
ICCK Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3068-6652 (Online)
Email: [email protected]

Topic modeling methods are unsupervised techniques used to uncover hidden topics within documents and are widely applied across various domains [1]. In other words, topic modeling is a powerful natural language processing (NLP) technique for discovering latent themes in large text collections [2].
Traditional techniques such as Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF) often possess limited contextual understanding and fail to fully capture the semantic depth of language [3]. To overcome these limitations, Large Language Models (LLMs) have recently emerged as an innovative approach in topic modeling. Models like GPT, Claude, and Gemini possess the ability to produce semantically rich topics, thanks to their contextual comprehension capabilities, going beyond purely statistical methods [4].
However, there is still a lack of systematic and comprehensive comparative analyses of these models in the context of topic modeling in the current literature [6]. Especially in domains such as healthcare, where accuracy and explainability are critical, it is essential to analyze in detail how consistent, diverse, and interpretable the topics generated by these models truly are.
One of the main reasons for this gap is that LLM-based topic modeling remains a relatively new research area. Additionally, the lack of standardized evaluation metrics across different models further contributes to this issue [7].
Addressing this gap, the present study provides one of the first systematic analyses that compares the topic modeling performance of ten different LLMs in the healthcare domain. Unlike traditional embedding-based approaches, this study adopts a prompt-guided strategy tailored for each model.
Specifically, the study compares the topic modeling performance of ten LLMs (GPT, Gemini, LLaMA, Qwen, Phi, Zephyr, DeepSeek, NVIDIA-LLaMA, Gemma, Claude) on a corpus of 9,320 academic articles in the healthcare field using prompt-based methods. By employing metrics such as diversity, relevance, cosine similarity, and entropy, the strengths and weaknesses of each model are revealed from both qualitative and quantitative perspectives.
Pham et al. [8] introduced a prompt-based framework called TopicGPT, aiming to enhance the topic modeling capabilities of LLMs. This framework generates more interpretable topics by incorporating natural language labels and descriptions, enabling users to exert greater control over model outputs.
Wang et al. [9] proposed an approach named PromptTopic, which seeks to improve the performance of LLMs in modeling topics from short texts. This method enables sentence-level topic inference, resulting in more coherent and meaningful topics.
Tan et al. [7] conducted an automatic evaluation of dynamically evolving topic taxonomies using LLMs. Their study demonstrated that LLMs could assess topic quality through metrics such as consistency, redundancy, diversity, and topic-document alignment, offering an alternative to traditional human-centric evaluation methods.
Another study utilizing LLMs, conducted by Çelikten et al. [34], performed topic modeling on scientific texts generated by both humans and AI. In this work, semantic representations of the texts were obtained using large language models, and prominent topics were identified through a rank-based aggregation method. The approach enables a comparative analysis of the thematic structure across texts from different sources.
Isonuma et al. [10] quantitatively evaluated the topic modeling performance of LLMs. Their findings showed that while LLMs are capable of generating consistent and diverse topics, they sometimes take "shortcuts" by focusing on specific sections of documents, thereby limiting controllability.
Arora et al. [11] developed an open-source benchmark called HealthBench to assess the performance and safety of LLMs in the healthcare domain. The benchmark comprises 5,000 multi-turn dialogues and evaluates LLM competencies in health-related tasks.
Asmussen et al. [6] emphasized the challenges of traditional LDA-based literature reviews, such as high topic redundancy and low topic distinctiveness. These issues underscore the need for more advanced modeling approaches.
In addition to LLM-based topic modeling approaches, Onan et al. [31] investigated the coherence and diversity of AI-generated and paraphrased scientific abstracts using a fuzzy topic modeling method. Their work allows for a more flexible and realistic representation of multi-topic scientific texts, providing a novel perspective for assessing the quality of AI-generated content.
Rosenfeld et al. [5] compared the generation styles of different LLMs to identify which models produce more consistent and original texts. Their assessment highlighted LLMs' sensitivity to linguistic structures and stylistic differences.Topic modeling has long been employed to uncover latent themes in text corpora. One of the most well-known techniques in this domain is LDA [14], which infers hidden topic structures based on word distributions in documents. Other methods, such as NMF [12] and the Hierarchical Dirichlet Process (HDP) [13], have also been used, each incorporating different assumptions and structures. However, these techniques often rely on word co-occurrence frequencies and tend to produce semantically shallow representations due to their lack of contextual understanding.
Topic modeling has long served as a fundamental unsupervised learning technique for uncovering latent semantic structures in large-scale text corpora. Classical statistical methods such as Latent Dirichlet Allocation (LDA) [14], Non-negative Matrix Factorization (NMF) [12], and Hierarchical Dirichlet Process (HDP) [13] have dominated early research, relying on word co-occurrence statistics and often yielding topics with limited contextual depth and interpretability.
