Reinforcement Learning for Prompt Optimization in Language Models: A Comprehensive Survey of Methods, Representations, and Evaluation Challenges

Article Information
Abstract
The growing prominence of prompt engineering as a means of controlling large language models has given rise to a diverse set of methods, ranging from handcrafted templates to embedding-level tuning. Yet, as prompts increasingly serve not merely as input scaffolds but as adaptive interfaces between users and models, the question of how to systematically optimize them remains unresolved. Reinforcement learning, with its capacity for sequential decision-making and reward-driven adaptation, has been proposed as a possible framework for discovering effective prompting strategies. This survey explores the emerging intersection of RL and prompt engineering, organizing existing research along three interdependent axes: the representation of prompts (symbolic, soft, and hybrid), the design of RL-based optimization mechanisms, and the challenges of evaluating and generalizing learned prompt policies. Rather than presenting a single unified framework, the discussion reflects the fragmented, often experimental nature of current approaches, many of which remain constrained by unstable reward signals, limited generalizability, and a lack of reproducible evaluation standards. By analyzing methodological innovations and points of friction alike, this work aims to foster a more critical and reflective understanding of what it means to "learn to prompt" in complex, real-world language modeling contexts.
Graphical Abstract
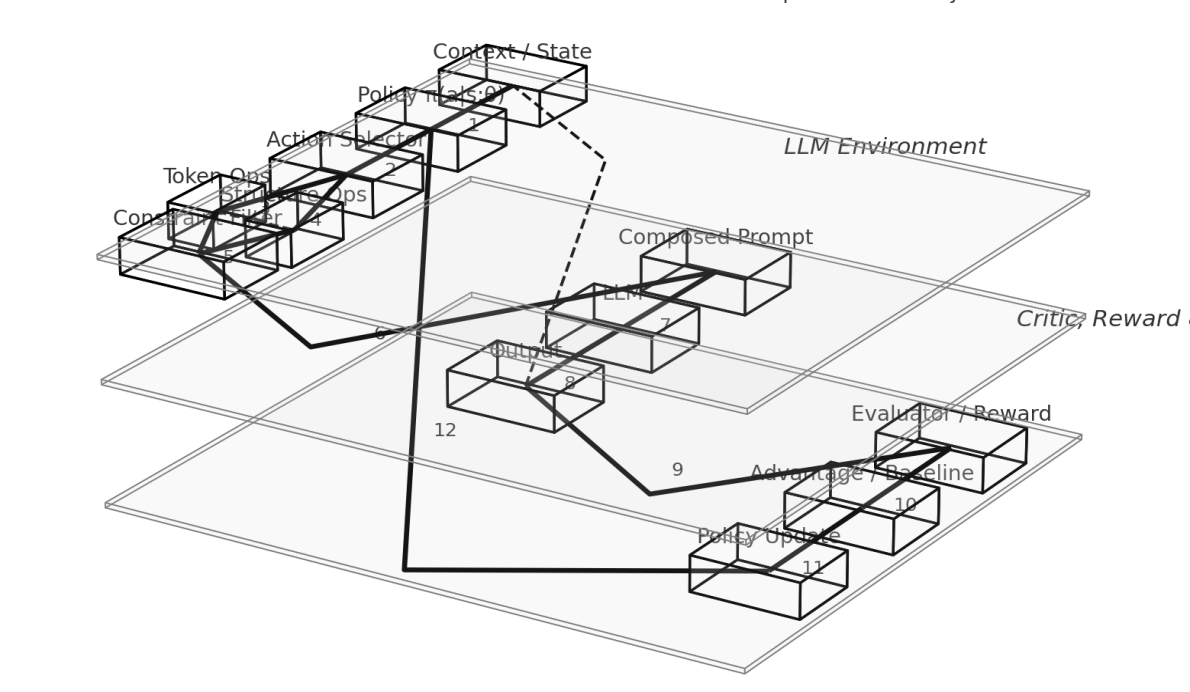
Keywords
Data Availability Statement
Funding
Conflicts of Interest
Ethical Approval and Consent to Participate
References
- Zheng, H., Shen, L., Tang, A., Luo, Y., Hu, H., Du, B., ... & Tao, D. (2025). Learning from models beyond fine-tuning. Nature Machine Intelligence, 7(1), 6-17.
[CrossRef] [Google Scholar] - Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2023). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM computing surveys, 55(9), 1-35.
