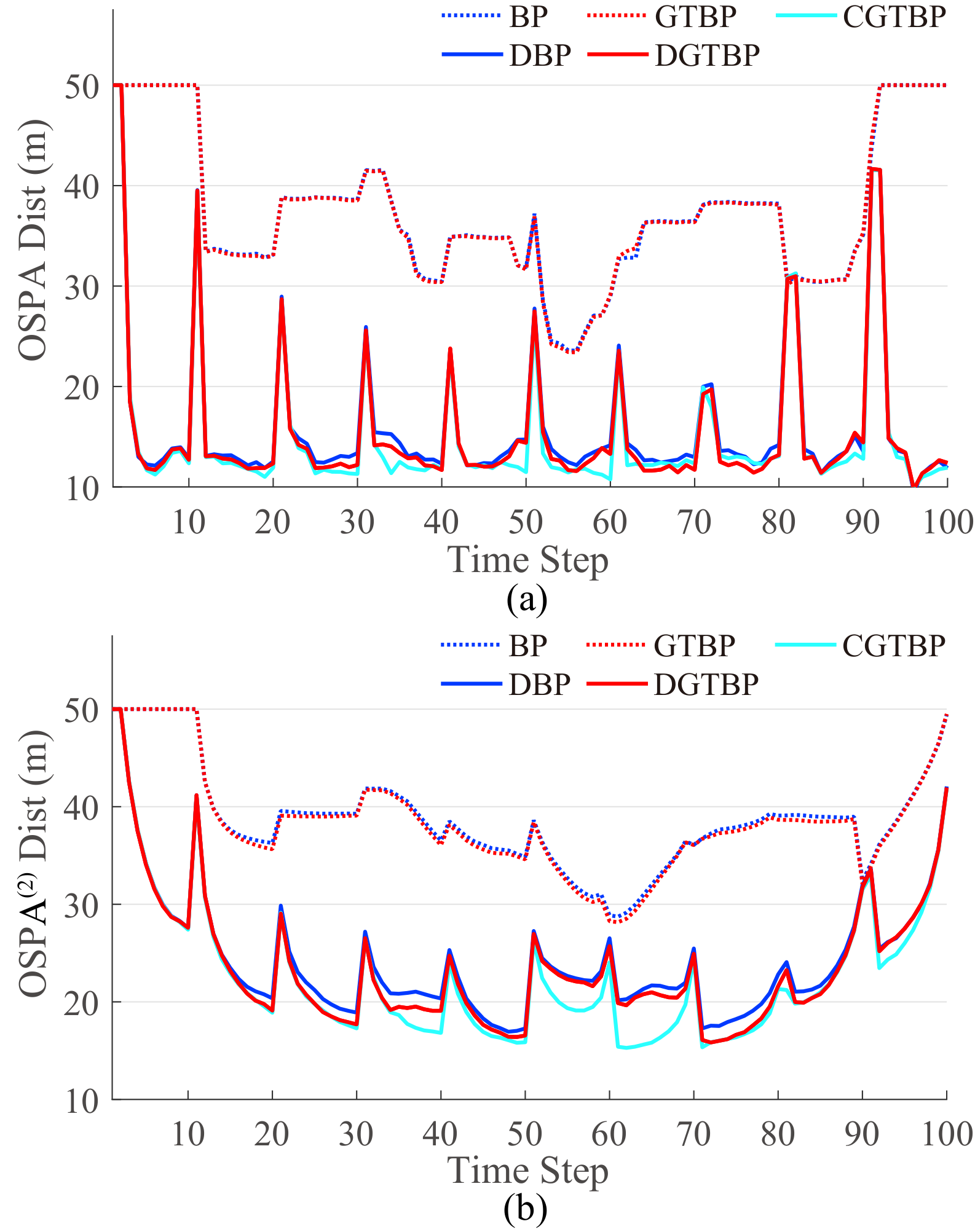
Figures 5(a)-5(b) plot the average OSPA and OSPA(2) distances for scenario 1 over 50 MC runs versus the time step, where the spikes result from the track initiation, termination delays and window effects. The comparison results are consistent with the phenomena shown in Figure 4. More specifically, DGTBP and DBP overcome the limitation of FoVs and further reduce the tracking errors by making full use of the complementary information obtained from sensor 2, and DGTBP obtains better tracking accuracy than DBP. The reasons are the same as those analyzed for Figure 4. Furthermore, the performance of DGTBP is close to that of CGTBP.
