Abstract
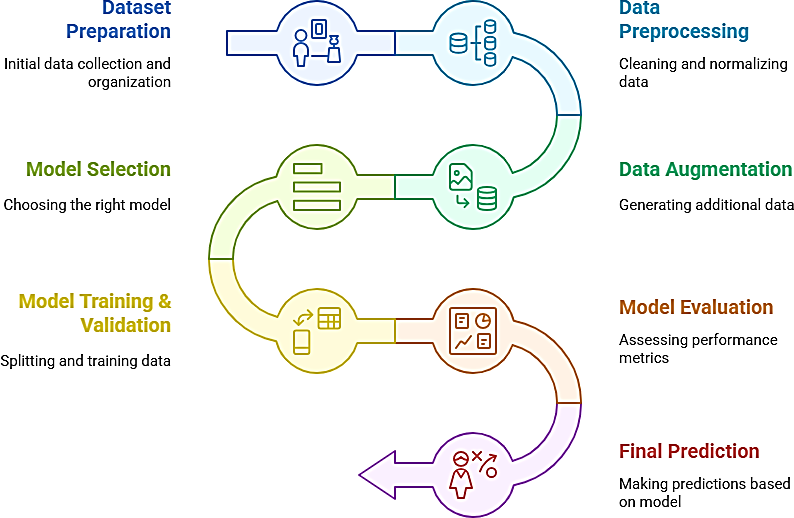
Roman Urdu sentiment analysis faces significant challenges due to transliteration inconsistencies, informal language usage, and the lack of labeled datasets. This study proposes a novel framework that addresses these challenges by combining advanced data preprocessing techniques and data augmentation strategies such as synonym replacement, back-translation, and random word insertion. These methods enhance dataset diversity, improving the model’s generalization ability. A rich Roman Urdu dataset was collected from diverse sources, including social media platforms (Facebook, Twitter, YouTube), blogs, forums, and e-commerce sites, to capture a wide range of user opinions. Three deep learning models, Recurrent Neural Network (RNN), Gated Recurrent Unit (GRU), and Long Short-Term Memory (LSTM), were evaluated for sentiment classification. The results show that the LSTM model outperforms the others with an accuracy of 94%, compared to 90% for RNN and 92% for GRU. The LSTM’s ability to capture long-term dependencies and contextual nuances in Roman Urdu text makes it the most effective model for this task, demonstrating a significant improvement over the traditional method.
Data Availability Statement
The dataset used in this study is publicly available at: https://github.com/awais1992/RomanUrdu-Sentiment-Aug. It contains Roman Urdu sentiment-annotated data, which can be accessed and utilized under the terms specified in the repository.
Funding
This work was supported without any funding.
Conflicts of Interest
The authors declare no conflicts of interest.
Ethical Approval and Consent to Participate
Not applicable.
Cite This Article
APA Style
Khan, M. O., Khan, W., Wang, Y., Rehman, A. U, & Khan, M. A. (2025). Enhancing Sentiment Analysis of Roman Urdu Using Augmentation Techniques and Deep Learning Models. ICCK Transactions on Advanced Computing and Systems, 2(2), 1–16. https://doi.org/10.62762/TACS.2025.190575
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions

Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (
https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.


 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue