





Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

The advent of Internet technology, driven by social media and e-commerce platforms, offers a convenient way to generate and share multimodal data. Efficient and accurate retrieval of relevant information from vast multimodal data has garnered increased interest from researchers due to its extensive real-world applications. Cross-modal image-text retrieval enables semantic search of instances in one modality (e.g., image) based on queries from another modality (e.g., text). Cross-modal image-text retrieval typically includes two main tasks: image query text (IqT) retrieval and text query image (TqI) retrieval. The formal definition is as follows:
The multimodal training set, denoted as , consists of n instances. Each instance comprises an original image sample , a text sample , and a label annotation vector = [], where is the number of classes. Each annotation equals if the instance belongs to the -th class, and equals otherwise (). The testing set consists of m query instances, where . For each query sample or , samples of the other modality that are semantically relevant should be returned.
Deep learning-based cross-modal image-text retrieval has achieved great success due to deep models that can effectively extract semantic information from visual and language data of different modalities.
Furthermore, with the success of large language models (LLMs) like ChatGPT, multimodal Large Language Models (MLLMs) have emerged, drawing more attention from researchers. Several previous efforts have surveyed cross-modal image-text retrieval. However, current surveys often classify cross-modal retrieval models from only a single perspective (e.g., subspace learning model or deep learning model), leading to insufficiently thorough results. Moreover, there is a lack of analysis on the cross-modal retrieval capabilities of the latest multimodal large language models. Inspired by this, we present a more comprehensive and up-to-date survey of cross-modal image-text retrieval in this paper.

The two most critical factors influencing cross-modal image-text retrieval systems are model structure and feature representation. We classify existing models based on these two key aspects to provide a more thorough analysis of cross-modal image-text retrieval. Figure 1 illustrates our classification of cross-modal retrieval models.
Single-tower models, also known as single-stream models, utilize a unified architecture to process both modalities simultaneously. These models integrate the modalities early, aiming to learn joint representations directly. They are beneficial for capturing complex interactions but may face scalability and fusion challenges.
Dual-tower models, also known as two-stream models, use separate architectures (towers) for each modality. These models process each modality separately, allowing for specialized processing and scalability. However, they must ensure compatibility between the independently learned representations for effective retrieval.
Real-value representation models involve encoding data into continuous vectors in a high-dimensional space. These vectors typically consist of floating-point numbers. These models are suitable for capturing detailed and complex relationships. However, they incur high computational and storage costs, making them less ideal for large-scale data applications.
Binary representation models encode data into compact, fixed-length binary codes (e.g., hash vectors of bits). These models offer efficient storage and fast retrieval, making them well-suited for large-scale databases. However, they may sacrifice some accuracy and require sophisticated projection models to learn effective binary codes.
Based on above classification, we summarize the representative cross-modal image-text retrieval methods, as depicted in Table 1. The structure of our study is outlined as follows: First, we summarize cross-modal image-text retrieval models based on the above taxonomy in Section 2. Section 3 introduces MLLMs and focuses on their capabilities in cross-modal retrieval tasks. Section 4 provides a detailed overview of common cross-modal image-text datasets, evaluation metrics, and accuracy comparisons among representative approaches. Section 5 summarizes the challenges identified in the preceding review and outlines meaningful research directions for the future.
This section reviews recent research on cross-modal image-text retrieval using deep-learning neural networks. These models typically involve two main components: feature extraction from each modality and feature alignment or fusion through an alignment or fusion module. The primary goal is to learn a common semantic subspace that preserves semantic correlations both within and across modalities. We categorize these models based on their structure and feature representation into four categories: single-tower models, dual-tower models, real-valued representation models, and binary representation models.
| Categories | Model | Technology | Pros&Cons | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ViLT [8] |
|
|
||||||||
| Single-tower models | Unicoder [9] |
|
|
|||||||
| VisualBERT [10] |
|
|
||||||||
| ViLBERT [11] |
|
|
||||||||
| Dual-tower models | CLIP [12] |
|
|
|||||||
| ALIGN [14] |
|
|
||||||||
| ACMR [15] |
|
|
||||||||
| Deep learning-based models | DSCMR [16] |
|
|
|||||||
| Real-value representation models | IEFT [17] | Channelwise feature enhancement |
|
|||||||
| COTS [18] |
|
|
||||||||
| TEAM [19] |
|
|
||||||||
| CLIP4CMR [34] |
|
|
||||||||
| DCMH [20] |
|
|
||||||||
| UDCMH [21] |
|
|
||||||||
| Binary representation models | SSAH [22] |
|
|
|||||||
| Bi-CMR [23] |
|
|
||||||||
| DCHMT [24] |
|
|
||||||||
| DSPH [36] |
|
|
||||||||
| BLIP-2 [1] |
|
|
||||||||
| InternLM [2] |
|
|
||||||||
| EIIRwQR [3] |
|
|
||||||||
| Multimodal large language models | CIREVL [6] |
|
|
|||||||
| CbIR [5] |
|
|
||||||||
| GRACE [4] |
|
|
||||||||
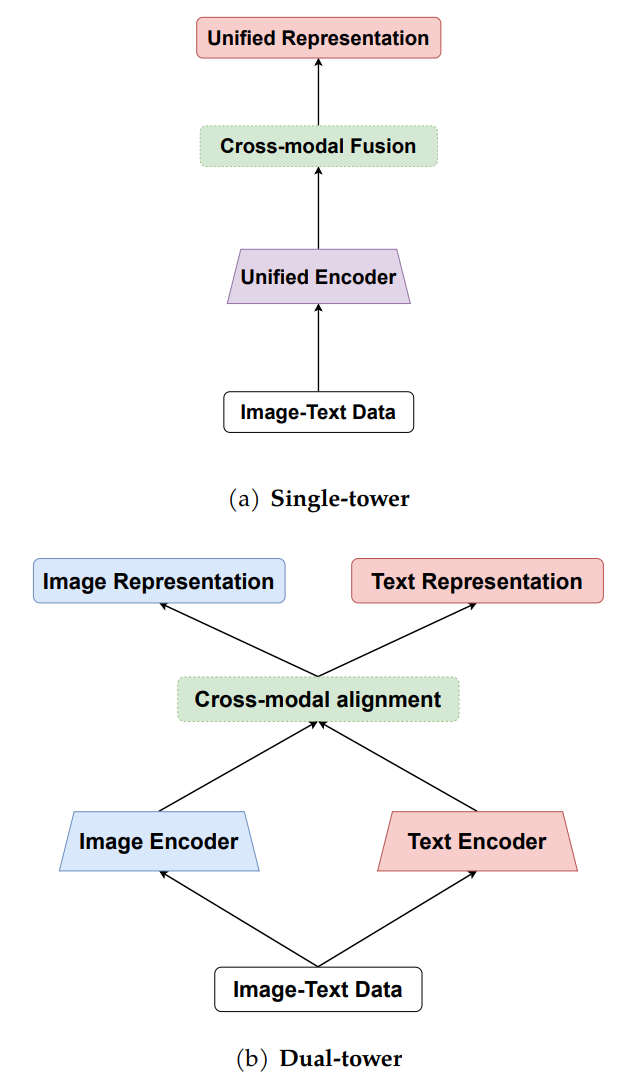
Single-tower (single-stream) architecture models process image and text features through a shared encoder, like a transformer, as shown in Figure 2 (a). These models usually combine the two input modalities early in the network and jointly process them through shared encoders. The main motivation behind single-tower models is their ability to directly learn joint representations of the two modalities, capturing complex interactions between them. By using shared layers to process both modalities together, these models aim to learn rich, fused representations that benefit cross-modal retrieval tasks.
In this review, we focus on the role of modality fusion in enhancing retrieval performance. Particularly, single-tower models exemplify early fusion by embedding image and text inputs into a unified semantic space through shared encoders. This strategy enables deeper interactions between modalities, yielding richer representations. Additionally, MLLM-based approaches, such as BLIP-2, implement hybrid fusion through modules like Q-Former, allowing semantic alignment across modalities at multiple stages.
The ViLT (Vision and Language Transformer) model [8] presents an innovative method for multi-modal training, drawing inspiration from the Vision Transformer (ViT) mechanism. In contrast to earlier methods that needed an object detector for region-level feature extraction, ViLT directly splits images into patches, performs linear embedding, and uses these as transformer inputs. Text data is also embedded and merged with image embeddings for joint training, significantly enhancing learning and inference efficiency. ViLT employs three pre-training objectives: Image-Text Matching (ITM), Masked Language Modeling (MLM), and Word Patch Alignment (WPA). For fine-tuning in cross-modal retrieval, ViLT initializes the similarity score head from the pre-trained ITM head and fine-tunes it with cross-entropy loss to maximize positive pair scores. Experimental results indicate that ViLT drastically reduces per-instance processing time from 900 milliseconds to 15 milliseconds, showcasing its efficiency and innovation in multi-modal learning.
Traditional pre-trained models for computer vision (CV) and natural language processing (NLP) perform well independently but face challenges with cross-modal tasks involving lengthy natural language inputs and intricate visual elements. Unicoder-VL [9] utilizes a multi-layer Transformer to learn joint representations of vision and language via cross-modal pre-training. It uses three tasks: MLM, Masked Object Classification (MOC), and Visual-linguistic Matching (VLM) The model processes linguistic and visual content simultaneously, effectively learning context-aware representations and predicting relationships between images and texts. Pre-training on large-scale image-caption pairs allows it to excel in downstream tasks such as image-text retrieval and visual commonsense reasoning. Unicoder-VL achieves state-of-the-art results in image-text retrieval on the MSCOCO and Flickr30K datasets, showcasing strong generalization abilities. However, its reliance on pre-training datasets might limit performance on tasks that require domain-specific knowledge.