Next, we consider a more complex scenario with multi-sensor, multiple group targets and ungrouped targets. The simulated ground truths, sensor locations, and FoVs are shown in Figure 6. A total of 14 targets (including 5 group targets and 3 ungrouped targets) are simulated with various birth and death times. The maximum possible number of PTs is set to when using CGTBP, and otherwise . There are 5 sensors in the network, where sensors 1-4 have a limited FoV with a relative angle of interval and a radius of 2100 m, and sensor 5 is with a relative angle of interval and a radius of 1500 m. In this DSN, sensor 5 can exchange information with the other four sensors. The pruning length threshold is set to in the implementations of DBP and DGTBP.


Figures 7(a)-7(d) plot the true trajectories and the estimated trajectories tracked by BP, GTBP, DBP, and DGTBP at sensor 5 of one example run, respectively. On the whole, the comparison results shown in Figure 7 are similar those shown in Figure 4. Notably, DBP may further intensify the confusion on target identities when performing distributed information fusion for the targets within groups (that located in the overlapping FoV), leading to the performance degradation (see Figures 7(a) and 7(c)). Furthermore, DGTBP can successfully detect and seamlessly track all group targets and ungrouped targets inside or outside the FoV of sensor 5, which further demonstrate the effectiveness of DGTBP.