To overcome these limitations, recent research has turned to leveraging the contextual understanding of large language models (LLMs) for topic modeling. One of the earliest frameworks in this direction, TopicGPT by Pham et al. [8], introduced a prompt-based architecture to steer LLMs toward more coherent and interpretable topic generation. Similarly, LLM-TAKE [3] focused on theme-aware keyword extraction using encoder-decoder LLMs, enabling finer semantic control in topic formulation.
Other innovations have explored architectural enhancements and evaluation perspectives. DeTiME [1] proposed a diffusion-based encoder-decoder approach to refine topic representations generated by LLMs. In parallel, Kapoor et al. [4] introduced QualIT, a framework that augments LLM-based topic modeling with qualitative insight metrics to enhance interpretability and user alignment.
Evaluation of topic quality remains a challenge. Tan et al. [7] highlighted the inconsistency of traditional metrics and proposed a taxonomy-aware framework for evaluating LLM-generated topics using coherence, redundancy, and alignment metrics.
A related study by Isonuma et al. [10] quantitatively benchmarked LLMs for topic modeling using metrics such as topic diversity, specificity, and controllability, echoing the need for systematic multi-model comparisons. Likewise, Çelikten et al. [34] presented a rank-based aggregation method for comparing human- and AI-generated scientific text structures using LLM embeddings.
While these works mark significant progress, most focus on individual models or specific tasks such as keyword extraction or label generation. To our knowledge, no prior study has conducted a domain-specific, head-to-head comparative evaluation of multiple LLMs in the context of full-topic modeling, particularly within critical domains such as healthcare where interpretability, precision, and semantic grounding are paramount.
This study addresses this gap by systematically comparing the topic modeling performance of ten state-of-the-art LLMs using both qualitative and quantitative metrics on a corpus of over 9,000 healthcare-related article abstracts. Our contribution lies not only in breadth—covering a diverse set of models (e.g., GPT, Claude, Zephyr, Phi, LLaMA)—but also in our use of application-aligned metrics and structured evaluation methodology to assess model strengths and limitations across multiple dimensions.
In this study, the performance of LLMs in the context of topic modeling is systematically compared.
Unlike traditional topic modeling approaches, this study treats each article abstract as an independent data unit rather than processing the entire dataset at once. Accordingly, the experimental design is based on providing individual prompts to LLMs for each abstract.
The dataset consists of a total of 9,320 academic articles from the healthcare domain, each analyzed using ten different LLM models. Each model generated five topic models per article, and the resulting outputs were evaluated using both qualitative and quantitative criteria. Algorithm 1 outlines the sequential steps followed throughout the study.
Data: A total of 9,320 academic articles from the healthcare domain
Result: Five topics generated by each of the ten LLMs per article and corresponding performance evaluation results
foreach Article ArticleSet do
foreach LLM {GPT, Claude, Gemini, LLaMA, Qwen, Phi, Zephyr, DeepSeek, NVIDIA-LLaMA, Gemma} do
Run the LLM with the specified prompt;
Save the five generated topics;
end foreach
end foreach
foreach Set of topics generated for each article do
foreach LLM Models do
Measure Diversity and Relevance scores;
Perform Entropy calculation;
Generate topic vectors and calculate Cosine Similarity;
end foreach
end foreach
This section introduces the topic modeling approach Section 3.1. The dataset used in the experiments and the data preparation process are described in Section 3.2. Experimental details and the use of large language models for topic modeling are presented in Section 3.3.
Topic modeling is a statistical method used to uncover hidden themes within large text corpora. It aims to classify documents into topics by analyzing word patterns. One of the most widely used approaches is the LDA model [32].
This technique is particularly common in the analysis and classification of semantic structures across documents. LDA, one of the best-known topic modeling methods, assumes that each document is a mixture of multiple topics and that each topic is represented by a distribution over specific words. This allows documents to be meaningfully grouped based on their content and enables the extraction of underlying themes [14].
Topic modeling facilitates the extraction of meaningful information clusters from large-scale text data sources such as digital archives, news websites, social media content, and academic publications, without the need for time-consuming manual labeling or classification. Consequently, it enhances user access to relevant information and enables deeper content analysis. In data-intensive domains such as healthcare, education, and law, topic modeling also contributes to the development of decision support systems [29].
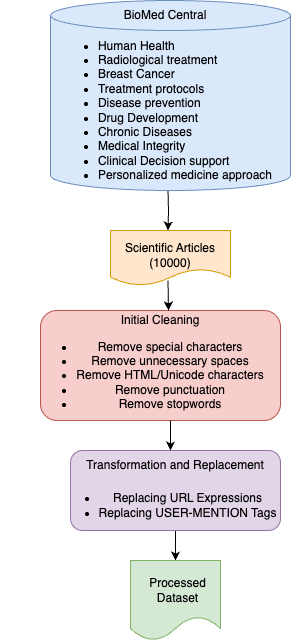
In this study, scientific article data were programmatically collected from the BioMed Central (BMC) [39] platform using the Python programming language and the Selenium library. During the data collection process, ten different medical themes were targeted, and approximately 1,000 articles were retrieved for each theme. The targeted themes are as follows: Human Health, Radiological Treatment, Breast Cancer, Treatment Protocols, Disease Prevention, Drug Development, Chronic Diseases, Medical Imaging, Clinical Decision Support Systems, and Personalized Medicine Approaches.
