Bridging Modalities: A Survey of Cross-Modal Image-Text Retrieval






Article Information
Abstract
The rapid advancement of Internet technology, driven by social media and e-commerce platforms, has facilitated the generation and sharing of multimodal data, leading to increased interest in efficient cross-modal retrieval systems. Cross-modal image-text retrieval, encompassing tasks such as image query text (IqT) retrieval and text query image (TqI) retrieval, plays a crucial role in semantic searches across modalities. This paper presents a comprehensive survey of cross-modal image-text retrieval, addressing the limitations of previous studies that focused on single perspectives such as subspace learning or deep learning models. We categorize existing models into single-tower, dual-tower, real-value representation, and binary representation models based on their structure and feature representation. A key focus is placed on the fusion of modalities to enhance retrieval performance across diverse data types. Additionally, we explore the impact of multimodal Large Language Models (MLLMs) on cross-modal fusion and retrieval. Our study also provides a detailed overview of common datasets, evaluation metrics, and performance comparisons of representative methods. Finally, we identify current challenges and propose future research directions to advance the field of cross-modal image-text retrieval.
Graphical Abstract
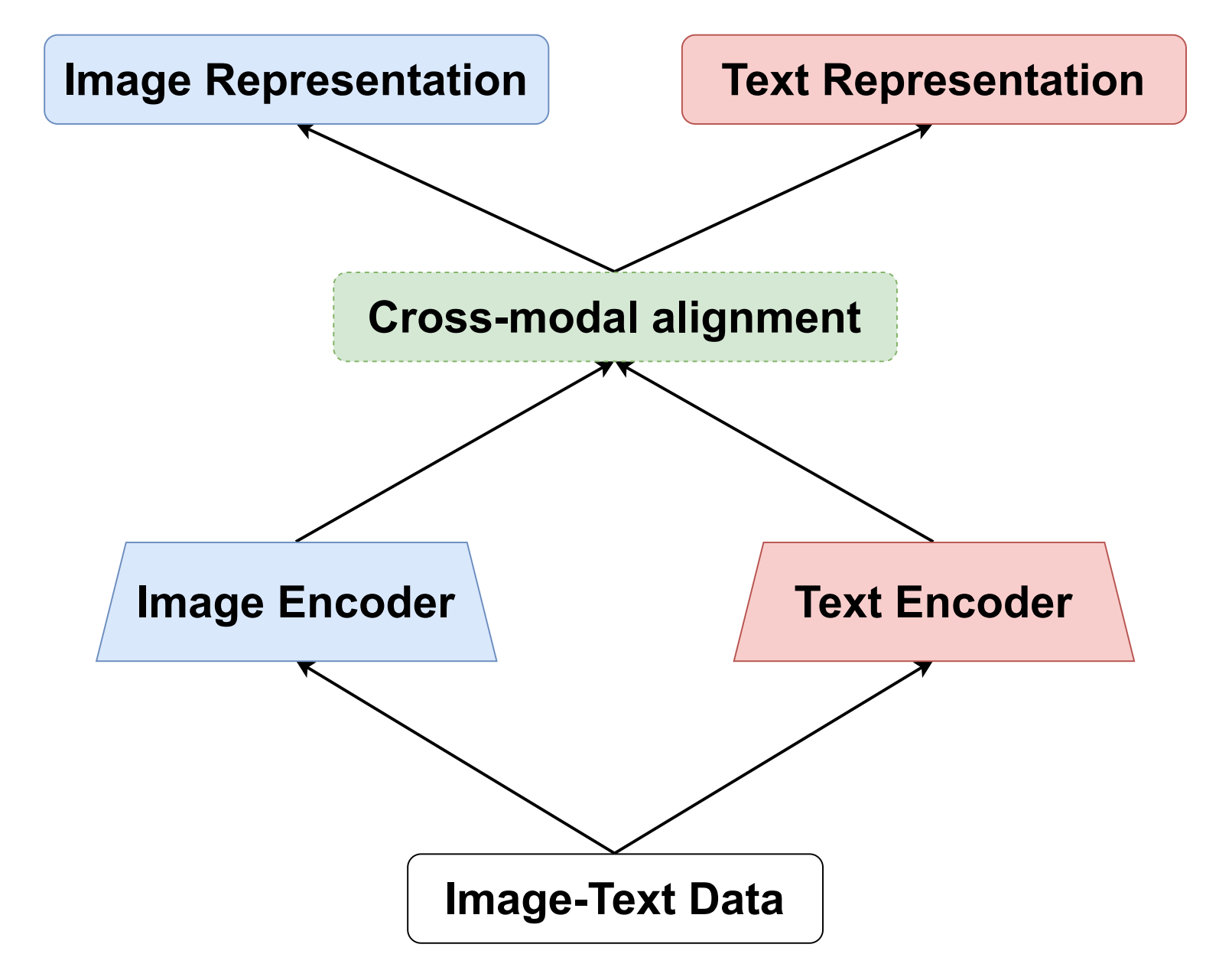
Keywords
Data Availability Statement
Funding
Conflicts of Interest
Ethical Approval and Consent to Participate
References
- Li, J., Li, D., Savarese, S., & Hoi, S. (2023, July). Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning (pp. 19730-19742). PMLR.
[Google Scholar] - Zhang, P., Wang, X. D. B., Cao, Y., Xu, C., Ouyang, L., Zhao, Z., ... & Wang, J. (2023). Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112.
[CrossRef] [Google Scholar] - Zhu, H., Huang, J. H., Rudinac, S., & Kanoulas, E. (2024). Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models. arXiv preprint arXiv:2404.18746.