Figures 8(a)-8(b) plot the average OSPA and OSPA(2) distances for scenario 2 over 50 MC runs versus the time step. The comparison results are consistent with the phenomena shown in Figure 7, which confirm that DGTBP outperforms DBP, BP, and GTBP in terms of the average OSPA and OSPA(2). The reasons are the same as those analyzed for scenario 1. Moreover, the tracking performance of DGTBP is close to that of CGTBP.
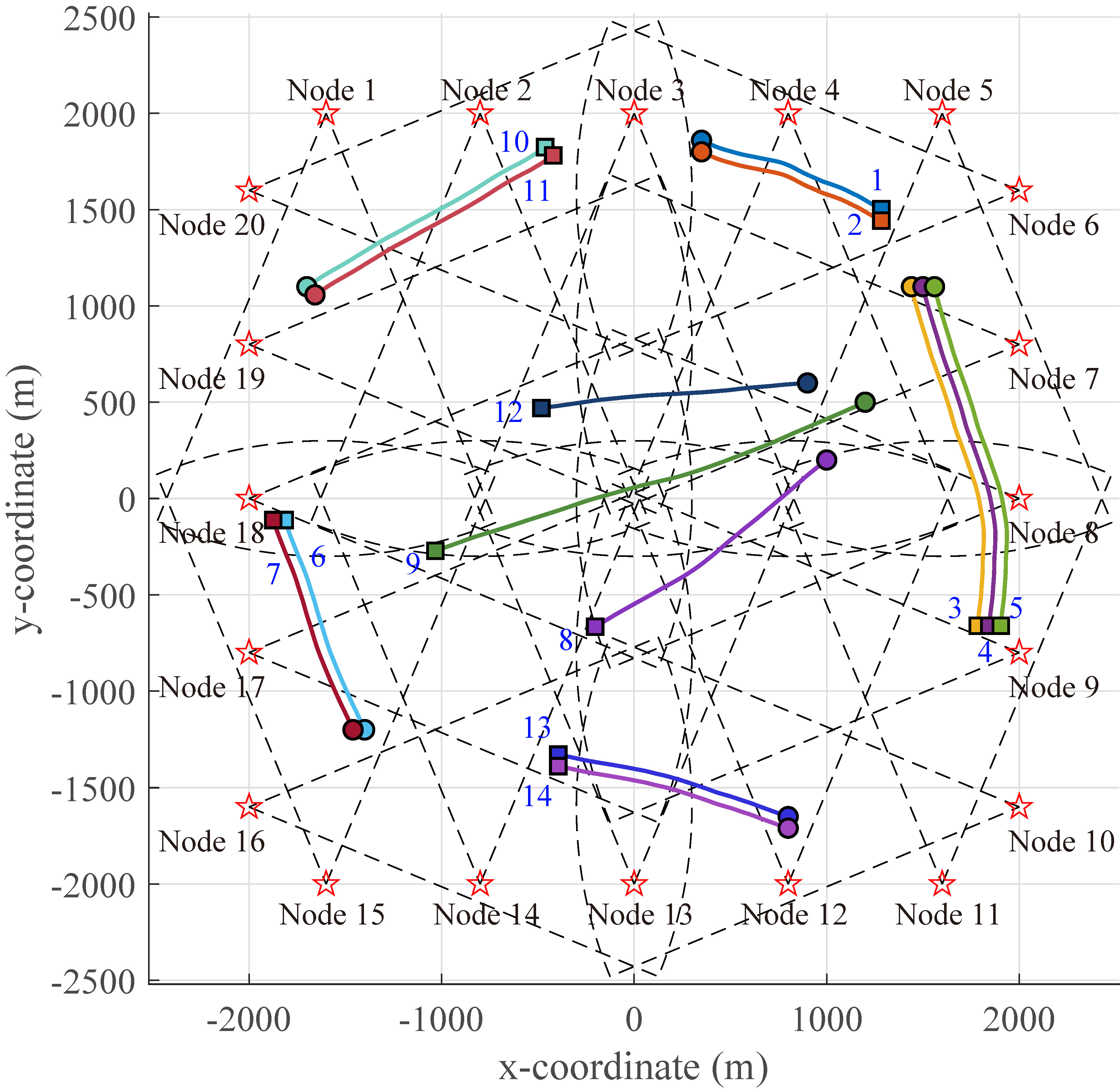
In scenario 3, we investigate how the fusion time scales in the network size to demonstrate the excellent scalability and low complexity of DGTBP. We simulate a DSN with 20 sensors for tracking 14 targets (including multiple groups and ungrouped targets) with different birth and death times, where the maximum possible number of PTs is set to when using CGTBP, and otherwise . The simulated ground truths, sensor locations, and FoVs are shown in Figure 9, where each sensor's FoV is with a relative angle of interval and a radius of 2300 m. Due to higher uncertainty of this scenario, the pruning length threshold is set to in the implementations of DBP and DGTBP.
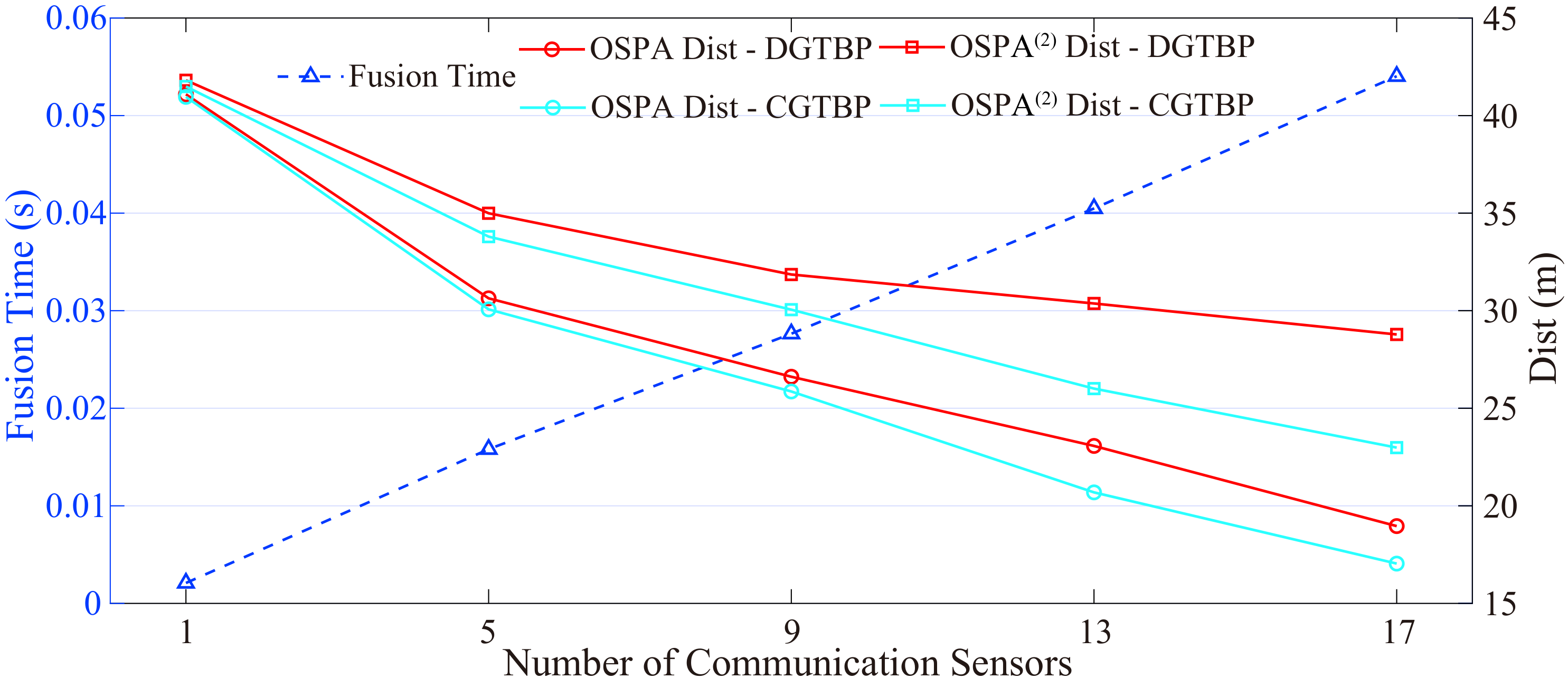
Figure 10 plots the average fusion time per consensus iteration, the average OSPA distance, and the average OSPA(2) distance over 100 time steps and 10 MC runs versus the number of communication sensors at sensor 4 (i.e., the number of sensors exchanging information with sensor 4). The results indicate that the average fusion time per consensus iteration scales linearly in the number of neighboring sensors, which is consistent with the analysis in Section 3.4. Moreover, DGTBP inherits the same scalability as GTBP in the processing of local sensor data, i.e., scaling linearly in the numbers of preserved group partitions and local sensor measurements, and quadratically in the number of targets. Furthermore, with the increase of the number of communication sensors, the OSPA and OSPA(2) errors decrease. The reason is that the use of multi-sensor allows for greater temporal and spatial coverage, and better precision (within the overlapping FoVs) than individual sensors with limited FoVs. As a consequence, DGTBP has excellent scalability and low complexity, which is applicable for the DGTT problem.
This paper focuses on the DGTT problem under sensors with limited FoVs, and propose a scalable DGTBP method. By considering the group structure uncertainty, the proposed method can seamlessly track the group targets and ungrouped targets and accurately capture changes in group structure such as group splitting and merging. To deal with the target identity inconsistency of local sensors caused by different FoVs and distributed architecture, we efficiently solve the track association problem based on the BP scheme and perform the consensus fusion in a probabilistic way. Particularly, DGTBP has excellent scalability and low computational complexity that only scales linearly in the numbers of group partitions, local measurements, and neighboring sensors, and quadratically in the number of PTs. Numerical results for challenging DGTT scenarios demonstrate the effectiveness of DGTBP.
 Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/