Unlike traditional data preprocessing approaches, this method performs independent evaluation for each text instance, thereby allowing the NLP capabilities of LLMs to be assessed on a more individual level. This structure enhances the comparability and explainability of the topic modeling performance across different LLM models.
To transform the data into a format that can be understood and processed by the models, a multi-step preprocessing pipeline was implemented, as summarized in Figure 1. Following the preprocessing stage, duplicate entries were removed, and corrupted or structurally inconsistent samples were filtered out during the cleaning phase. As a result, a total of 9,320 data instances were prepared for the experiments.
The following ten LLMs were used on the same collection of articles: GPT (OpenAI), Claude (Anthropic), Gemini (Google), LLaMA (Meta), Qwen, Phi (Microsoft), Zephyr, DeepSeek, NVIDIA LLaMA, and Gemma.
Each model was provided with a similar prompt structure, and parameters such as output length and temperature were held constant to ensure comparability across model outputs.
Developed by OpenAI, the GPT series has gained significant prominence in the field of NLP. GPT-4 is a multimodal model capable of processing both text and visual inputs, and it demonstrates human-level performance across various professional and academic benchmarks [15].
Anthropic's Claude model is developed with a strong focus on safety and transparency. Claude 2.0 exhibits high performance in real-world tasks, and research on its inner workings has revealed how millions of concepts are represented within the model [16].
Gemini, developed by Google DeepMind, is a family of multimodal models capable of processing text, images, audio, and video. The Gemini models are offered in various configurations (Ultra, Pro, Nano) and demonstrate superior performance across a range of tasks [17].
Meta's LLaMA series offers open-source and efficient LLMs. LLaMA 3 is equipped with capabilities such as multilingual support, coding, and logical reasoning, and it performs well across various benchmarks [18].
Qwen, developed by Alibaba, is a comprehensive language model series available in different parameter sizes. Qwen models have demonstrated effective performance across a variety of NLP tasks [19].
Microsoft's Phi series aims to deliver high performance with relatively small model sizes. The Phi-3-mini model, with 3.8 billion parameters, achieves results comparable to much larger models [20].
Zephyr is a project aimed at developing compact language models aligned with user intent. Trained using the Distilled Supervised Fine-Tuning (dSFT) method, Zephyr models perform effectively across a range of tasks [21].
Developed by DeepSeek-AI, DeepSeek provides open-source LLMs. The DeepSeek LLM 67B model demonstrates strong performance particularly in tasks involving coding, mathematics, and logical reasoning [22].
NVIDIA has extended the capabilities of LLaMA models by enabling the construction of 3D networks, allowing the models to understand and generate 3D objects. This approach bridges the gap between language processing and 3D modeling [23].
Gemma is an open-source model family developed by Google, based on the research and technology behind Gemini. Gemma models show strong performance in tasks related to language understanding, logical reasoning, and safety [24].
It is important to note that the ten LLMs included in this study vary in terms of their exposure to domain-specific training data. Models such as GPT-4 (OpenAI) and Claude 2.0 (Anthropic) have been evaluated on biomedical benchmarks and are known to exhibit strong reasoning capabilities in health-related contexts. In contrast, models like Zephyr and Phi have not been explicitly fine-tuned on medical corpora but were included to assess how general-purpose LLMs perform on domain-specific tasks. This distinction allows us to explore whether domain alignment significantly influences topic modeling outcomes in the healthcare setting.
A prompt-based approach was adopted to leverage the semantic capacity of each model. The methodology followed in this study is illustrated in Figure 2. Accordingly, each model was presented with explicit prompts instructing it to generate "five short, meaningful, and original topics" based on the given abstract.

Figure 3 presents the common prompt employed in the experiments along with a sample input, while Figure 4 shows the corresponding output generated based on that input.

The results were obtained individually for each LLM, and these outputs were evaluated using the following metrics: Diversity, Relevance, Cosine Similarity, and Entropy.
Diversity: In topic modeling, diversity is a key metric that measures how distinct the generated topics are from one another [25, 30].
According to this definition, the top-ranked words from all topics are aggregated, and the proportion of non-repeating (unique) words is calculated. The diversity metric is mathematically formulated as shown in Eq 1:
= total number of topics,
= number of top words selected from each topic,
= set of the top words in the -th topic.
To compute the diversity metric in practice, we extracted the top representative words from each of the topics generated for a given article by a particular model. We then calculated the proportion of unique words across these words. This yields a normalized score between 0 and 1, where a higher score indicates greater lexical variation and thematic diversity among the generated topics. For example, if 42 out of the 50 words are unique across five topics, the diversity score would be 0.84. This metric captures how well a model differentiates the topics it generates, thereby reflecting its capacity for semantic breadth.