[CrossRef] [Google Scholar] - Li, Y., Wang, W., Qu, L., Nie, L., Li, W., & Chua, T. S. (2024). Generative Cross-Modal Retrieval: Memorizing Images in Multimodal Language Models for Retrieval and Beyond. arXiv preprint arXiv:2402.10805.
[CrossRef] [Google Scholar] - Levy, M., Ben-Ari, R., Darshan, N., & Lischinski, D. (2024). Chatting makes perfect: Chat-based image retrieval. Advances in Neural Information Processing Systems, 36.
[Google Scholar] - Karthik, S., Roth, K., Mancini, M., & Akata, Z. (2023). Vision-by-language for training-free compositional image retrieval. arXiv preprint arXiv:2310.09291.
[CrossRef] [Google Scholar] - Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J. B., Yu, J., ... & Ahn, J. (2023). Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
[CrossRef] [Google Scholar] - Kim, W., Son, B., & Kim, I. (2021, July). Vilt: Vision-and-language transformer without convolution or region supervision. In International conference on machine learning (pp. 5583-5594). PMLR.
[Google Scholar] - Li, G., Duan, N., Fang, Y., Gong, M., & Jiang, D. (2020, April). Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, No. 07, pp. 11336-11344).
[CrossRef] [Google Scholar] - Li, L. H., Yatskar, M., Yin, D., Hsieh, C. J., & Chang, K. W. (2019). Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557.
[CrossRef] [Google Scholar] - Lu, J., Batra, D., Parikh, D., & Lee, S. (2019). Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems, 32.
[Google Scholar] - Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[Google Scholar] - Kim, D., Kim, N., & Kwak, S. (2023). Improving cross-modal retrieval with set of diverse embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 23422-23431).
[Google Scholar] - Jia, C., Yang, Y., Xia, Y., Chen, Y. T., Parekh, Z., Pham, H., ... & Duerig, T. (2021, July). Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning (pp. 4904-4916). PMLR.
[Google Scholar] - Wang, B., Yang, Y., Xu, X., Hanjalic, A., & Shen, H. T. (2017, October). Adversarial cross-modal retrieval. In Proceedings of the 25th ACM international conference on Multimedia (pp. 154-162).
