
Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Infrared images, formed by capturing thermal radiation, offer strong anti-interference but suffer from low resolution and lack fine details. In contrast, visible images, formed by utilizing light reflected from objects, exhibit high spatial resolution and provide abundant texture details and color information. However, their performance is significantly degraded under low-light or other extremely harsh conditions, thereby compromising target saliency [6, 7]. Consequently, infrared and visible images exhibit inherent complementarity. By fusing these two modalities, the resulting composite image preserves the abundant textural details from the visible image while simultaneously highlighting the salient target information captured by the infrared image. Infrared and visible image fusion technology has demonstrated extensive applicability across diverse domains including military reconnaissance [1], security surveillance [2], video surveillance [3], person re-identification [4] and remote sensing [5].
Image fusion focuses on pixel-level detail information, but rarely integrates target-level semantic information. In contrast, image segmentation focuses on target-level semantic information such as object categories. Image segmentation can provide target-level semantic information for image fusion, helping it better fuse the target area during the fusion process. Therefore, the core task of this study is to utilize leverage the advantages of multi-task learning, using the segmentation task to provide target-level semantic information for the fusion task, thereby guiding the fusion process to preserve and enhance target regions and improve the quality of image fusion. To this end, we focus on solving the problem of "how segmentation task can assist fusion task" and bridging the feature gap between the two tasks.

Existing deep learning-based image fusion methods can be roughly divided into the following four categories: CNN-based methods [19, 22, 23, 24, 25, 36, 37, 38], AE-based methods [11, 13, 14, 20, 32], GAN-based methods [8, 15, 16, 21, 33, 34, 35] and methods that jointly learn image fusion and high-level vision tasks [9, 17, 18, 39]. The core idea of CNN-based methods is to design network structures and loss functions so that the model can automatically learn the optimal fusion strategy and achieve end-to-end feature extraction, feature fusion, and feature reconstruction. The core idea of AE-based methods is to achieve feature extraction and image reconstruction by training an autoencoder network. GAN-based methods generate high-quality fused images through adversarial learning between the generator and the discriminator. In addition, some studies attempt to jointly optimize image fusion and high-level vision tasks by designing a loss function based on multi-task learning, but it is still difficult to overcome the fundamental problem of the feature gap caused by hierarchical differences. To address this problem, we propose a self-supervised segmentation feature alignment fusion network for infrared and visible image fusion (SegFANet). This network uses a self-supervised approach to achieve segmentation feature alignment. By converting the semantic-level features of segmentation into pixel-level features suitable for image fusion, it bridges the feature gap between the two tasks and achieves collaborative collaboration.
Specifically, we design an image reconstruction module whose core function is to process the semantic-level features output by the segmentation network. This module is trained using a self-supervised strategy and can reconstruct the semantic-level features generated by image segmentation into pixel-level features suitable for image fusion. In detail, this module converts a semantic-level feature into a reconstructed image through convolution, then uses the original image as a reference label to constrain through reconstruction loss. This process bridges the feature gap between segmentation and fusion, enabling effective feature alignment. As shown in Figure 1, the feature map before alignment only retains category-based semantic information, with blurred edges and missing pixel-level details; after alignment, the feature map exhibits pixel-level details. Building on this module, we incorporate an attention mechanism to facilitate feature interaction between the two tasks, enabling effective collaboration and complementary enhancement between image segmentation and fusion processes, thereby improving the quality of image fusion. As illustrated in the locally enlarged areas of Figure 2, our method not only preserves the texture details and color information from visible images but also successfully integrates the thermal radiation information from infrared images. The main contributions are summarized as follows:
We design an image reconstruction module that bridges the feature gap between image fusion and segmentation tasks by converting semantic-level features from the segmentation network into pixel-aligned feature representations suitable for image fusion.

We introduce an attention mechanism to promote feature interaction between the two tasks. In this way, the segmentation task can provide semantic information for the fusion task, better improving the performance of the fusion network and generating high-quality fused images.
The experimental results demonstrate that our method has certain effectiveness in performance. As shown in Figure 2, compared with the state-of-the-art methods, our fusion results demonstrate superior performance.