A higher diversity value indicates that the topics are more unique and varied. In contrast, a low diversity score suggests significant overlap and repetition among topics, implying that the model fails to sufficiently distinguish between different themes. Therefore, the diversity metric plays a crucial role in evaluating the quality of topic modeling.
Relevance: In topic modeling, relevance is a metric used to determine how specific a word is to a given topic and to what extent it represents that topic. This metric reduces the influence of frequently occurring but non-topic-specific words, thereby enhancing the interpretability and meaningfulness of the generated topics. A vector-based similarity analysis was performed between topic sets generated by different models for the same article. This analysis employed embedding models based on Sentence-BERT [26]. According to this definition, the relevance of a word to a topic is calculated using the formula shown in Eq 2:
: The probability of word within topic .
: The overall probability of word in the entire corpus.
: A balancing parameter between 0 and 1. As approaches 1, more weight is given to the word's probability within the topic; as it approaches 0, more emphasis is placed on the word's topic specificity (lift).
This relevance metric was originally introduced by Sievert and Shirley [26] in the LDAvis framework to enhance topic interpretability by balancing term probability and distinctiveness (lift).
The relevance metric is particularly useful in visualization tools such as pyLDAvis, as it contributes to making topics more meaningful and interpretable. A high relevance score indicates that a word is specific to a given topic and represents it well. In contrast, a low relevance score suggests that the word is commonly used across the corpus but is not specific to any particular topic, making it less effective in representing that topic.
Therefore, the relevance metric is a valuable tool for enhancing the quality of topic modeling and ensuring the interpretability of the resulting topics.
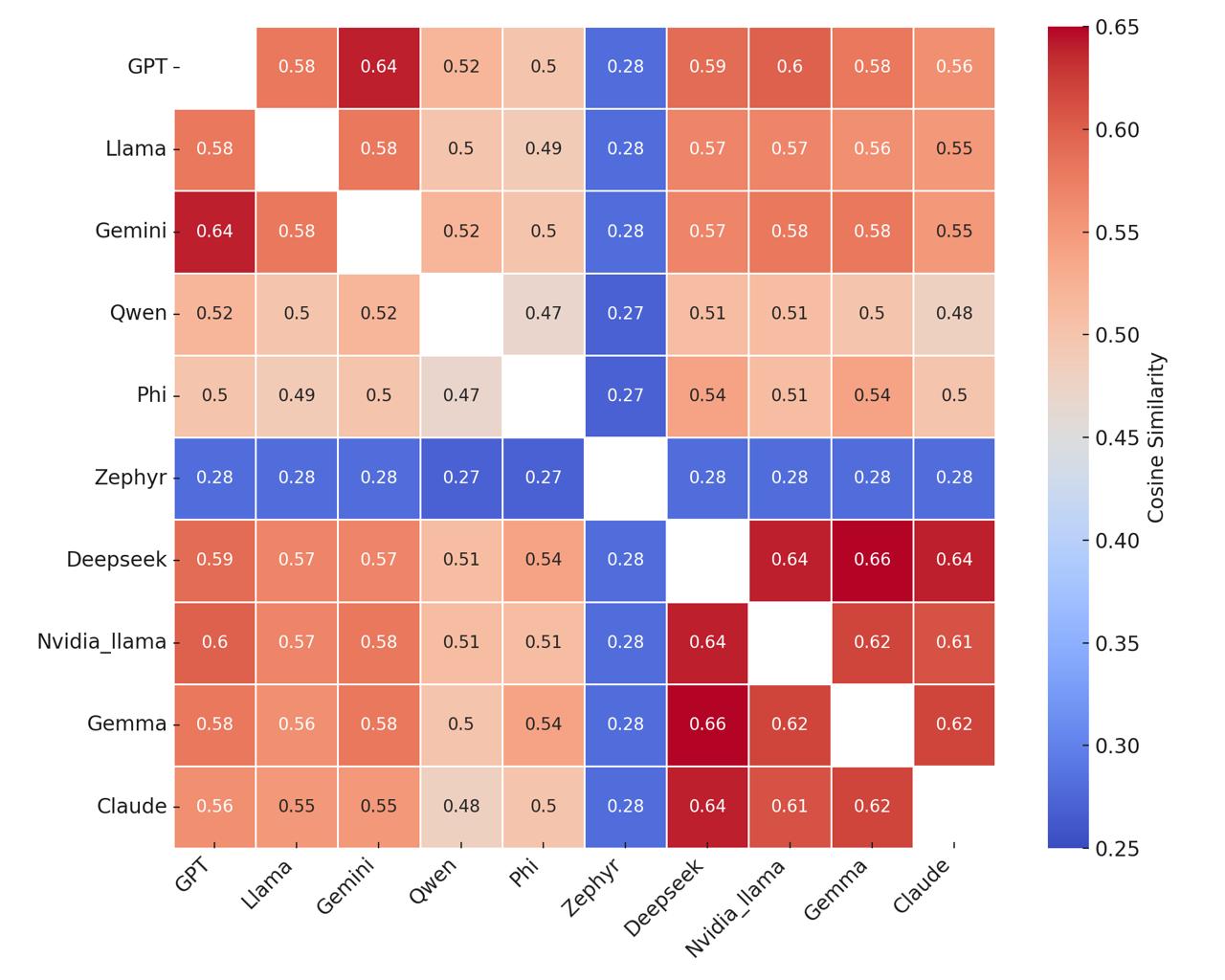
Cosine Similarity: In topic modeling, cosine similarity is a widely used metric for measuring the similarity between two topics. This metric calculates the cosine of the angle between two vectors, which indicates how similar their directions are. In the context of topic modeling, each topic is represented as a distribution over words, and these distributions can be expressed as vectors [27]. Mathematically, the cosine similarity between two vectors and is computed using Eq 3:
and : The two vectors being compared.