A flexible model is needed to handle various vision-and-language tasks, capturing detailed semantics from both modalities without complex architectures. VisualBERT [10] integrates BERT with pre-trained object detection systems, processing image features and text together using Transformer layers. It is pre-trained on the COCO dataset using visually-grounded language model objectives such as masked language modeling and sentence-image prediction The model's design enables it to implicitly align language elements and image regions through self-attention, capturing intricate associations without explicit supervision. VisualBERT's design emphasizes simplicity and flexibility in handling diverse tasks.
Single-stream methods represent a powerful approach for cross-modal retrieval, leveraging unified Transformer architectures to effectively bridge the gap between different modalities. While these models perform well on general datasets, fine-tuning them for specific domains may require additional data and computational adjustments.
Dual-stream cross-modal methods, aim to integrate and process information from multiple modalities, such as text, images, and audio. These methods are characterized by their ability to handle the heterogeneity and complexity inherent in multimodal data, thereby facilitating a richer and more comprehensive understanding and generation of content. The primary challenge addressed by dual-stream cross-modal methods is the effective alignment and fusion of disparate data types, which often possess different structures, noise levels, and contextual nuances. The dual stream cross-modal approach typically involves two parallel processing streams, each dedicated to handling a specific modality, as shown in Figure 2 (b).
ViLBERT [11] aims to tackle the challenge of jointly understanding and reasoning about vision and language, which is difficult due to the inherent differences and complexities of each modality. It employs a two-stream model in which one stream processes visual information and the other processes linguistic information. These streams interact via a co-attentional Transformer layer that enables each modality to attend to the other. The key innovation is the co-attentional Transformer layer, which facilitates the interaction between visual and linguistic representations, allowing the model to learn rich, joint representations of both modalities.
CLIP [12] meets the need for models that can understand and connect images and text flexibly, particularly for zero-shot learning tasks where the model must generalize to new concepts without explicit training. CLIP employs separate encoders for images and text, training them with a contrastive loss to align image and text embeddings in a shared space. The model is trained on a vast dataset of images and their corresponding captions from the internet. The key innovation is using contrastive learning to align visual and textual representations, enabling the model to perform zero-shot learning by leveraging the rich, diverse data it was trained on. CLIP demonstrates impressive performance on various tasks without fine-tuning, including image classification, image-text retrieval, object detection, and generating text descriptions for images.
In [14], the authors introduce ALIGN (A Large-scale ImaGe and Noisy-text embedding), which utilizes a massive dataset of over one billion image-alt text pairs collected from the web with minimal filtering. The core of ALIGN is a straightforward dual-encoder architecture that employs contrastive learning to align visual and language representations in a shared embedding space. The ALIGN model uses a dual-encoder architecture with separate encoders for images and text. The encoders are trained with a contrastive loss to align the embeddings of matching image-text pairs. During training, the model applies simple frequency-based filtering on the dataset. The contrastive loss function helps in bringing together the embeddings of matched pairs and separating those of non-matched pairs. ALIGN achieves top-1 accuracy on ImageNet without using any of its training samples and sets new state-of-the-art results on Flickr30K and MSCOCO benchmarks. In addition to the basic dual-encoder designs, some recent studies further enhance retrieval quality by promoting representation diversity. For instance, Kim et al. [13] proposed a method that integrates a set of diverse embeddings to enrich the semantic space, improving the robustness of cross-modal retrieval across varying query intents and data distributions.
Dual-stream methods offer a robust framework for cross-modal retrieval by utilizing specialized pathways for different modalities and aligning their outputs in a shared space. By effectively aligning embeddings and using tailored processing, these models achieve strong performance in retrieving relevant content across heterogeneous data types, showcasing their value in multimodal applications.
Non-hashing methods based on real-valued representations effectively reduce the semantic gap between different modalities by learning dense feature representations, thereby enhancing retrieval precision. By employing deep learning methods to model features of various modalities and extract deep semantic features, these methods effectively address the issue of feature heterogeneity in cross-modal data. They also emphasize semantic correspondence between modalities, narrowing the semantic gap to improve the accuracy of cross-modal data matching, thereby increasing retrieval precision.
ACMR [15] tackles the challenge of aligning visual and textual data for cross-modal retrieval tasks, where traditional methods often fail to bridge the semantic gap between different modalities. The proposed solution involves employing adversarial training to learn robust cross-modal representations. Specifically, ACMR utilizes a dual-stream architecture where each modality is processed separately, with an adversarial loss to align the embeddings in a shared space. The key innovation of ACMR is the integration of adversarial learning, which encourages the model to produce modality-invariant features. This approach ensures that visual and textual representations are more closely aligned, thereby improving retrieval accuracy. ACMR significantly enhances the performance of cross-modal retrieval tasks, demonstrating improved alignment between visual and textual data and higher retrieval accuracy compared to non-adversarial methods. However, adversarial training can be complex and computationally intensive, and it may lead to potential instability during training.