CNN-based fusion methods can automatically learn the features of the input image by designing a specific network structure and loss function, and fuse these features to generate a high-quality fused image. This process is mainly divided into three steps: feature extraction, feature fusion and image reconstruction. For example, Zhang et al. [22] propose IFCNN, which first uses two convolutional layers to extract salient features from multiple input images, then selects appropriate fusion rules to fuse the extracted features, and reconstructs the fused image through two convolutional layers. Ma et al. [23] propose STDFusionNet, which uses salient object masks to assist fusion tasks. Considering illumination, Tang et al. [24] propose a progressive image fusion network based on illumination perception. Wang et al. [25] propose UMFusion, which generates pseudo-infrared images through a crossmodality perceptual style transfer network (CPSTN) and uses a multi-level refinement registration network (MRRN) for image registration. Finally, the feature interaction fusion module (IFM) is used to adaptively select features for fusion in the dual-path interaction fusion network (DIFN). Furthermore, transformer has shown excellent performance in the visual field due to its powerful modeling ability. Therefore, Tang et al. [19] propose YDTR, which obtains local features and important contextual information through the Y-shaped dynamic transformer module.
AE-based fusion methods achieve feature extraction and image reconstruction by using pre-trained autoencoders, and use manually designed fusion rules in the fusion process. Li et al. [13] propose DenseFuse. Unlike traditional convolutional networks, the encoder of DenseFuse consists of convolutional layers, fusion layers and dense blocks. Li et al. [14] propose NestFuse, which introduces a nest connection architecture and retains multi-scale feature information. Li et al. [20] propose an end-to-end fusion network architecture (RFN-Nest), using RFN to replace traditional methods.
The Generative Adversarial Network (GAN) consists of a generator and a discriminator. GAN-based fusion methods use the adversarial training mechanism of the generator and the discriminator to extract features from the input image and generate the fused image. For example, Ma et al. [15] propose FusionGAN, which constructs an adversarial game mechanism between the generator and the discriminator. In addition, Ma et al. [16] propose a dual-discriminator conditional generative adversarial network (DDcGAN), which achieves the fusion of infrared and visible images with different resolutions through adversarial training between generators and two discriminators.