and : The -th components of vectors and , respectively.
: The dot product of the two vectors.
and : The norms (magnitudes) of vectors and .
Cosine similarity is a standard metric in NLP and information retrieval for comparing vectorized text representations [27]. In the context of topic modeling, it serves as an effective means of quantifying semantic overlap between topic-word distributions.
Cosine similarity ranges from -1 to 1. However, since the vectors used in topic modeling typically contain non-negative values, the effective range becomes 0 to 1. A value close to 1 indicates that the vectors (topics) are highly similar, while a value close to 0 implies that the vectors are significantly different from one another.
In topic modeling, cosine similarity plays a crucial role in comparing topics generated by different models, tracking the evolution of topics over time, and clustering similar topics. A high cosine similarity suggests that two topics share similar themes, whereas a low similarity indicates that the topics are associated with distinct thematic content.
Entropy: In topic modeling, entropy is a metric used to measure the uncertainty or dispersion of a topic's word distribution. This metric is particularly useful for evaluating how distinct or specific a topic is. The entropy value is calculated using the formula as Eq [28]:
: The entropy of topic .
: The entire vocabulary.
: The probability of word within topic .
: The base of the logarithm (commonly 2, , or 10).
In topic modeling, the entropy metric plays a significant role in assessing the distinctiveness and interpretability of topics. A low entropy value indicates that the topic is more specific and well-defined, while a high entropy value suggests that the topic is more general and ambiguous.
The evaluation process was conducted using the Python programming language. The analysis utilized several libraries, including transformers, scikit-learn, numpy, pandas, and sentence-transformers [33, 35, 36, 37, 38].
Access to the LLM models was provided through Hugging Face and OpenAI APIs [33, 15].
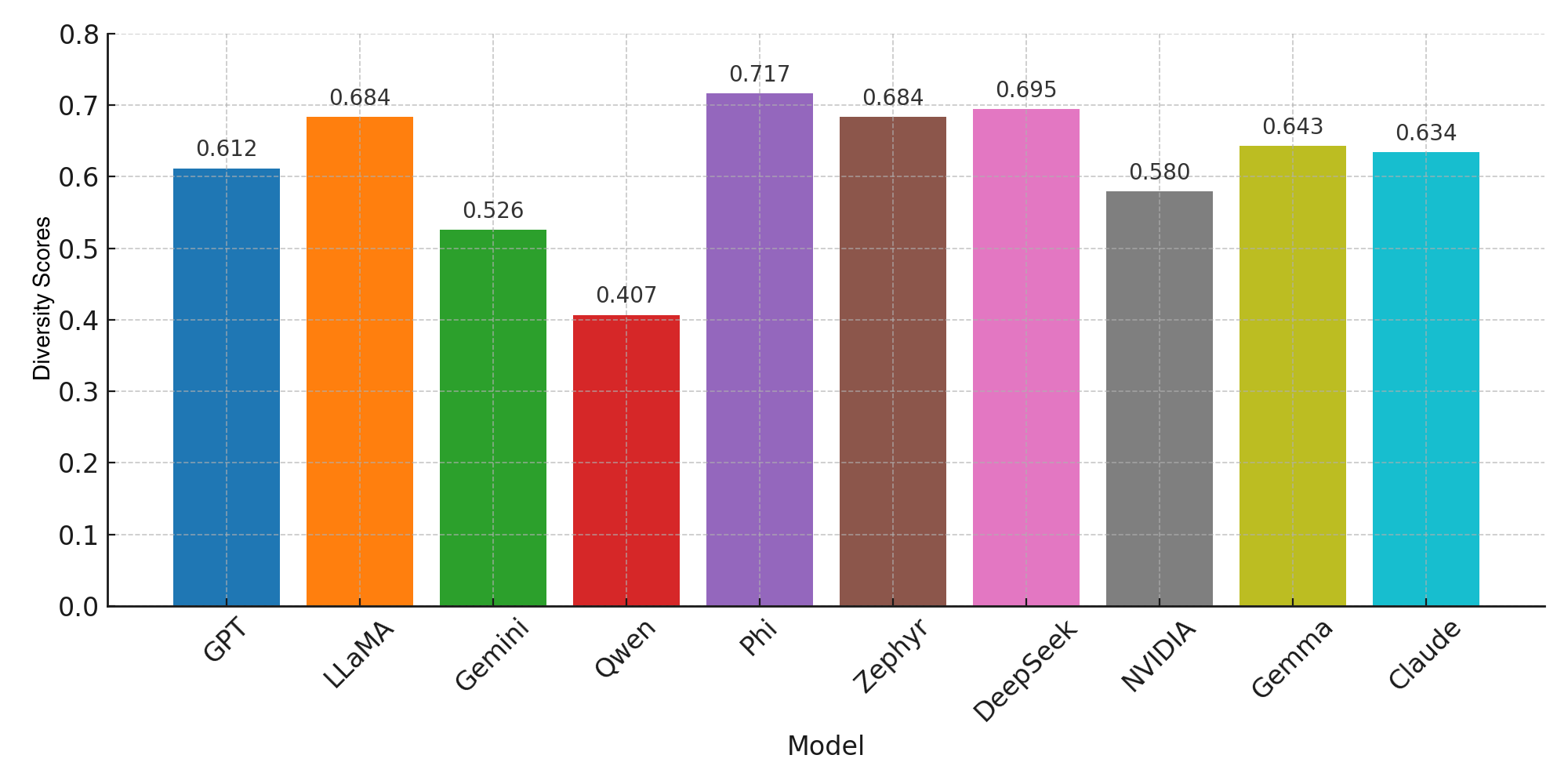
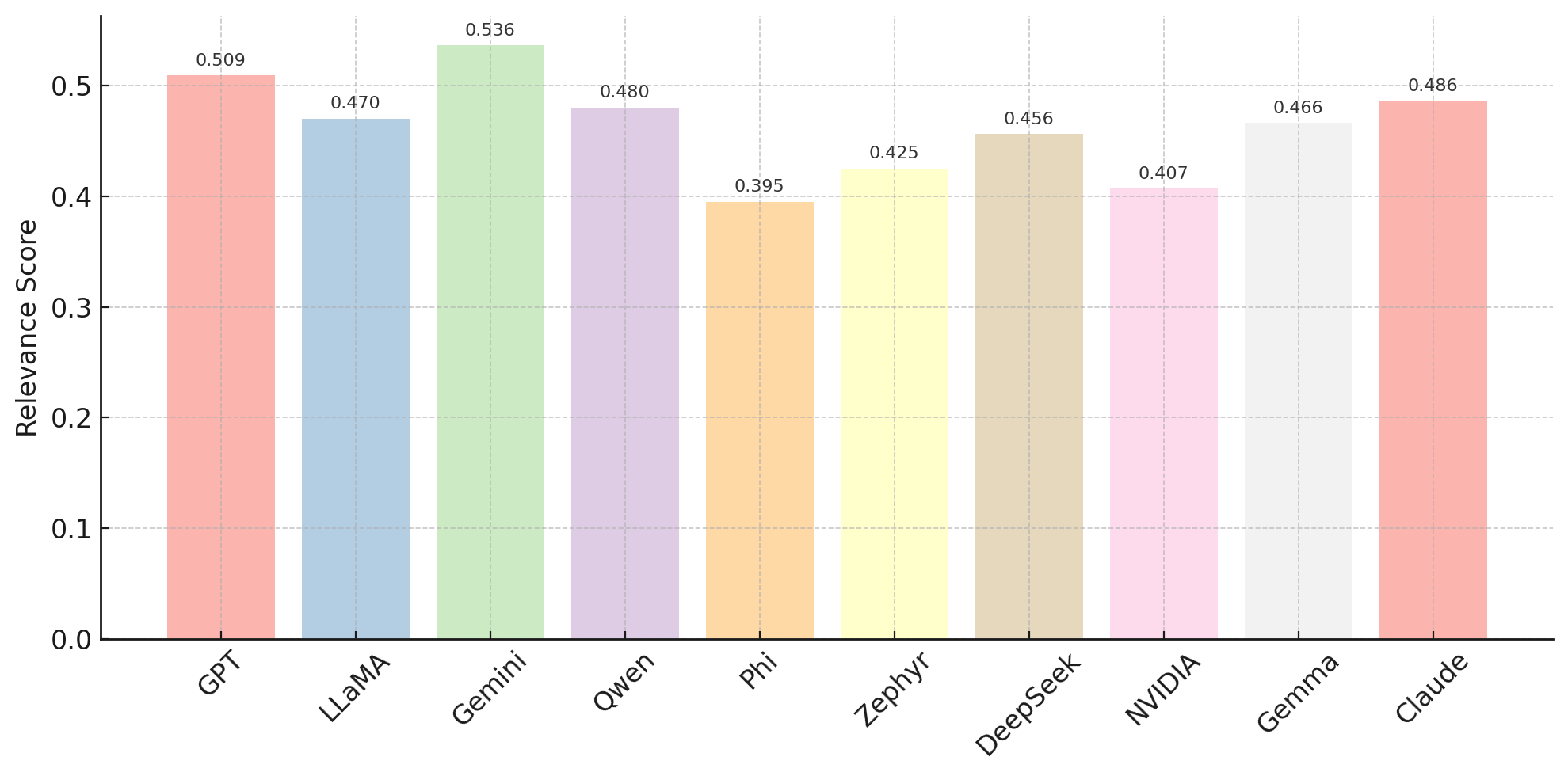
The results of the experiments are presented in Table 1.