DSCMR [16] addresses the challenge of learning effective representations for cross-modal retrieval tasks, where existing methods often struggle to capture the complex relationships between different modalities. The proposed solution employs a deep supervised approach that utilizes labeled data to learn discriminative features for each modality. DSCMR uses a dual-stream network with deep neural networks for both visual and textual data, supervised by a cross-modal ranking loss. The innovation in DSCMR lies in its application of deep supervision and a cross-modal ranking loss, ensuring that the learned representations are both discriminative and aligned across modalities. DSCMR achieves state-of-the-art performance in cross-modal retrieval tasks, showcasing the effectiveness of deep supervision and ranking-based training objectives in improving retrieval accuracy. However, DSCMR requires large amounts of labeled data and is potentially prone to overfitting to specific datasets.
IEFT [17] tackles the challenge of enhancing feature interactions for cross-modal retrieval, where traditional models often fail to fully capture the intricate relationships between visual and textual data. The proposed solution, Interacting-Enhancing Feature Transformer (IEFT), uses a Transformer-based architecture to enhance feature interactions between modalities. IEFT processes visual and textual features in separate streams and employs attention mechanisms to integrate them. The key innovation of IEFT is its use of Transformer-based attention mechanisms to enhance interactions between visual and textual features, allowing the model to learn richer and more nuanced representations. IEFT demonstrates superior performance on cross-modal retrieval benchmarks, benefiting from enhanced feature interactions and the powerful representation capabilities of Transformers.
COTS [18] addresses the difficulty of effectively combining visual and textual information for cross-modal retrieval, where existing methods may not fully leverage the potential of collaborative learning between modalities. The solution involves a Collaborative Two-Stream (COTS) architecture, where two streams process visual and textual data independently but collaborate through shared intermediate representations and alignment losses. The innovation in COTS lies in its collaborative learning mechanism, which ensures that the two streams not only process their respective modalities effectively but also learn from each other through shared representations. While collaborative learning enhances feature alignment and robust performance across various tasks, it increases complexity due to collaboration mechanisms and potential synchronization issues between streams.
TEAM [19] addresses the issue of aligning token embeddings from different modalities for cross-modal retrieval, where conventional methods may not fully capture the semantic relationships between visual and textual data. The proposed solution, Token Embeddings AlignMent (TEAM), employs alignment strategies to ensure that token embeddings from different modalities are closely related in a shared space. TEAM utilizes dual-stream networks with alignment losses to achieve this goal. TEAM's key innovation is its specific focus on token-level alignment, ensuring that individual tokens from text and corresponding visual elements are accurately aligned in the embedding space. TEAM significantly improves cross-modal retrieval performance by ensuring precise alignment of token embeddings, leading to better semantic understanding and retrieval accuracy. However, it incurs potentially high computational costs for fine-grained alignment and complexity in managing token-level interactions.
Real-valued cross-modal image-text retrieval methods based on deep learning use feature vectors directly obtained from feature extraction for modeling and retrieval. However, with the explosive growth of multimedia data, such as short videos on TikTok or image-text information on Weibo, multimodal data often reaches hundreds of thousands, millions, or even billions of instances. This requires that the retrieval process for multimodal data ensures both precision and efficiency. Among various retrieval methods, hashing methods have gained widespread attention due to their low storage cost, efficiency, and fast retrieval speed, making them more suitable for large-scale datasets.
Hashing methods map feature vectors from the original feature space to binary codes (Hamming space) to save storage space and increase retrieval speed while maintaining the similarity between data points during the mapping process. Subsequently, the Hamming distance between the hash codes of the query data and those in the database is calculated for similarity ranking, ultimately yielding the retrieval results. Calculating the Hamming distance is faster than other distance metrics such as Euclidean and cosine distances. Additionally, storing data as binary codes rather than real-valued ones reduces the storage requirements for retrieval tasks.
Learning hash functions mainly involves dimensionality reduction and quantization. Dimensionality reduction maps the information from the original space to a lower-dimensional space, such as mapping an image's original pixel space information to a lower-dimensional (e.g., tens of dimensions) representation. Quantization involves linear or nonlinear transformations of the original features and binary segmentation of the feature space to produce hash codes. As mentioned in the problem definition section of cross-modal retrieval, there is a semantic gap between different forms (modalities) of data representation. Minimizing this semantic gap remains a primary challenge for cross-modal retrieval hashing methods. Generally, there are two approaches to address this: one is learning a unified hash code, and the other is using supervised information, such as labels, to collaboratively represent and minimize the distance between hash codes of semantically relevant instances.
DCMH [20] addresses the challenge of efficiently retrieving relevant data across different modalities (e.g., text and images) by using hashing techniques to map high-dimensional data into compact binary codes. The proposed solution utilizes a deep learning framework to generate hash codes for each modality through learning shared representations. These representations are optimized to maintain semantic similarity across different modalities, ensuring related items have similar hash codes. This is the first use of deep hashing neural networks to learn these representations, allowing the model to capture complex relationships between modalities and generate more accurate hash codes.
UDCMH [21] addresses the challenge of cross-modal retrieval without labeled data, which is significant since traditional supervised methods rely heavily on labeled training examples. The key innovation is the unsupervised learning approach, which eliminates the need for labeled data and still achieves effective cross-modal retrieval by learning from the data's inherent structure. This approach demonstrates strong performance in cross-modal retrieval tasks, especially in scenarios where labeled data is scarce or unavailable. However, its performance may not match supervised methods on well-labeled datasets and may be sensitive to the quality of the data structure.