[CrossRef] [Google Scholar] - Zhen, L., Hu, P., Wang, X., & Peng, D. (2019). Deep supervised cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10394-10403).
[Google Scholar] - Tang, X., Wang, Y., Ma, J., Zhang, X., Liu, F., & Jiao, L. (2023). Interacting-Enhancing Feature Transformer for Cross-modal Remote Sensing Image and Text Retrieval. IEEE Transactions on Geoscience and Remote Sensing.
[CrossRef] [Google Scholar] - Lu, H., Fei, N., Huo, Y., Gao, Y., Lu, Z., & Wen, J. R. (2022). Cots: Collaborative two-stream vision-language pre-training model for cross-modal retrieval. In Proceedings of the IEEE/CVF conference on computer Vision and pattern recognition (pp. 15692-15701).
[Google Scholar] - Xie, C. W., Wu, J., Zheng, Y., Pan, P., & Hua, X. S. (2022, October). Token embeddings alignment for cross-modal retrieval. In Proceedings of the 30th ACM International Conference on Multimedia (pp. 4555-4563).
[CrossRef] [Google Scholar] - Jiang, Q. Y., & Li, W. J. (2017). Deep cross-modal hashing. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3232-3240).
[Google Scholar] - Wu, G., Lin, Z., Han, J., Liu, L., Ding, G., Zhang, B., & Shen, J. (2018, July). Unsupervised Deep Hashing via Binary Latent Factor Models for Large-scale Cross-modal Retrieval. In IJCAI (Vol. 1, No. 3, p. 5).
[Google Scholar] - Li, C., Deng, C., Li, N., Liu, W., Gao, X., & Tao, D. (2018). Self-supervised adversarial hashing networks for cross-modal retrieval. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4242-4251).
[Google Scholar] - Li, T., Yang, X., Wang, B., Xi, C., Zheng, H., & Zhou, X. (2022, June). Bi-CMR: bidirectional reinforcement guided hashing for effective cross-modal retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 9, pp. 10275-10282).
[CrossRef] [Google Scholar] - Tu, J., Liu, X., Lin, Z., Hong, R., & Wang, M. (2022, October). Differentiable cross-modal hashing via multimodal transformers. In Proceedings of the 30th ACM International Conference on Multimedia (pp. 453-461).
[CrossRef] [Google Scholar] - Rasiwasia, N., Costa Pereira, J., Coviello, E., Doyle, G., Lanckriet, G. R., Levy, R., & Vasconcelos, N. (2010, October). A new approach to cross-modal multimedia retrieval. In Proceedings of the 18th ACM international conference on Multimedia (pp. 251-260).
[CrossRef] [Google Scholar] - Chua, T. S., Tang, J., Hong, R., Li, H., Luo, Z., & Zheng, Y. (2009, July). Nus-wide: a real-world web image database from national university of singapore. In Proceedings of the ACM international conference on image and video retrieval (pp. 1-9).
[CrossRef] [Google Scholar] - Escalante, H. J., Hernández, C. A., Gonzalez, J. A., López-López, A., Montes, M., Morales, E. F., ... & Grubinger, M. (2010). The segmented and annotated IAPR TC-12 benchmark. Computer vision and image understanding, 114(4), 419-428.
[CrossRef] [Google Scholar] - Huiskes, M. J., & Lew, M. S. (2008, October). The mir flickr retrieval evaluation. In Proceedings of the 1st ACM international conference on Multimedia information retrieval (pp. 39-43).
[CrossRef] [Google Scholar] - Rashtchian, C., Young, P., Hodosh, M., & Hockenmaier, J. (2010, June). Collecting image annotations using amazon’s mechanical turk. In Proceedings of the NAACL HLT 2010 workshop on creating speech and language data with Amazon’s Mechanical Turk (pp. 139-147).
[Google Scholar] - Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 (pp. 740-755). Springer International Publishing.