However, most of these existing deep learning-based image fusion methods are independent of other high-level visual tasks, such as object detection [30] and image segmentation [31]. Currently, Tang et al. [18] propose SeAFusion, which cascades the image fusion module and the semantic segmentation module, and designs a loss based on multi-task learning to constrain the fusion network. But existing multi-task learning methods are mainly applicable to tasks at the same level. As two vision tasks, image fusion and image segmentation have significant differences in feature representation, so bridging the feature gap between the two tasks is still a difficult problem. To bridge this gap, our method adopts the self-supervision idea to convert the segmentation features into pixel-level features that match the image fusion task, thereby narrowing the difference in feature representation between the two tasks.
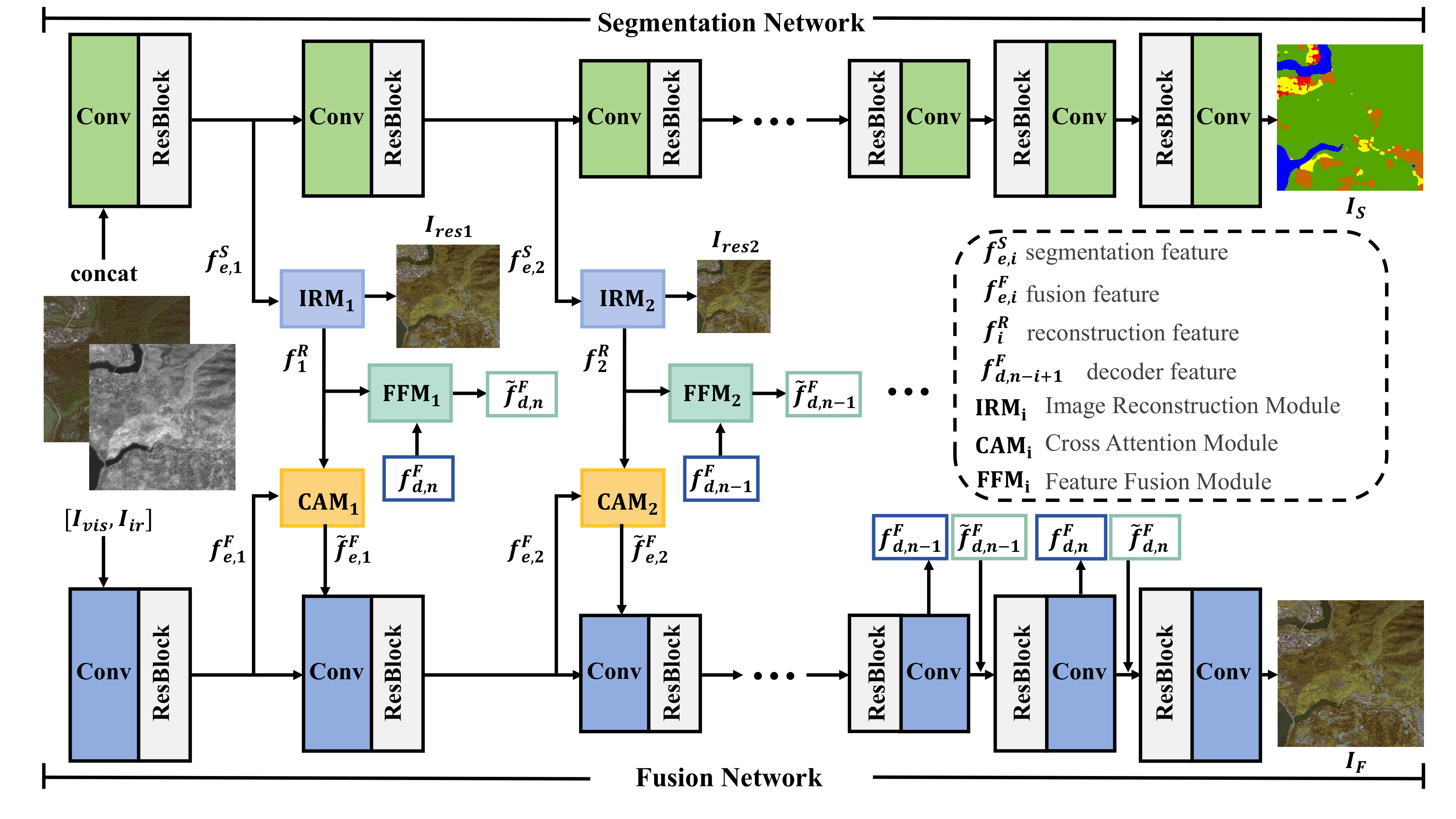
Our SegFANet framework is shown in Figure 3, which consists of three sub-networks: the segmentation network aims to extract target-level features, while the fusion network focuses on pixel-level feature extraction and integration. In order to take advantage of the complementary advantages of multi-task learning, we introduce stage-interactive networks (SINets) between the encoder stages of the two networks. The stage-interactive network aims to assist the fusion network with the semantic information of the segmentation network to help the fusion network better understand the image content. This is achieved through 3 key modules: image reconstruction module (IRM), cross attention module (CAM) and feature fusion module (FFM).
Specifically, SegFANet conducts cross-task feature interactions between the corresponding encoder levels of the segmentation network and the fusion network through n stage-interactive networks. In each network, first, segmentation features and fusion features are extracted from the infrared and visible inputs:
where and denote the infrared and visible input images, and are the -th encoders of the segmentation and fusion branches, and represent their corresponding encoder features.
Then, we construct IRM based on a self-supervision mechanism, which transforms the target-level semantic features from the segmentation network into pixel-level features to bridge the feature gap between image fusion and segmentation:
where denotes the function of the -th IRM, which includes four "Convolution with 3×3 kernel + ReLU" layers, and denotes the segmentation feature produced by the segmentation branch's -th encoder and serves as the input for IRM.
In addition, CAM takes the features and obtained by the fusion network and IRM as inputs, and interacts to obtain a new fusion feature , which can be formulated as:
where denotes the function of the -th CAM, is the fusion feature, and is the reconstructed feature.
Moreover, we develop the FFM, which takes the feature and the feature from the fusion decoder stage at the corresponding resolution as inputs and performs feature fusion. This process enhances the fusion network decoder's ability to understand semantic information, thereby enabling the fusion network to generate high-quality and semantically rich fusion images, which can be formulated as:
where denotes the function of the -th FFM. In the following subsections, we introduce the detailed architectures of CAM and FFM, respectively. In addition, we elaborate on the design of the loss function, which plays a crucial role in guiding the model to improve image fusion quality.