SSAH [22] tackles the challenge of generating robust hash codes for cross-modal retrieval by leveraging the advantages of both self-supervised learning and adversarial training. Self-supervised learning generates initial hash codes, while adversarial training refines these codes to ensure they are modality-invariant and semantically meaningful. This combination enables the model to learn effective representations without the need for extensive labeled data. SSAH achieves enhanced retrieval performance and robustness, demonstrating the effectiveness of its novel training strategy.
Bi-CMR [23] is the first to recognize that the assumption "label annotations reliably reflect instance relevance" conflicts with human perception. It proposes a new evaluation method to guide the learning of instance hash codes consistent with human perception. Bi-CMR introduces a novel bidirectional reinforcement-guided hashing method that reinforces hash code learning through mutual promotion. The key innovation is using reinforcement learning to dynamically adjust and improve the hashing process, ensuring the generated hash codes are effective for cross-modal retrieval. Bi-CMR demonstrates superior performance in cross-modal retrieval tasks, with hash codes that are well-aligned and optimized for retrieval accuracy.
DCHMT [24] tackles the challenge of effectively integrating and hashing data from multiple modalities using a unified framework. It constructs a multi-modal transformer to capture detailed cross-modal semantic information and introduces a micro-hashing module to map modal representations into hash codes. UCMFH tackles the need for effective cross-modal retrieval without labeled data, focusing on learning robust hash codes through unsupervised methods. The proposed solution uses unsupervised contrastive learning to generate hash codes. By leveraging contrastive learning, the model maximizes the similarity between related items across modalities while minimizing the similarity between unrelated items. UCMFH demonstrates strong performance in unsupervised cross-modal retrieval tasks, achieving high accuracy and robustness by effectively learning from the inherent structure of data.
Overall, real-valued representations are suitable for tasks that require high precision, while hashing representations are ideal for applications that need rapid, large-scale retrieval.
In the past two years, large language models (LLMs) have made significant strides, demonstrating the ability to perform many NLP downstream tasks in a zero-shot setting. However, their inference capabilities with data from other modalities have been limited. To address this gap, MLLMs have been proposed. These models are capable of not only generating and understanding complex text but also processing image information, allowing a single MLLM to handle multiple multimodal downstream tasks simultaneously. Utilizing MLLMs for image-text retrieval has emerged as a powerful and widely applied technique. By integrating natural language processing and computer vision technologies, MLLMs can efficiently extract information from vast datasets, achieving precise image-text matching and search.
Before introducing this section, we first differentiate between VLP models and MLLMs. We define VLP as a multimodal pre-training model tailored for specific tasks involving vision and language. In contrast, MLLMs are pre-trained models capable of addressing multiple complex reasoning tasks across different modalities. The key distinction lies in their ability to handle multiple downstream tasks. Therefore, VLP models are not classified within this section. Our categorization is based on the core components and capabilities of the models.
The process of using MLLMs for image-text retrieval generally includes the following steps:
Using an MLLM trained on large-scale data and fine-tuning it with an image-text retrieval dataset.
Employing specific prompts to complete the image-text retrieval task.
