Reservoir Science
ISSN: 3070-2356 (Online)
Email: [email protected]
 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue

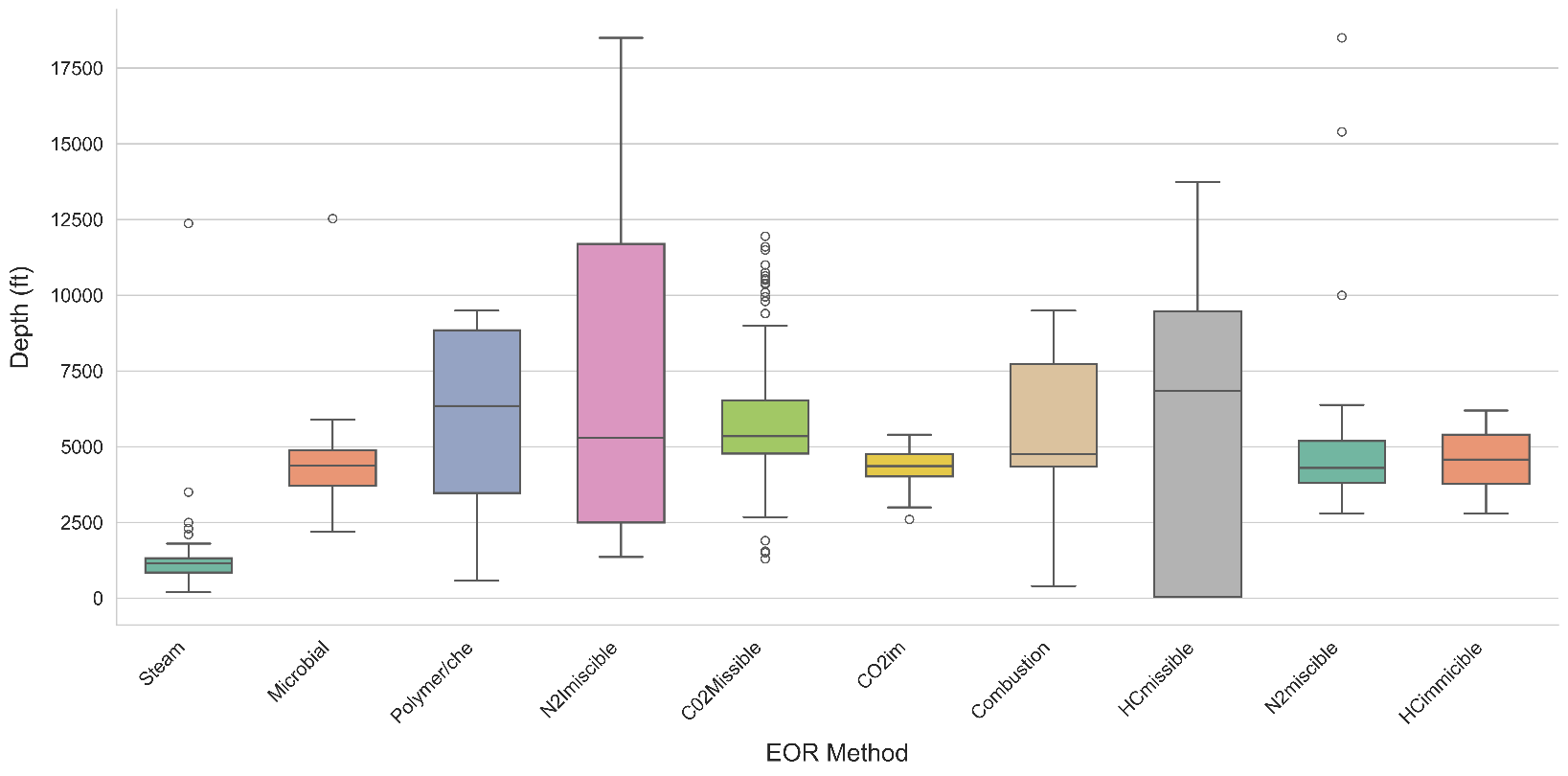
TY - JOUR AU - Ali, Jawad AU - Ansari, Ubedullah AU - Ali, Fateh AU - Javed, Tariq AU - Hullio, Imran Ahmed PY - 2026 DA - 2026/02/27 TI - Application of Machine Learning for Effective Screening of Enhanced Oil Recovery Methods JO - Reservoir Science T2 - Reservoir Science JF - Reservoir Science VL - 2 IS - 1 SP - 65 EP - 80 DO - 10.62762/RS.2025.333184 UR - https://www.icck.org/article/abs/RS.2025.333184 KW - EOR screening KW - machine learning KW - screening criteria KW - imbalanced data KW - multi-class classification KW - enhanced oil recovery AB - Selecting the most suitable enhanced oil recovery (EOR) technique remains challenging due to severe class imbalance in historical datasets and the limitations of traditional screening criteria. To address data imbalance while preserving domain knowledge, this study proposes a novel machine learning framework that incorporates domain-informed synthetic data generation strictly constrained by established EOR screening criteria. An initial dataset of 583 documented EOR projects was compiled from field reports and public databases. After rigorous cleaning, 575 valid samples were retained and subsequently augmented to 760 balanced instances (class sizes ranging from 60–110 samples per class). This reduced the imbalance ratio from 123:1 to approximately 1.8:1. The augmented dataset was processed using principal component analysis (PCA) for dimensionality reduction, followed by hyperparameter tuning and 5-fold cross-validation. Among the evaluated models, K-Nearest Neighbors (KNN) and Random Forest achieved the highest macro-averaged performance (F1-score of 0.89 and 0.85, respectively). The results demonstrate that domain-guided synthetic data generation significantly improves model accuracy and robustness for multi-class EOR screening, offering reservoir engineers a reliable, machine learning-supported decision-making tool. SN - 3070-2356 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Ali2026Applicatio,
author = {Jawad Ali and Ubedullah Ansari and Fateh Ali and Tariq Javed and Imran Ahmed Hullio},
title = {Application of Machine Learning for Effective Screening of Enhanced Oil Recovery Methods},
journal = {Reservoir Science},
year = {2026},
volume = {2},
number = {1},
pages = {65-80},
doi = {10.62762/RS.2025.333184},
url = {https://www.icck.org/article/abs/RS.2025.333184},
abstract = {Selecting the most suitable enhanced oil recovery (EOR) technique remains challenging due to severe class imbalance in historical datasets and the limitations of traditional screening criteria. To address data imbalance while preserving domain knowledge, this study proposes a novel machine learning framework that incorporates domain-informed synthetic data generation strictly constrained by established EOR screening criteria. An initial dataset of 583 documented EOR projects was compiled from field reports and public databases. After rigorous cleaning, 575 valid samples were retained and subsequently augmented to 760 balanced instances (class sizes ranging from 60–110 samples per class). This reduced the imbalance ratio from 123:1 to approximately 1.8:1. The augmented dataset was processed using principal component analysis (PCA) for dimensionality reduction, followed by hyperparameter tuning and 5-fold cross-validation. Among the evaluated models, K-Nearest Neighbors (KNN) and Random Forest achieved the highest macro-averaged performance (F1-score of 0.89 and 0.85, respectively). The results demonstrate that domain-guided synthetic data generation significantly improves model accuracy and robustness for multi-class EOR screening, offering reservoir engineers a reliable, machine learning-supported decision-making tool.},
keywords = {EOR screening, machine learning, screening criteria, imbalanced data, multi-class classification, enhanced oil recovery},
issn = {3070-2356},
publisher = {Institute of Central Computation and Knowledge}
}
 Copyright © 2026 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2026 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. 
Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/