ICCK Transactions on Advanced Computing and Systems | Volume 2, Issue 2: 1-16, 2025 | DOI: 10.62762/TACS.2025.190575
Abstract
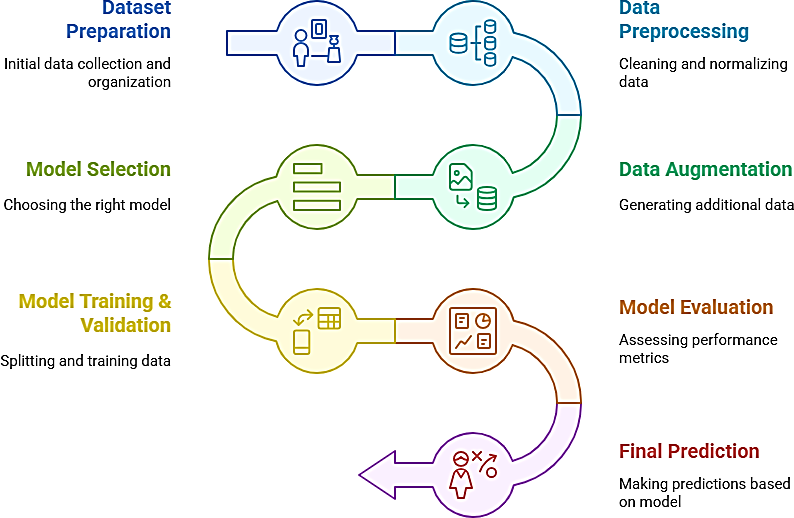
Roman Urdu sentiment analysis faces significant challenges due to transliteration inconsistencies, informal language usage, and the lack of labeled datasets. This study proposes a novel framework that addresses these challenges by combining advanced data preprocessing techniques and data augmentation strategies such as synonym replacement, back-translation, and random word insertion. These methods enhance dataset diversity, improving the model’s generalization ability. A rich Roman Urdu dataset was collected from diverse sources, including social media platforms (Facebook, Twitter, YouTube), blogs, forums, and e-commerce sites, to capture a wide range of user opinions. Three deep learning... More >
Graphical Abstract