Involving smaller image-text retrieval models to assist the MLLM in the task.
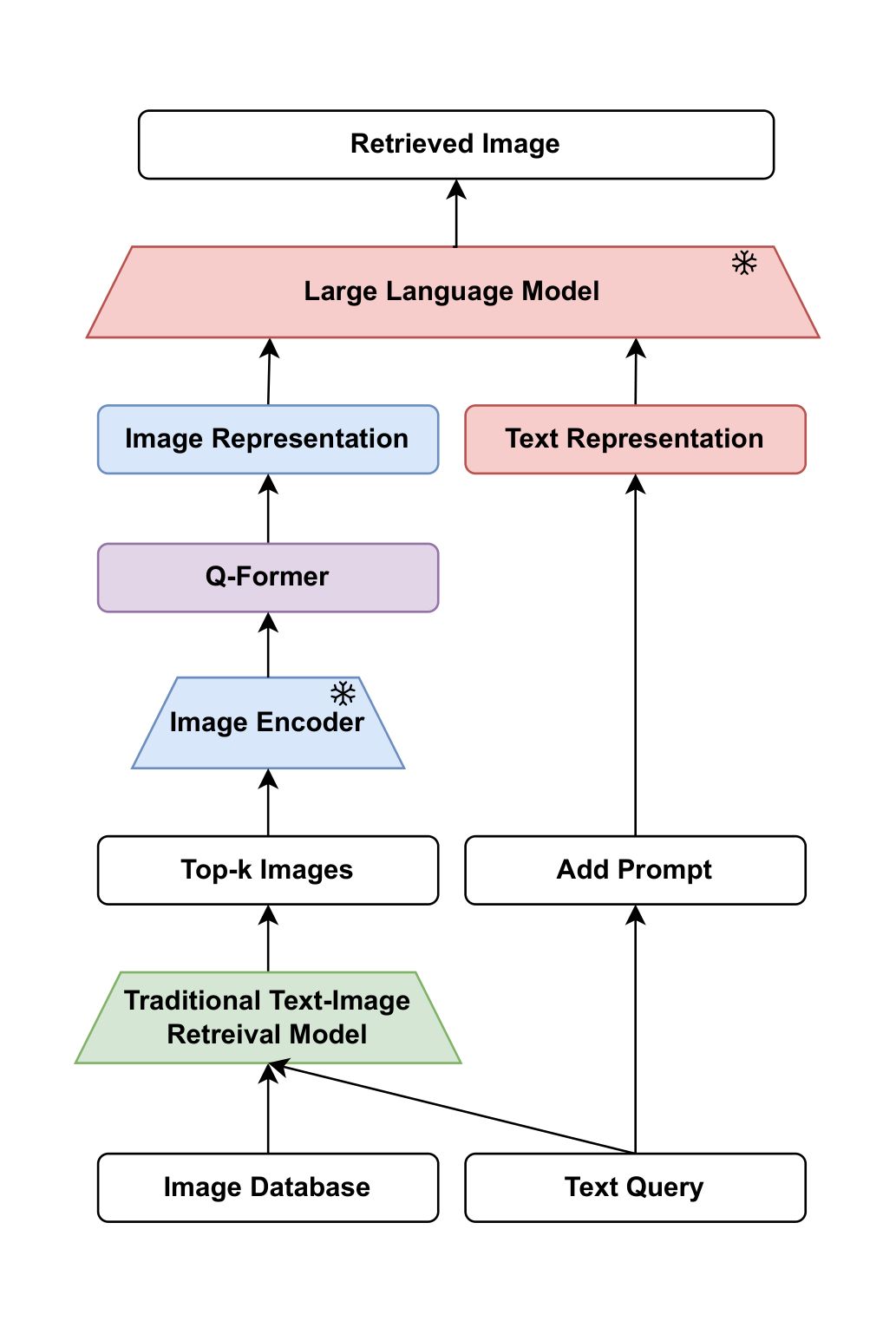
BLIP-2 [1] employs a bidirectional retrieval approach by leveraging pre-trained image models and large language models. The text-to-image retrieval pipeline used by BLIP-2 is illustrated in Figure 3. This pipeline is enhanced with Q-Former to bridge the gap between modalities, using a two-stage training process: initially training the image model, followed by the text model. The retrieval process begins with a common retrieval model selecting 128 candidate images based on image-text similarity. These candidate images, along with the query text, are then input into the model, which selects the most relevant image as the retrieval result. Essentially, this approach utilizes generative models to perform the retrieval task, ensuring accurate and efficient matching of images based on textual input.
InternLM [2] focuses solely on image retrieval. It involves fine-tuning both the Perceive Sampler and the MLLM, followed by fine-tuning Perceive Sampler with LoRA. Initially, CLIP is used to select the top-k candidate images, from which the MLLM selects one image as the final retrieved result. This approach, like the previous one, is fundamentally generative.
EIIRwQR [3] also focuses on image retrieval, utilizing a VLM to generate a set of candidate images. Each candidate image is described with a caption generated by an image description model. The MLLM takes the original query and these generated captions as input, modifying each query. The VLM then uses the modified queries for image retrieval. This process is iterated multiple times to refine the final retrieval result. The MLLM is employed only during the inference stage without any fine-tuning, categorizing this approach as using MLLMs for data augmentation.
CIREVL [6] focuses on image retrieval without any training process, addressing the high labor costs associated with annotated data. It employs an MLLM to transform the text into a fixed descriptive sentence format, which is then used by a traditional model for image retrieval. he MLLM is utilized only during the inference stage and is not fine-tuned, effectively categorizing this approach as using MLLMs for data augmentation.
In CbIR [5], dialogues are used as input. The accumulated dialogue information, processed with a contrastive loss function, fine-tunes the large model to obtain -dimensional retrieval vectors. These vectors are then compared with -dimensional image vectors using cosine similarity to retrieve the images.
GRACE [4] involves assigning each image a unique image token and training the instruction to predict the identifier for the
In fact, aside from the methods mentioned above, most MLLMs can potentially be employed for image-text retrieval tasks, although many of these models have not been specifically tested for this purpose. Additionally, existing MLLM methods tested for image-text retrieval typically involve LLMs trained solely on text data. However, there are models like Google's Gemini [7], which are inherently multimodal. Instead of a two-stage process where the model is first trained on text and then on images, these models are pre-trained on multimodal data from the beginning. Such inherently multimodal models exhibit greater adaptability and robustness with multimodal data. Future exploration of these native multimodal LLMs may further enhance the performance of image-text retrieval.
In summary, the existing works highlight various approaches to utilizing MLLMs for image-text retrieval. The methods range from leveraging pre-trained models and fine-tuning specific components to employing generative techniques and using MLLMs for data augmentation without additional training. These diverse strategies underscore the flexibility and potential of MLLMs in enhancing image-text retrieval tasks, paving the way for more accurate and efficient retrieval systems in the future.