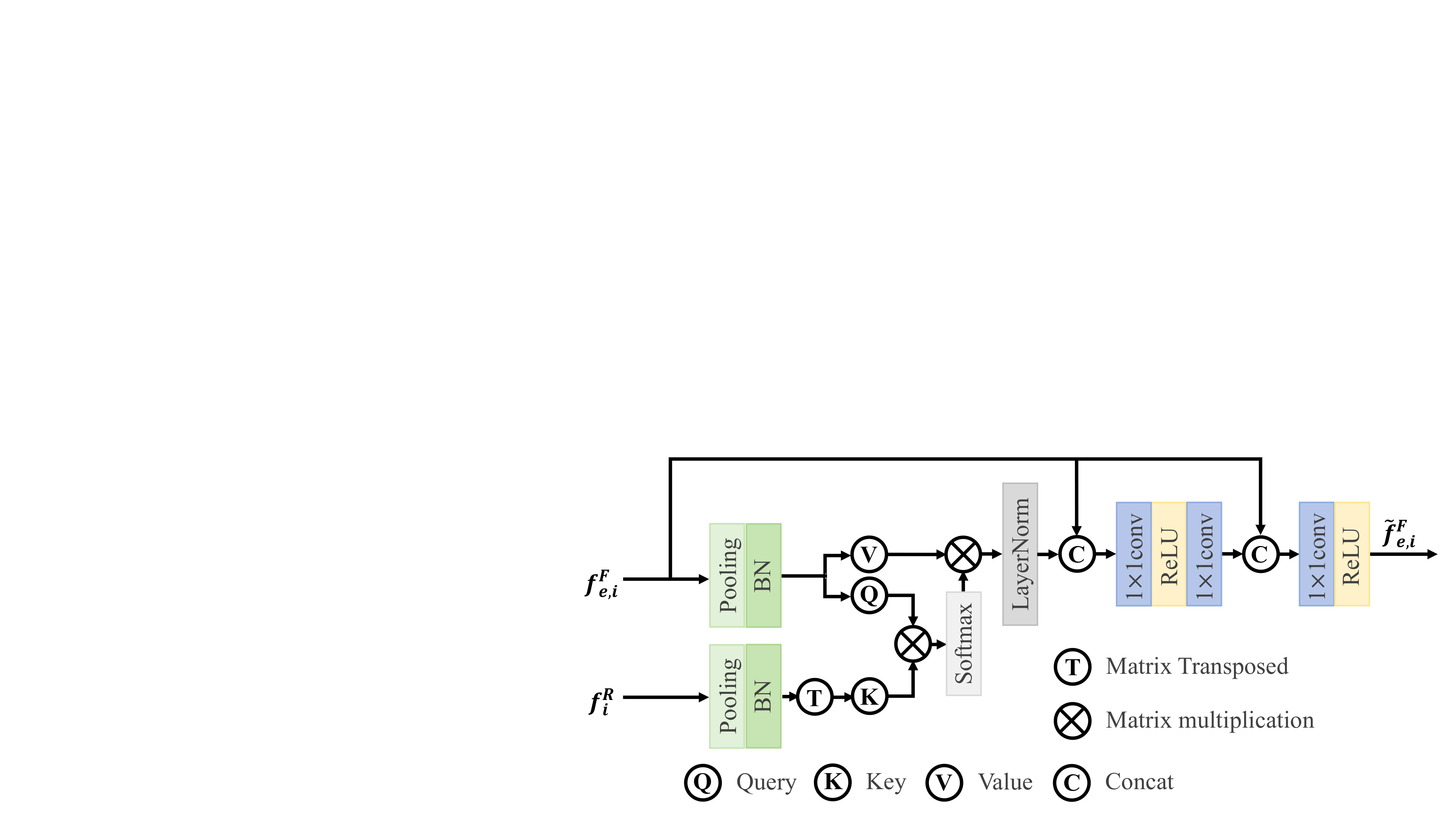
The specific structure of the cross attention module (CAM) is shown in Figure 4. In this module, the input feature is first processed by adaptive average pooling to compress the spatial dimension, and then the Query Q and Value V are generated through the batch normalization layer. At the same time, the same adaptive average pooling and batch normalization operations are performed on another input feature to generate a Key K, which provides a clear semantic prior. By calculating the similarity between K and Q, the fused feature is guided to focus on the target area. Then the softmax function is applied for normalization to generate the attention weight. Finally, the attention weight is used to compute a weighted sum of the V, completing the feature fusion operation. The interacted feature is concatenated with the original fused feature to obtain the final fused feature . The concatenated feature is then directly fed into the convolutional layer of the next stage in the image fusion encoder as its input. This process can be defined as:
where denotes the output feature of the i-th stage of the fusion network encoder and denotes the reconstructed feature of the i-th IRM. represents the batch normalization operation, which stabilizes training and accelerates convergence. denotes the adaptive average pooling operation, which dynamically adjusts the size of the feature map. represents feature concatenation operation, used to preserve more information. Additionally, softmax is used to normalize scores, ensuring that the sum of weights is 1, which is typically applied in attention mechanisms.
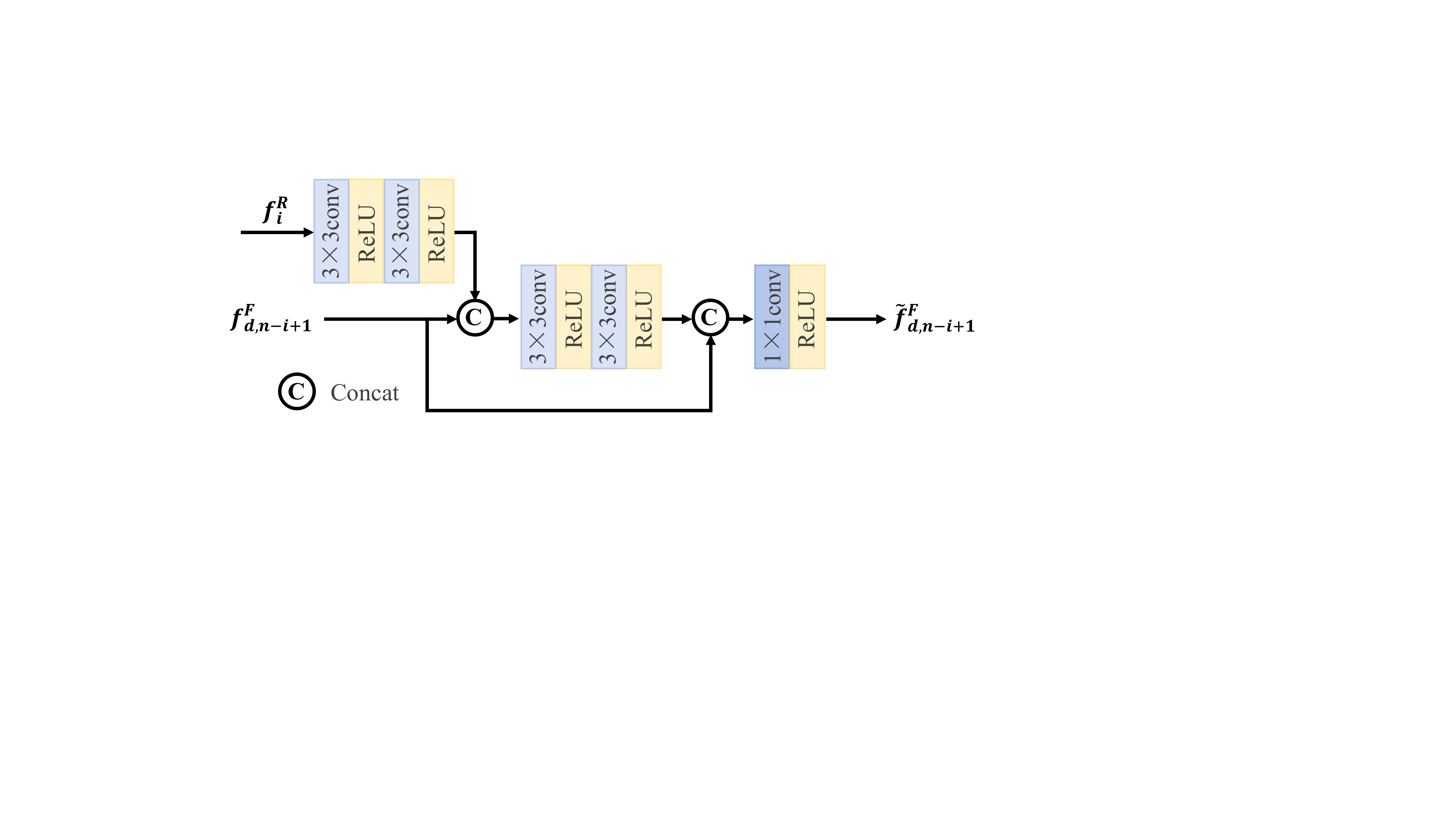
As shown in Figure 5, the feature fusion module (FFM) is mainly composed of convolutional layers and the activation function is ReLU, which is designed to enhance the fusion network decoder's ability to understand semantic information. Specifically, the reconstructed feature is firstly encoded with double convolutions and concatenated with the fusion network decoder feature . The concatenated features are further deepened and fused through two convolutional layers. This process can be represented as:
where denotes the operation of a 3×3 convolutional layer, mainly used for feature extraction of input features.
