Reservoir Science | Volume 2, Issue 3: 228-260, 2026 | DOI: 10.62762/RS.2026.704585
Abstract
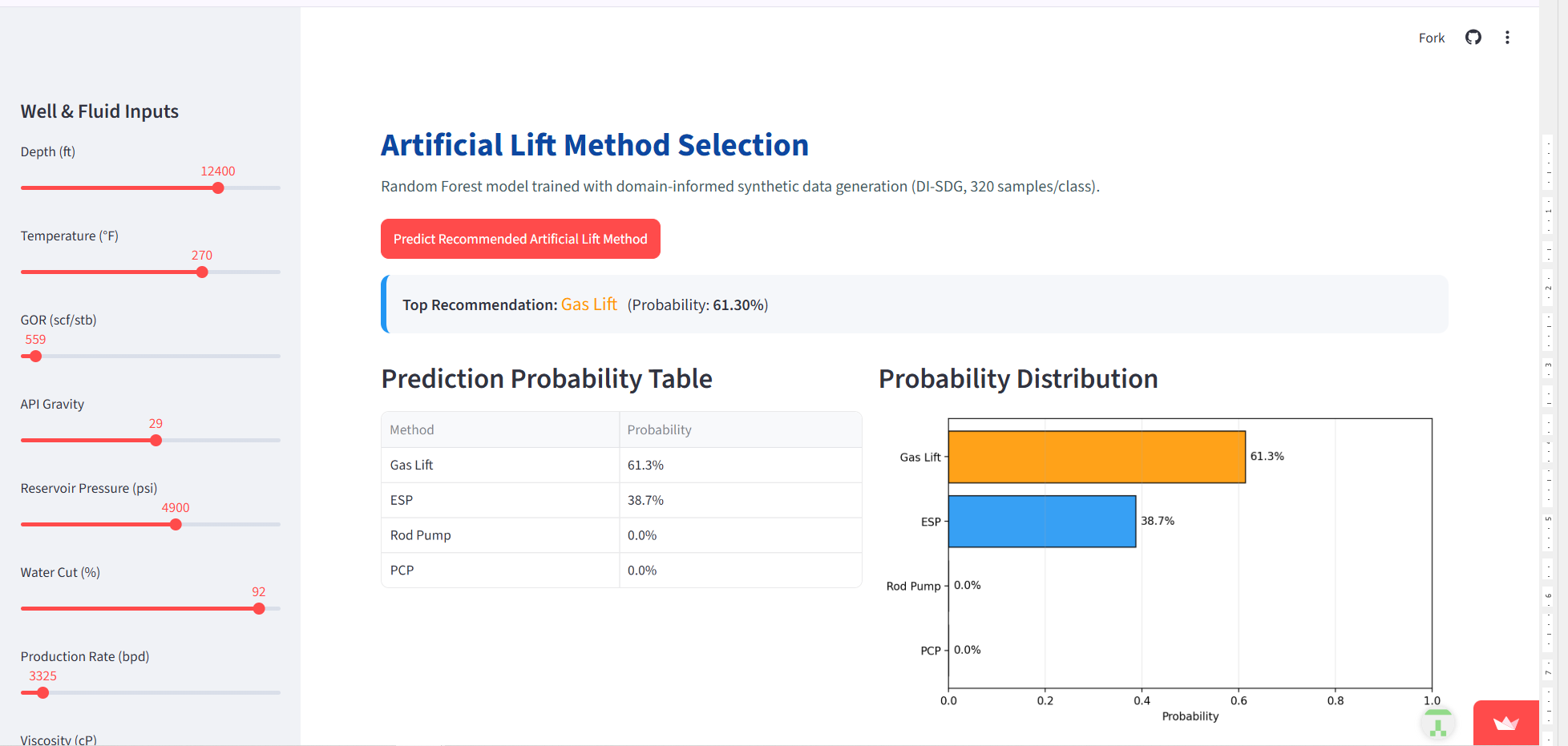
The selection of optimal artificial lift methods using machine learning remains challenging due to complex interactions among reservoir characteristics, fluid properties, and operational constraints. Conventional approaches rely on engineering expertise and static screening criteria, often insufficient to capture multifactorial dependencies. This study presents a framework for classifying the most suitable lift method from four common techniques: ESP, Gas Lift, Rod Pumps, and PCP. A dataset of 990 wells with twelve physically meaningful parameters was compiled, including depth, temperature, GOR, API gravity, reservoir pressure, water cut, production rate, viscosity, sand production, deviatio... More >
Graphical Abstract