To statistically validate the observed inverse relationship between diversity and relevance, we computed the Pearson correlation coefficient across the average scores of the ten evaluated LLMs. The analysis revealed a strong negative correlation (, ), suggesting that models with higher diversity scores tend to produce less relevant topics, and vice versa. This statistically supports our qualitative observation of a trade-off between topic diversity and contextual relevance.
| Model | Diversity | Relevance |
|---|---|---|
| GPT | 0.612 | 0.509 |
| LLaMA | 0.684 | 0.470 |
| Gemini | 0.526 | 0.536 |
| Qwen | 0.407 | 0.480 |
| Phi | 0.717 | 0.395 |
| Zephyr | 0.684 | 0.425 |
| DeepSeek | 0.695 | 0.456 |
| NVIDIA-LLaMA | 0.580 | 0.407 |
| Gemma | 0.643 | 0.466 |
| Claude | 0.634 | 0.486 |
The analysis of model outputs revealed notable differences in terms of diversity and relevance. As shown in Table 1, the models with the highest diversity scores were Phi (0.717) and DeepSeek (0.695). The topics generated by these models are highly distinct from one another, indicating their ability to produce creative content that spans a broad thematic range. However, this diversity may come at the cost of reduced alignment with the original content; for instance, Phi's relevance score was relatively low (0.395). This suggests that high diversity can sometimes negatively impact content coherence.
On the other hand, the models with the highest relevance scores were Gemini (0.536) and GPT (0.509). The topics produced by these models showed stronger alignment with the original texts, yielding more coherent and contextually appropriate outputs. Notably, despite Gemini's high relevance score, its diversity score was relatively low (0.526), indicating a tendency to produce repetitive or pattern-bound topics. Similarly, although Phi demonstrated high diversity, its low relevance score (0.395) suggests that some models may generate original yet contextually detached topics.
In conclusion, an inverse relationship between diversity and relevance was generally observed across models. This finding highlights the importance of carefully selecting the appropriate model based on the specific objective of the task. Depending on whether the goal is to maximize diversity or relevance, the performance and suitability of the chosen model may vary significantly.
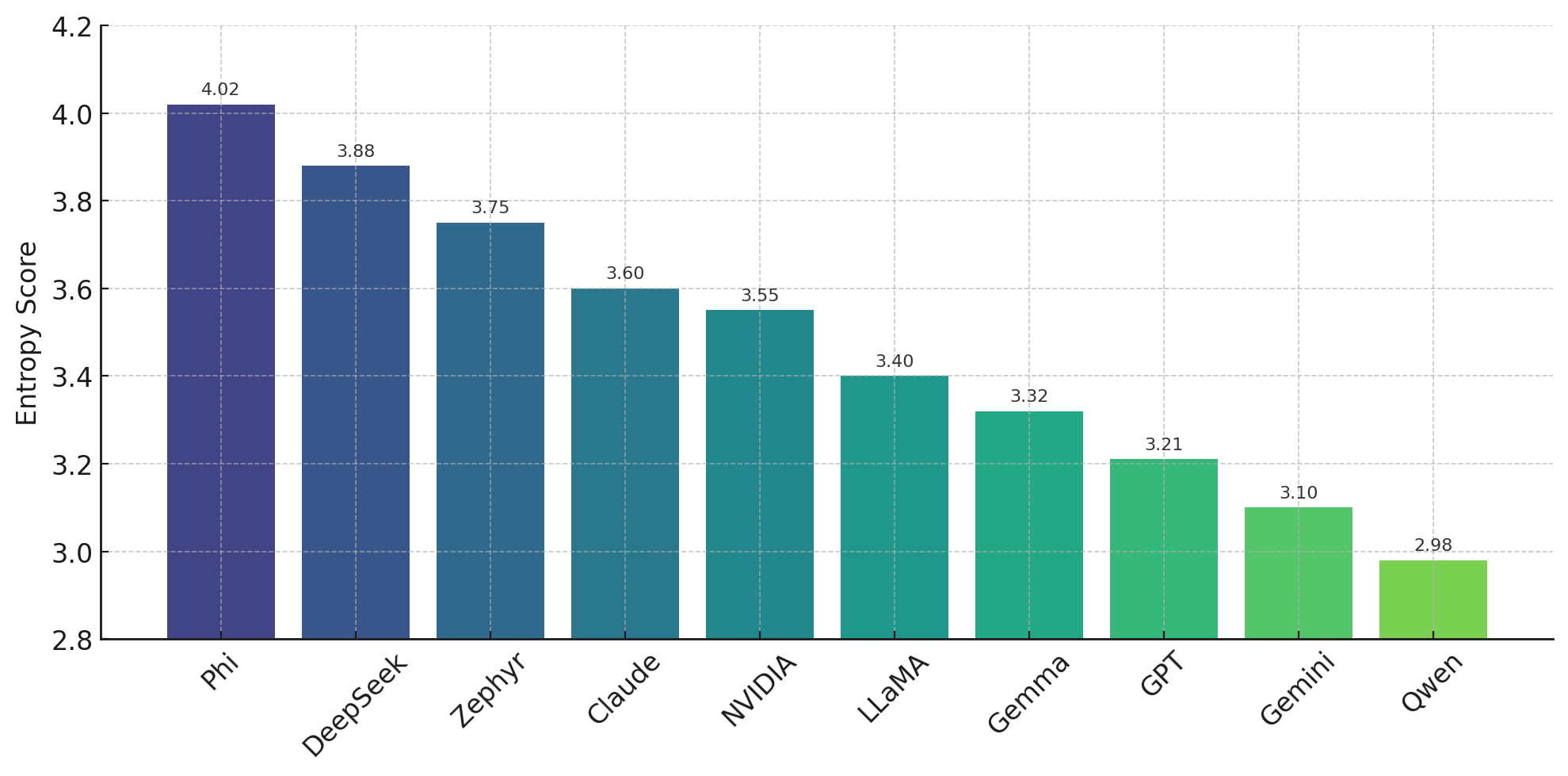
Phi (): This model has the highest entropy score, indicating that the generated topics are highly dispersed and ambiguous, which may reduce their interpretability.
DeepSeek (): Another model with high entropy. While the topics cover broader themes, this may come at the cost of reduced semantic clarity.
Zephyr (): Produced relatively general topics but still maintained a certain degree of semantic focus.
Claude (): With moderate entropy, this model strikes a balance between originality and breadth.
NVIDIA-LLaMA (): Similar to Claude, it generated thematically balanced and relatively coherent topics.
LLaMA (): With a lower entropy score, the model produced more focused and clearer thematic content.
Gemma (): The topics it generated were reasonably dense and focused, offering satisfactory interpretability.
GPT (): Produced more compact and structured topics, which facilitated easier interpretation.
Gemini (): Generated more distinct topics with well-defined themes and lower variance.