Subsequently, the deepened features are concatenated with the original again, and finally the number of channels is adjusted through a convolutional layer and output:
where denotes a 1×1 convolutional layer operation, mainly used to adjust the number of feature channels.
To optimize the proposed model, we design a loss function. It converts semantic-level segmentation features into pixel-level features via IRM, bridging the feature gap between segmentation and fusion, enabling their interaction, and improving fusion quality. Specifically, we jointly train fusion, segmentation and reconstruction tasks. Therefore, the designed loss function can be expressed as:
where and represent the image fusion loss and segmentation loss, respectively. And represents the reconstruction loss of segmentation semantic features.
In the fusion stage, the fusion loss is defined as:
where SSIM [26] represents the structural similarity index, which is used to evaluate the difference between the fusion result and the source images and .
The reconstruction loss mainly evaluates the similarity between the reconstructed image and the original infrared and visible images. The is defined as:
where represents the reconstruction loss for the -th image reconstruction module, and is the feature output by the -th image reconstruction module.
In the segmentation stage, the segmentation loss function is composed of the cross-entropy (CE) loss [29] and the dice coefficient loss [27, 28]:
where CE loss is used to measure the difference between the predicted probabilities and the true labels, providing a measure of classification accuracy. The dice coefficient loss, on the other hand, evaluates the similarity between the predicted and true segmentations, making it particularly useful for tasks where the goal is to match the predicted segmentation with the true segmentation.
The model is implemented with PyTorch on GTX 2080TI GPU. During training, we employ the Adam optimizer with a learning rate of 0.0001. The two momentum values of the Adam optimizer are set to 0.9 and 0.999, respectively. The batch size is set to 2, and the number of epochs is set to 50. We train the model on the WHU [44] and Potsdam [45]. The Potsdam dataset provides detailed information about urban environments, mainly including 6 categories: Impervious surfaces, Buildings, Low vegetation, Trees, Cars, and Clutter. It is divided into a training set of 10,830 images and a test set of 2,527 images. The WHU dataset describes the scenario of land, covering 7 categories: Farmland, City, Village, Water, Forest, Road, and Others [46]. It is divided into a training set of 17,280 images and a test set of 4,320 images. Before training, we preprocess the data by cropping the images into patches of size 320×320.
In addition, for quantitative evaluation, four metrics are selected to objectively evaluate the fusion performance, including spatial frequency (SF) [40], average gradient (AG) [41], the sum of the correlations of differences (SCD) [10], and visual information fidelity (VIF) [12]. SF measures the richness of detail information in the image. AG reflects the clarity of the image. SCD reflects the degree of correlation between the information transferred to the fused image and the corresponding source image. VIF measures the degree of visual information preservation of the fused image relative to the source image from the perspective of human visual perception. The larger the SF, AG, SCD and VIF of the fusion algorithm, the better the fusion performance.


In this section, we conduct subjective qualitative and objective quantitative experiments on the WHU and Potsdam datasets to evaluate the performance and advantages of our proposed fusion method. We select five state-of-the-art methods, including UMFusion [25], YDTR [19], Tardal [17], ITFuse [42] and LiMFusion [43], to compare with the proposed model. Next, we conduct a detailed analysis of the fusion results obtained by these methods on the WHU and Potsdam datasets from both subjective and objective dimensions.