[CrossRef] [Google Scholar] - Banerjee, C., & Nazir, M. S. Zero-Shot Llms in Human-in-The-Loop Rl: Replacing Human Feedback for Reward Shaping. Available at SSRN 5218722. https://dx.doi.org/10.2139/ssrn.5218722
[Google Scholar] - Ling, C., Zhao, X., Lu, J., Deng, C., Zheng, C., Wang, J., ... & Zhao, L. (2023). Domain specialization as the key to make large language models disruptive: A comprehensive survey. ACM Computing Surveys.
[CrossRef] [Google Scholar] - Xin, X., Pimentel, T., Karatzoglou, A., Ren, P., Christakopoulou, K., & Ren, Z. (2022, July). Rethinking reinforcement learning for recommendation: A prompt perspective. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval (pp. 1347-1357).
[CrossRef] [Google Scholar] - Lester, B., Al-Rfou, R., & Constant, N. (2021, November). The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 3045-3059).
[CrossRef] [Google Scholar] - Lu, D., Wu, S., & Huang, X. (2025, March). Research on personalized medical intervention strategy generation system based on group relative policy optimization and time-series data fusion. In Proceedings of the 2025 International Conference on Health Big Data (pp. 86-91).
[CrossRef] [Google Scholar] - Wu, S., Huang, X., & Lu, D. (2025, March). Psychological health knowledge-enhanced LLM-based social network crisis intervention text transfer recognition method. In Proceedings of the 2025 International Conference on Health Big Data (pp. 156-161).
[CrossRef] [Google Scholar] - Shih, K., Deng, Z., Chen, X., Zhang, Y., & Zhang, L. (2025, May). DST-GFN: A Dual-Stage Transformer Network with Gated Fusion for Pairwise User Preference Prediction in Dialogue Systems. In 2025 8th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE) (pp. 715-719). IEEE.
[CrossRef] [Google Scholar] - Xing, Y., & Liu, P. (2023, June). Prompt and instruction-based tuning for response generation in conversational question answering. In International conference on applications of natural language to information systems (pp. 156-169). Cham: Springer Nature Switzerland.
[CrossRef] [Google Scholar] - Meynhardt, C., Meybohm, P., Kranke, P., & Hölzing, C. R. (2025). Advanced Prompt Engineering in Emergency Medicine and Anesthesia: Enhancing Simulation-Based e-Learning. Electronics, 14(5), 1028. 10.3390/electronics14051028
[Google Scholar] - Feng, H., Dai, Y., & Gao, Y. (2025). Personalized Risks and Regulatory Strategies of Large Language Models in Digital Advertising. arXiv preprint arXiv:2505.04665.
[CrossRef] [Google Scholar] - Huang, T., Yi, J., Yu, P., & Xu, X. (2025, March). Unmasking digital falsehoods: A comparative analysis of LLM-based misinformation detection strategies. In 2025 8th International Conference on Advanced Algorithms and Control Engineering (ICAACE) (pp. 2470-2476). IEEE.
[CrossRef] [Google Scholar] - Xu, M., Shen, Y., Zhang, S., Lu, Y., Zhao, D., Tenenbaum, J., & Gan, C. (2022, June). Prompting decision transformer for few-shot policy generalization. In international conference on machine learning (pp. 24631-24645). PMLR.
[Google Scholar] - Shin, T., Razeghi, Y., Logan IV, R. L., Wallace, E., & Singh, S. (2020, November). AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4222-4235).
[CrossRef] [Google Scholar] - Do, X. L., Dinh, D., Nguyen, N. H., Kawaguchi, K., Chen, N., Joty, S., & Kan, M. Y. (2025, July). What Makes a Good Natural Language Prompt?. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 5835-5873).
[CrossRef] [Google Scholar] - Yi, Q., He, Y., Wang, J., Song, X., Qian, S., Yuan, X., ... & Shi, T. (2025). Score: Story coherence and retrieval enhancement for ai narratives. arXiv preprint arXiv:2503.23512.
[Google Scholar] - Saletta, M., & Ferretti, C. (2024, July). Exploring the prompt space of large language models through evolutionary sampling. In Proceedings of the Genetic and Evolutionary Computation Conference (pp. 1345-1353).
[CrossRef] [Google Scholar] - Liu, S., Fang, Y., Cheng, H., Pan, Y., Liu, Y., & Gao, C. (2023, November). Large Language Models guided Generative Prompt for Dialogue Generation. In 2023 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC) (pp. 10-17). IEEE.