Qwen (): This model had the lowest entropy score, indicating that it produced very clear and narrowly scoped topics. However, such content may sometimes suffer from excessive repetition or drift from broader context.
| Model | Strength | Weakness |
|---|---|---|
| GPT | Balanced relevance level | Moderate diversity |
| LLaMA | High diversity | Low relevance score |
| Gemini | Highest relevance | Moderate diversity |
| Qwen | Strong in relevance | Lowest diversity |
| Phi | Highest diversity | Lowest relevance |
| Zephyr | High diversity | Low relevance |
| DeepSeek | Very high diversity | Moderate relevance |
| NVIDIA-LLaMA | Balanced diversity | Low relevance |
| Gemma | Moderately balanced | No clearly dominant strength |
| Claude | High relevance | Less diverse compared to others |
In this study, the topic modeling performance of ten different LLMs was comparatively evaluated on a large-scale collection of academic texts in the healthcare domain. The analyses were based on both quantitative and qualitative metrics, including diversity, redundancy, cosine similarity, and manual evaluation. The findings revealed that models such as GPT and Claude produced meaningful and coherent topics, while models like Qwen and Phi yielded more narrowly scoped outputs due to higher redundancy rates.
An important consideration that emerged during our evaluation is the degree to which models are aligned with domain-specific content. While certain LLMs such as GPT-4 and Claude have demonstrated effectiveness in healthcare-related benchmarks due to their exposure to biomedical corpora and clinical QA datasets, others—such as Zephyr and Phi—have not been explicitly trained or fine-tuned for medical applications. Nevertheless, our results show that even these domain-agnostic models can generate diverse and occasionally insightful topics in a healthcare setting. This finding underscores the value of including both domain-informed and general-purpose LLMs in comparative evaluations, especially when assessing their generalization capabilities in high-stakes fields such as medicine. Future research may further explore how fine-tuning on specialized corpora affects both the semantic coherence and factual alignment of topics generated by LLMs in clinical domains.
In domains such as healthcare, where accuracy and explainability are of critical importance, the potential for employing LLM-based approaches is substantial. However, in assessing the generative performance of these models, it is essential to consider not only automated metrics but also expert judgment and application-specific context. This study highlights the strengths and weaknesses of current models and provides a valuable reference point for the development of more reliable and interpretable topic modeling systems in the future.
Future research can explore similar comparative analyses across different languages and disciplines to better understand the generalization capabilities of LLMs. Additionally, the evaluation of hybrid approaches or interactive, user-guided dynamic modeling techniques may further enhance the applicability of topic modeling in sensitive domains such as healthcare.
 Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. ICCK Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3068-6652 (Online)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/