[CrossRef] [Google Scholar] - Tan, W., Zhu, L., Li, J., Zhang, H., & Han, J. (2022). Teacher-student learning: Efficient hierarchical message aggregation hashing for cross-modal retrieval. IEEE Transactions on Multimedia.
[CrossRef] [Google Scholar] - Peng, Y., & Qi, J. (2019). CM-GANs: Cross-modal generative adversarial networks for common representation learning. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 15(1), 1-24.
[CrossRef] [Google Scholar] - Dong, X., Liu, L., Zhu, L., Nie, L., & Zhang, H. (2021). Adversarial graph convolutional network for cross-modal retrieval. IEEE Transactions on Circuits and Systems for Video Technology, 32(3), 1634-1645.
[CrossRef] [Google Scholar] - Zeng, Z., & Mao, W. (2022). A comprehensive empirical study of vision-language pre-trained model for supervised cross-modal retrieval. arXiv preprint arXiv:2201.02772.
[CrossRef] [Google Scholar] - Tu, R. C., Mao, X. L., Ma, B., Hu, Y., Yan, T., Wei, W., & Huang, H. (2020). Deep cross-modal hashing with hashing functions and unified hash codes jointly learning. IEEE Transactions on Knowledge and Data Engineering, 34(2), 560-572.
[CrossRef] [Google Scholar] - Huo, Y., Qin, Q., Dai, J., Wang, L., Zhang, W., Huang, L., & Wang, C. (2023). Deep semantic-aware proxy hashing for multi-label cross-modal retrieval. IEEE Transactions on Circuits and Systems for Video Technology.
[CrossRef] [Google Scholar] - Zhu, L., Wang, T., Li, F., Li, J., Zhang, Z., & Shen, H. T. (2023). Cross-Modal Retrieval: A Systematic Review of Methods and Future Directions. arXiv preprint arXiv:2308.14263.
[CrossRef] [Google Scholar] - Zhou, K., Hassan, F. H., & Hoon, G. K. (2023). The State of the Art for Cross-Modal Retrieval: A Survey. IEEE Access.
[CrossRef] [Google Scholar] - Wang, X., Li, L., Li, Z., Wang, X., Zhu, X., Wang, C., ... & Xiao, Y. (2023, February). AGREE: aligning cross-modal entities for image-text retrieval upon vision-language pre-trained models. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining (pp. 456-464).
[CrossRef] [Google Scholar]
Cited By (7)
-
Xiang-Yang Li, Yihan Wang, Junli Liang, Xinyu Wang, Pengfei Zhou, Qi Zhao, Yuhang Zhang, Qi Song. Knowledge-enhanced AI models for domain-specific application: a survey.
Science China Information Sciences, 2026 , 69 (4).
[CrossRef] -
Tieying Li, Xiaochun Yang, Bin Wang, Lingdu Kong, Qingtian Bian, Jiaxing Xu, Boce Chu. Fine-Grained Disentanglement for Alleviating Inconsistencies in Cross-Modal Hashing Retrieval.
Data Science and Engineering, 2026 .
[CrossRef] -
Zhi Ma, Yizi Huang, Di Wang, Bo Wan, Lin Zhao, Quan Wang. .
Proceedings of the 2025 International Conference on Multimedia Retrieval, 2025 .
[CrossRef] -
Shuqiao Liu, Hongyan Zhou, Xuebo Chen, Zhao Zhang. A Generative Model-Based Network Framework for Ecological Data Reconstruction.
Computers, Materials & Continua, 2025 , 82 (1).
[CrossRef] -
Zhiqun Lin, Kexin Feng, Diaa Ahmed Mohamed Ahmedien. Improved generative adversarial networks model for movie dance generation.
PLOS One, 2025 , 20 (5).
[CrossRef] -
Xiaojun Wang, Jing Jiang, Alberto Marchisio. Illustration image style transfer method design based on improved cyclic consistent adversarial network.
PLOS ONE, 2025 , 20 (1).