First, we qualitatively compare the proposed method with five comparison methods. We select two representative infrared and visible images from the WHU dataset for subjective evaluation, as shown in Figure 6. In the picture, in order to visually compare the fusion effects of different methods, we mark the comparison area with a yellow box, and enlarge the details of the corresponding area and display it in the lower left corner of the image. From the visualization results, it can be observed that the fusion images generated by ITFuse and LiMFusion exhibit lower clarity, with blurred edges and loss of some detail information. Although UMFusion and YDTR have fused infrared and visible information to a certain extent, there is still room for improvement in detail preservation and clarity. Tardal has a high contrast and highlights the infrared thermal radiation target well, but there are local artifacts, and the preservation of texture and edge detail information is not as good as the proposed method. In contrast, the proposed method performs better in integrating the complementary features of infrared and visible images, and the generated fused images have higher clarity, can well preserve edge and texture detail information, and are more in line with the characteristics of the human visual system. Therefore, in the qualitative comparison of infrared and visible image fusion methods, the visualization results of the proposed method outperform those of existing state-of-the-art methods.


In addition, to comprehensively evaluate the performance of the proposed method and five comparison methods, four metrics, SF, AG, SCD and VIF are used to quantitatively analyze the fused image. As shown in Table 1, the average comparison results of the four metrics of the proposed method and other comparison methods on the WHU test set are shown, where the optimal value of each metric is marked in red and the suboptimal value is marked in blue. Obviously, the proposed method is higher than the existing comparison methods in the three evaluation metrics of AG, SCD and VIF, which shows that the fused image generated by the proposed method has the best performance in clarity and retains more feature information of the source image, with better visual performance. Although the proposed method is not the best in the metric of spatial frequency (SF), it is second only to LiMFusion, and the gap is not large, which shows that the fused image generated by the proposed method contains richer texture and edge detail information.
We further conduct experiments on the Potsdam dataset and conduct qualitative and quantitative analysis of the experimental results to demonstrate the effectiveness and superiority of the proposed method on different datasets. Figure 7 shows subjective visualization results of two sets of infrared and visible images. From the experimental results, it can be seen that the fused images generated by LiMFusion and ITFuse have low clarity, some detail loss, and low overall visual quality. The fused images generated by UMFusion and YDTR are not clear enough, the contrast is relatively low, and some texture detail information is lost. The fused images generated by Tardal can retain texture detail information, but the visual effects are poor. In contrast, the proposed method offers better visual effects, retains more source image information, has higher contrast, and better meets human visual system needs.
In addition, Table 2 shows the objective comparison results of different fusion methods on the Potsdam test set. The proposed method has achieved optimal or near-optimal values in most metrics. Specifically, the proposed method performs best in the three metrics of AG, SCD and VIF, which shows that the fused image generated by the proposed method not only has the highest clarity but also can more effectively fuse the key feature information in the source image into the final result, with good fusion quality, which is more in line with the human visual system. In terms of SF, the performance of the proposed method is second only to LiMFusion, which shows that the fused image generated by the proposed method contains relatively rich edge and texture detail information.
In summary, the experimental results on both WHU and Potsdam datasets show that the proposed method exhibits superior performance in infrared and visible image fusion compared with five state-of-the-art methods.
As shown in Figure 3, we introduce stage-interactive networks between the encoder stages of the segmentation network and the fusion network. The stage-interactive network mainly includes an image reconstruction module, a cross attention module, and a feature fusion module. The stage-interactive network is responsible for bridging the feature gap between segmentation and fusion tasks, thereby achieving feature interaction between segmentation and fusion tasks and improving the performance of fusion tasks. In this study, a total of three stages of feature interaction are used. This section aims to explore the impact of the number of stage-interactive networks on model performance. Table 3 lists in detail the quantitative evaluation results of different numbers of stage-interactive networks on the WHU dataset.
| Number | SF | AG | SCD | VIF |
|---|---|---|---|---|
| 1 | 16.8547 | 5.9754 | 1.3188 | 1.0966 |
| 2 | 16.8693 | 5.9798 | 1.3182 | 1.0971 |
| 3 | 16.8724 | 5.9824 | 1.3197 | 1.0969 |
As can be seen from Table 3, as the number of stage-interactive networks increases, the performance of the fusion task is generally improved, which indicates that a greater number of stage-interactive networks can more effectively enhance the interaction between the features of the fusion and segmentation tasks, so that the fusion network can better utilize the semantic information of the segmentation network. When the number of stage-interactive network is 3, most metrics reach the optimal or near-optimal values, which shows that the fusion effect is better at this time, the generated fusion image has higher clarity, richer edge and texture detail information, and has more advantages in meeting the needs of the human visual system.