The researchers have proposed various datasets for cross-modal image-text retrieval, including Wikipedia [25], NUS-WIDE [26], TC-12 [27], Flickr [28], Pascal Sentence [29], etc. The most frequently used datasets are summarized as MSCOCO [30] and Flickr30K [28]. MS COCO dataset contains images from the Microsoft Common Objects in Context (COCO) dataset, each paired with five human-generated textual captions. After removing rare words, the average caption length is words. The dataset is divided into training image-text pairs, validation pairs, and test pairs. Model evaluations are conducted on five folds of test pairs and the entire set of test pairs. Flickr30K0 comprising images sourced from the Flickr website, each image in this dataset is annotated with five textual descriptions. The dataset is split into three sections: image-text pairs for validation, pairs for testing, and the remaining for training.
| Task | Methods | Source | Wikipedia | Pascal-Sentence | NUS-WIDE | Xmedia |
|---|---|---|---|---|---|---|
| ACMR [15] | ACM MM17 | 0.468 | 0.538 | 0.519 | 0.536 | |
| IqT | CM-GANS [32] | TMM18 | 0.521 | 0.603 | 0.536 | 0.567 |
| DSCMR [16] | CVPR19 | 0.521 | 0.674 | 0.611 | 0.697 | |
| AGCN [33] | IEEE CSVT22 | 0.620 | 0.683 | - | - | |
| CLIP4CMR [34] | ARXIV22 | 0.592 | 0.698 | 0.609 | 0.746 | |
| ACMR [15] | ACM MM17 | 0.412 | 0.544 | 0.542 | 0.519 | |
| IqT | CM-GANS [32] | TMM18 | 0.466 | 0.604 | 0.551 | 0.551 |
| DSCMR [16] | CVPR19 | 0.478 | 0.682 | 0.615 | 0.693 | |
| AGCN [33] | IEEE CSVT22 | 0.532 | 0.683 | - | - | |
| CLIP4CMR [34] | ARXIV22 | 0.574 | 0.692 | 0.621 | 0.758 |
| Task | Methods | Source | MirFlickr | NUS-WIDE | MS COCO | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 16bits | 32bits | 64bits | 16bits | 32bits | 64bits | 16bits | 32bits | 64bits | |||
| DCMH [20] | CVPR17 | 0.724 | 0.731 | 0.731 | 0.568 | 0.561 | 0.596 | 0.505 | 0.536 | 0.557 | |
| IqT | SSAH [22] | CVPR18 | 0.903 | 0.922 | 0.925 | 0.691 | 0.727 | 0.728 | 0.632 | 0.669 | 0.668 |
| DCHUC [35] | TKDE20 | 0.895 | 0.916 | 0.926 | 0.707 | 0.672 | 0.738 | 0.513 | 0.550 | 0.558 | |
| HMAH [31] | TMM23 | 0.960 | 0.965 | 0.969 | 0.813 | 0.825 | 0.840 | 0.691 | 0.732 | 0.763 | |
| DSPH [36] | TCSVT23 | 0.925 | 0.940 | 0.945 | 0.852 | 0.905 | 0.929 | 0.793 | 0.815 | 0.833 | |
| DCMH [20] | CVPR17 | 0.764 | 0.749 | 0.780 | 0.558 | 0.591 | 0.616 | 0.549 | 0.572 | 0.605 | |
| TqI | SSAH [22] | CVPR18 | 0.896 | 0.906 | 0.915 | 0.658 | 0.673 | 0.666 | 0.583 | 0.556 | 0.664 |
| DCHUC [35] | TKDE20 | 0.764 | 0.749 | 0.780 | 0.558 | 0.591 | 0.616 | 0.549 | 0.572 | 0.605 | |
| HMAH [31] | TMM23 | 0.915 | 0.925 | 0.938 | 0.783 | 0.796 | 0.814 | 0.800 | 0.869 | 0.904 | |
| DSPH [36] | TCSVT23 | 0.897 | 0.904 | 0.911 | 0.859 | 0.920 | 0.935 | 0.792 | 0.800 | 0.819 | |
We summarize the following evaluation metrics widely used to assess cross-modal retrieval tasks: Mean Average Precision@K (MAP@K): MAP calculates the average precision for each query and then averages these values over all queries. In the experimental validation of MLLMs, the R@n metric is commonly used, indicating the proportion of queries for which at least one correct result is retrieved within the top-n results.