[CrossRef] -
Yun Hua, Suyan Bian, Pan Liu, Shaodong Zhu, Jing Jing, Yan Zhuang, Menglu Li, Xu Chen, Chongyou Rao, Xiaoyu Jin, Kunlun He. VesselTransGAN to CT Imaging: A Contrast Medium Free CTA Solution.
IEEE Access, 2024 , 12 .
[CrossRef]
Cite This Article
TY - JOUR AU - Li, Tieying AU - Kong, Lingdu AU - Yang, Xiaochun AU - Wang, Bin AU - Xu, Jiaxing PY - 2024 DA - 2024/06/12 TI - Bridging Modalities: A Survey of Cross-Modal Image-Text Retrieval JO - Chinese Journal of Information Fusion T2 - Chinese Journal of Information Fusion JF - Chinese Journal of Information Fusion VL - 1 IS - 1 SP - 79 EP - 92 DO - 10.62762/CJIF.2024.361895 UR - https://www.icck.org/article/abs/CJIF.2024.361895 KW - multi-modal data KW - cross-modal retrieval KW - cross-modal alignment KW - cross-modal fusion KW - large language models AB - The rapid advancement of Internet technology, driven by social media and e-commerce platforms, has facilitated the generation and sharing of multimodal data, leading to increased interest in efficient cross-modal retrieval systems. Cross-modal image-text retrieval, encompassing tasks such as image query text (IqT) retrieval and text query image (TqI) retrieval, plays a crucial role in semantic searches across modalities. This paper presents a comprehensive survey of cross-modal image-text retrieval, addressing the limitations of previous studies that focused on single perspectives such as subspace learning or deep learning models. We categorize existing models into single-tower, dual-tower, real-value representation, and binary representation models based on their structure and feature representation. A key focus is placed on the fusion of modalities to enhance retrieval performance across diverse data types. Additionally, we explore the impact of multimodal Large Language Models (MLLMs) on cross-modal fusion and retrieval. Our study also provides a detailed overview of common datasets, evaluation metrics, and performance comparisons of representative methods. Finally, we identify current challenges and propose future research directions to advance the field of cross-modal image-text retrieval. SN - 2998-3371 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Li2024Bridging,
author = {Tieying Li and Lingdu Kong and Xiaochun Yang and Bin Wang and Jiaxing Xu},
title = {Bridging Modalities: A Survey of Cross-Modal Image-Text Retrieval},
journal = {Chinese Journal of Information Fusion},
year = {2024},
volume = {1},
number = {1},
pages = {79-92},
doi = {10.62762/CJIF.2024.361895},
url = {https://www.icck.org/article/abs/CJIF.2024.361895},
abstract = {The rapid advancement of Internet technology, driven by social media and e-commerce platforms, has facilitated the generation and sharing of multimodal data, leading to increased interest in efficient cross-modal retrieval systems. Cross-modal image-text retrieval, encompassing tasks such as image query text (IqT) retrieval and text query image (TqI) retrieval, plays a crucial role in semantic searches across modalities. This paper presents a comprehensive survey of cross-modal image-text retrieval, addressing the limitations of previous studies that focused on single perspectives such as subspace learning or deep learning models. We categorize existing models into single-tower, dual-tower, real-value representation, and binary representation models based on their structure and feature representation. A key focus is placed on the fusion of modalities to enhance retrieval performance across diverse data types. Additionally, we explore the impact of multimodal Large Language Models (MLLMs) on cross-modal fusion and retrieval. Our study also provides a detailed overview of common datasets, evaluation metrics, and performance comparisons of representative methods. Finally, we identify current challenges and propose future research directions to advance the field of cross-modal image-text retrieval.},
keywords = {multi-modal data, cross-modal retrieval, cross-modal alignment, cross-modal fusion, large language models},
issn = {2998-3371},
publisher = {Institute of Central Computation and Knowledge}
}
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions
 Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.

Portico