The role of the image reconstruction module (IRM) is to align the target-level features of the segmentation network with the pixel-level features of the image fusion task, thereby bridging the feature gap between image fusion and image segmentation. In this section, to fully verify the effectiveness of the image reconstruction module, we design a series of comparative experiments. Firstly, for the fusion model containing two stage-interactive networks, we conduct two experiments: one retains the image reconstruction module and the other removes the module while keeping other structures unchanged, in order to observe the specific impact of the image reconstruction module on the quality of the fused image.
In addition, to further explore the performance of the image reconstruction module under different configurations, we also add a set of experiments to compare the performance difference between retaining and deleting the image reconstruction module in a fusion model that includes a three stage-interactive networks. The experimental results of the objective evaluation metrics are shown in Table 4.
| Setting | SF | AG | SCD | VIF |
|---|---|---|---|---|
| Two-SINets (w/ IRM) | 16.8693 | 5.9798 | 1.3182 | 1.0971 |
| Two-SINets (w/o IRM) | 16.8419 | 5.9713 | 1.3179 | 1.0967 |
| Three-SINets (w/ IRM) | 16.8724 | 5.9824 | 1.3197 | 1.0969 |
| Three-SINets (w/o IRM) | 16.8317 | 5.9695 | 1.3189 | 1.0964 |

As shown in Table 4, by comparing the results of the first two experiments, it can be seen that the setting including the image reconstruction module is better than the setting without the module in all metrics, proving that the image reconstruction module can improve the quality of the fused image. Similarly, the comparison of the results of the last two experiments also verifies this point, further proving the effect of the image reconstruction module.
Moreover, we validate the alignment effect of the image reconstruction module by visualizing intermediate features (comparing segmentation features, reconstructed features, and fusion features). As shown in Figure 8, the segmentation features before alignment lack pixel-level detail information (e.g., the edge contours of farmland are blurred). In contrast, after adding the image reconstruction module, the boundaries between farmland and water are clearly presented, and semantic-level features are reconstructed into pixel-level features suitable for image fusion, achieving accurate feature alignment.
The cross attention module (CAM) is responsible for promoting the interaction of features between image segmentation and image fusion, thereby helping the fusion task to better fuse salient targets during the fusion process to improve the quality of the fused image. In this section, in order to fully verify the effect of the cross attention module, we design two sets of comparative experiments. Firstly, for the fusion model containing two stage-interactive networks, we conduct two experiments: one retains the cross attention module, and the other replaces the cross attention module with a simple feature addition operation. Secondly, we also compare the performance differences when retaining the cross attention module and replacing the cross attention module with a feature addition operation in the context of the three stage-interactive networks. The experimental results are shown in Table 5.
| Setting | SF | AG | SCD | VIF |
|---|---|---|---|---|
| Two-SINets (w/ CAM) | 16.8693 | 5.9798 | 1.3182 | 1.0971 |
| Two-SINets (w/o CAM) | 16.8699 | 5.9786 | 1.317 | 1.0966 |
| Three-SINets (w/ CAM) | 16.8724 | 5.9824 | 1.3197 | 1.0969 |
| Three-SINets (w/o CAM) | 16.8684 | 5.9815 | 1.3206 | 1.0969 |
As shown in Table 5, the results show that whether it is a two stage-interactive or a three stage-interactive, the introduction of the cross attention module is more helpful in improving the quality of the fused image than the simple feature addition operation.
To further validate the effectiveness of the CAM module, we visualize the distribution of attention weights using heatmaps (see Figure 9). As observed from the heatmaps, attention weights are predominantly focused on target regions (e.g., forest), which enables the segmentation task to effectively assist the fusion task and thereby enhancing the quality of image fusion.

To address the difference in feature representation between image fusion and image segmentation, this paper proposes self-supervised feature alignment for infrared and visible image fusion. The innovation of this method lies in the design of an image reconstruction module, which aligns the target-level features extracted by the segmentation network with the pixel-level features extracted by the fusion network through a self-supervised method, effectively bridging the feature gap between image fusion and image segmentation. In addition, the cross attention module is introduced to promote feature interaction between the two tasks, thereby achieving efficient collaboration between image segmentation and image fusion tasks. Finally, the performance advantages of the proposed method are demonstrated through comprehensive qualitative and quantitative analysis on the WHU and Potsdam datasets. However, the performance of the proposed method depends on the supervision information provided by the segmentation task. In future work, we will explore how to mine semantic information to improve fusion quality without segmentation supervision.
 Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/