| Task | Methods | Source | Flickr30K | MS-COCO(5K) | ||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| IqT | AGREE (FT only) [39] | WSDM23 | 0.916 | 0.987 | 0.992 | - | - | - |
| AGREE [39] | 0.921 | 0.987 | 0.992 | - | - | - | ||
| BLIP-2 ViT-L [1] | ICML23 | 0.969 | 1.000 | 1.000 | 0.835 | 0.960 | 0.980 | |
| BLIP-2 ViT-g [1] | 0.976 | 1.000 | 1.000 | 0.854 | 0.970 | 0.985 | ||
| TqI | GRACE [4] | ARXIV24 | 0.684 | 0.889 | 0.937 | 0.415 | 0.691 | 0.791 |
| AGREE (FT only) [39] | WSDM23 | 0.781 | 0.951 | 0.978 | - | - | - | |
| AGREE [39] | 0.828 | 0.959 | 0.978 | - | - | - | ||
| BLIP-2 ViT-L [1] | ICML23 | 0.886 | 0.976 | 0.989 | 0.663 | 0.865 | 0.918 | |
| BLIP-2 ViT-g [1] | 0.897 | 0.981 | 0.989 | 0.683 | 0.877 | 0.926 | ||
In this section, we present the accuracy of several representative methods in cross-modal retrieval tasks. As shown in Tables 2- 4, we compare the accuracy of cross-modal retrieval methods using common measures for each task. Based on the presented performance, we can summarize the following observations:
As shown in Table 2, in cross-modal real-valued retrieval, methods based on VLP (Vision-Language Pre-training) or transformer structures often achieve better accuracy. This improvement is due to the enhanced ability of encoders to extract semantic information, as demonstrated by the performance of CLIP4CMR.
As shown in Table 3, cross-modal hashing retrieval methods exhibit progressive accuracy with different hash code lengths. Most methods show an increase in accuracy as the code length increases, indicating that longer codes can represent more semantic information, thereby improving retrieval accuracy. However, the accuracy improvement from 32-bit to 64-bit codes is often not as significant as the improvement from 16-bit to 32-bit codes. This may be because once an optimal hash code length is achieved, longer vector lengths do not provide additional valuable semantic information for retrieval.
As shown in Table 4, the experimental results of MLLMs demonstrate that most methods can retrieve the correct result within the top-5 results. Some models even achieve a 100% recall rate on the validation set. These results highlight that training or fine-tuning MLLMs on large-scale language and image datasets enables the models to capture subtle details and semantic variations in both text and images. This approach not only enhances the models' generalization capabilities but also reduces the dependency on large amounts of annotated data, a significant advantage over traditional models. However, this benefit comes at the cost of requiring substantially more computational resources for training and inference due to the large number of parameters in these models.
This survey has comprehensively reviewed the field of cross-modal image-text retrieval, categorizing existing methods and highlighting their strengths and limitations. Current cross-modal retrieval methods can be broadly classified into single-tower, dual-tower, real-value representation, and binary representation models.
1) Summary of Existing Methods. Single-tower models integrate modalities early, learning joint representations that capture complex interactions. Their unified architecture, however, may struggle with scalability and efficient fusion of different data types. Dual-tower models process each modality separately through specialized architectures, enhancing scalability and tailored processing. Yet, they face challenges in ensuring compatibility between separately learned representations. Real-value representation models encode data into continuous, high-dimensional vectors, effectively capturing detailed and complex relationships. Despite their accuracy, they are computationally intensive and costly in terms of storage, making them less suitable for large-scale applications. Binary representation models use compact, fixed-length binary codes for data encoding, offering efficient storage and fast retrieval. These models are ideal for large-scale databases but often trade-off some accuracy and require sophisticated techniques to learn effective binary codes.
2) Advantages and Problems. Advantages: Single-tower models. Effective in capturing intricate interactions between modalities. Dual-tower models. Highly scalable and adaptable to specialized processing needs. Real-value representation models. High accuracy in representing complex relationships. Binary representation models. Efficient in storage and fast in retrieval, suitable for large datasets.
Problems: Single-tower models. Scalability issues and challenges in modality fusion. Dual-tower models. Difficulty in ensuring compatibility of learned representations. Real-value representation models. High computational and storage costs. Binary representation models. Potential loss of accuracy and complexity in learning effective binary codes.
3) Future Directions. To advance the field of cross-modal retrieval, future research should focus on several key areas: 1. Improving Model Compatibility and Fusion: Developing hybrid models that leverage the strengths of both single-tower and dual-tower architectures to enhance compatibility and fusion efficiency. 2. Enhancing Computational Efficiency: Designing novel methods that reduce computational and storage demands of real-value representation models without compromising accuracy. 3. Advanced Binary Coding Techniques: Innovating more sophisticated binary coding methods that balance accuracy and efficiency, making them viable for large-scale applications. 4. Leveraging Multimodal Large Language Models (MLLMs): Further exploring the potential of MLLMs in enhancing cross-modal retrieval tasks, particularly in improving semantic understanding and retrieval accuracy. 5. Comprehensive Benchmarking: Establishing more robust benchmarking frameworks that include diverse datasets and comprehensive evaluation metrics to better assess model performance. 6. Addressing Scalability and Real-world Applications: Developing scalable solutions that can handle real-world data complexities and large-scale multimodal databases, ensuring the practical applicability of cross-modal retrieval systems.
By addressing these challenges and focusing on these future directions, the field of cross-modal image-text retrieval can achieve more robust, efficient, and accurate systems, enhancing the practical utility of these technologies in various real-world applications.
 Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/