[CrossRef] [Google Scholar] - Tao, Y., Wang, Z., Zhang, H., Wang, L., & Gu, J. (2025, July). Nevlp: Noise-robust framework for efficient vision-language pre-training. In International Conference on Intelligent Computing (pp. 74-85). Singapore: Springer Nature Singapore.
[CrossRef] [Google Scholar] - Nadizar, G., Rovito, L., De Lorenzo, A., Medvet, E., & Virgolin, M. (2024). An analysis of the ingredients for learning interpretable symbolic regression models with human-in-the-loop and genetic programming. ACM Transactions on Evolutionary Learning and Optimization, 4(1), 1-30.
[CrossRef] [Google Scholar] - Jain, A. M., & Jindal, M. (2025, March). Systematic survey of various prompt optimization methods and their classifications. In 2025 11th International Conference on Computing and Artificial Intelligence (ICCAI) (pp. 524-536). IEEE.
[CrossRef] [Google Scholar] - Huang, T., Xu, Z., Yu, P., Yi, J., & Xu, X. (2025). A hybrid transformer model for fake news detection: Leveraging Bayesian optimization and bidirectional recurrent unit. arXiv preprint arXiv:2502.09097.
[Google Scholar] - Shorinwa, O., Mei, Z., Lidard, J., Ren, A. Z., & Majumdar, A. (2025). A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions. ACM Computing Surveys.
[CrossRef] [Google Scholar] - He, Y., Wang, J., Wang, Y., Li, K., Zhong, Y., Song, X., ... & Chen, J. (2025). Enhancing intent understanding for ambiguous prompt: A human-machine co-adaption strategy. arXiv preprint arXiv:2501.15167.
[Google Scholar] - Milani, S., Topin, N., Veloso, M., & Fang, F. (2024). Explainable reinforcement learning: A survey and comparative review. ACM Computing Surveys, 56(7), 1-36.
[CrossRef] [Google Scholar] - Huang, T., Cui, Z., Du, C., & Chiang, C. E. (2025). CL-ISR: A Contrastive Learning and Implicit Stance Reasoning Framework for Misleading Text Detection on Social Media. arXiv preprint arXiv:2506.05107.
[Google Scholar] - Ciniselli, M., Cooper, N., Pascarella, L., Mastropaolo, A., Aghajani, E., Poshyvanyk, D., ... & Bavota, G. (2021). An empirical study on the usage of transformer models for code completion. IEEE Transactions on Software Engineering, 48(12), 4818-4837.
[CrossRef] [Google Scholar] - Sheilsspeigh, P., Larkspur, M., Carver, S., & Longmore, S. (2024). Dynamic context shaping: A new approach to adaptive representation learning in large language models.
[CrossRef] [Google Scholar] - Samuel, J., Khanna, T., Esguerra, J., Sundar, S., Pelaez, A., & Bhuyan, S. S. (2025). The Rise of Artificial Intelligence Phobia! Unveiling News-Driven Spread of AI Fear Sentiment using ML, NLP and LLMs. IEEE Access.
[CrossRef] [Google Scholar] - Deng, Z., Ma, W., Han, Q. L., Zhou, W., Zhu, X., Wen, S., & Xiang, Y. (2025). Exploring DeepSeek: A Survey on Advances, Applications, Challenges and Future Directions. IEEE/CAA Journal of Automatica Sinica, 12(5), 872-893.
[CrossRef] [Google Scholar]
Cited By (8)
-
Shengjie Ye. Emotional Engagement with AI-generated vs Traditional Art.
Scientific Research Bulletin, 2026 , 2 (5).
[CrossRef] -
Qian Cui, Enhao Ning, Minghua Du, Baoli Lu, Shuang Li, Jiong Xiang, Shuyao He. Uncertainty-aware traffic prediction and routing for emergency vehicles: a multi-objective risk-aware framework.
Connection Science, 2026 , 38 (1).
[CrossRef] -
Quan Su. Designing Emotion-adaptive Human - AI Interfaces: An Empirical Study on Empathy, Trust, and Context-aware Interaction.
Scientific Research Bulletin, 2026 , 2 (5).
[CrossRef] -
Wenqiang Lu, Shengjie Ye. <i><b>The Role of Generative AI in Economic Research: Enhancing Productivity and Cognitive Automation</b></i>.
Al lnnovations and Applications, 2026 , 2 (1).
[CrossRef] -
Pelin Karaçay, Polat Goktas. The emerging future of healthcare simulation with artificial intelligence integration.
Teaching and Learning in Nursing, 2026 .
[CrossRef] -
Kai Ye. <i><b>Economic Policy Challenges in the Age of Artificial General Intelligence</b></i>.
Al lnnovations and Applications, 2025 , 1 (1).
[CrossRef] -
Shengjie Ye. <i><b>Cultural Representations in Artificial Intelligence and Finance from a Cross-Cultural Perspective</b></i>.
Al lnnovations and Applications, 2025 , 1 (1).
[CrossRef] -
Fan hao. <i><b>Maximum Macroeconomic Impacts of AI:</b><b> </b><b>Automation, Task Complementarity, and Their Effects on Productivity and Inequality</b></i>.
Al lnnovations and Applications, 2025 , 1 (1).
[CrossRef]
Cite This Article
TY - JOUR AU - Liu, Zhangqi PY - 2025 DA - 2025/09/14 TI - Reinforcement Learning for Prompt Optimization in Language Models: A Comprehensive Survey of Methods, Representations, and Evaluation Challenges JO - ICCK Transactions on Emerging Topics in Artificial Intelligence T2 - ICCK Transactions on Emerging Topics in Artificial Intelligence JF - ICCK Transactions on Emerging Topics in Artificial Intelligence VL - 2 IS - 4 SP - 173 EP - 181 DO - 10.62762/TETAI.2025.790504 UR - https://www.icck.org/article/abs/TETAI.2025.790504 KW - prompt engineering KW - reinforcement learning KW - language models KW - prompt optimization KW - reward design KW - prompt representation AB - The growing prominence of prompt engineering as a means of controlling large language models has given rise to a diverse set of methods, ranging from handcrafted templates to embedding-level tuning. Yet, as prompts increasingly serve not merely as input scaffolds but as adaptive interfaces between users and models, the question of how to systematically optimize them remains unresolved. Reinforcement learning, with its capacity for sequential decision-making and reward-driven adaptation, has been proposed as a possible framework for discovering effective prompting strategies. This survey explores the emerging intersection of RL and prompt engineering, organizing existing research along three interdependent axes: the representation of prompts (symbolic, soft, and hybrid), the design of RL-based optimization mechanisms, and the challenges of evaluating and generalizing learned prompt policies. Rather than presenting a single unified framework, the discussion reflects the fragmented, often experimental nature of current approaches, many of which remain constrained by unstable reward signals, limited generalizability, and a lack of reproducible evaluation standards. By analyzing methodological innovations and points of friction alike, this work aims to foster a more critical and reflective understanding of what it means to "learn to prompt" in complex, real-world language modeling contexts. SN - 3068-6652 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Liu2025Reinforcem,
author = {Zhangqi Liu},
title = {Reinforcement Learning for Prompt Optimization in Language Models: A Comprehensive Survey of Methods, Representations, and Evaluation Challenges},
journal = {ICCK Transactions on Emerging Topics in Artificial Intelligence},
year = {2025},
volume = {2},
number = {4},
pages = {173-181},
doi = {10.62762/TETAI.2025.790504},
url = {https://www.icck.org/article/abs/TETAI.2025.790504},
abstract = {The growing prominence of prompt engineering as a means of controlling large language models has given rise to a diverse set of methods, ranging from handcrafted templates to embedding-level tuning. Yet, as prompts increasingly serve not merely as input scaffolds but as adaptive interfaces between users and models, the question of how to systematically optimize them remains unresolved. Reinforcement learning, with its capacity for sequential decision-making and reward-driven adaptation, has been proposed as a possible framework for discovering effective prompting strategies. This survey explores the emerging intersection of RL and prompt engineering, organizing existing research along three interdependent axes: the representation of prompts (symbolic, soft, and hybrid), the design of RL-based optimization mechanisms, and the challenges of evaluating and generalizing learned prompt policies. Rather than presenting a single unified framework, the discussion reflects the fragmented, often experimental nature of current approaches, many of which remain constrained by unstable reward signals, limited generalizability, and a lack of reproducible evaluation standards. By analyzing methodological innovations and points of friction alike, this work aims to foster a more critical and reflective understanding of what it means to "learn to prompt" in complex, real-world language modeling contexts.},
keywords = {prompt engineering, reinforcement learning, language models, prompt optimization, reward design, prompt representation},
issn = {3068-6652},
publisher = {Institute of Central Computation and Knowledge}
}
Article Metrics
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions
 Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.

Portico
