Adaptive Risk Evaluation in FinTech Systems via Reinforcement-Based Continuous Policy Optimization


Article Information
Abstract
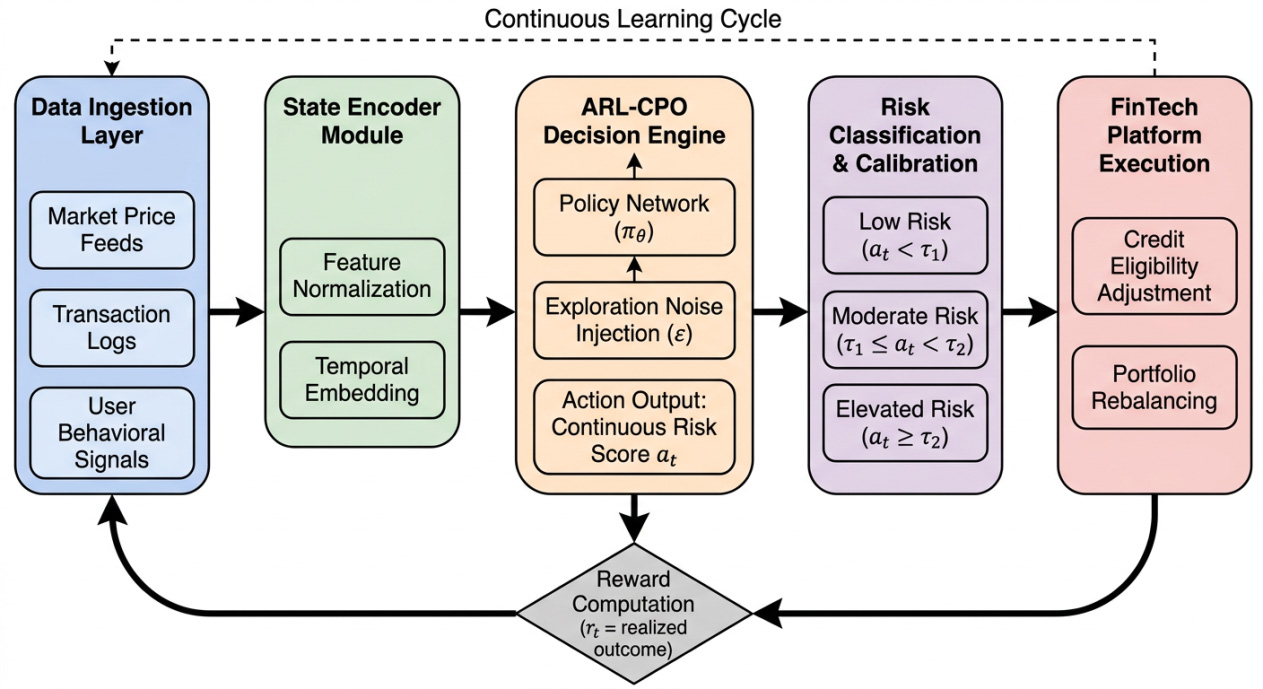
The key feature of FinTech software systems is the ability to accurately assess risk in real time, making decisions on high-volume streams of information that are associated with very low latency and are robust to concept drift, and able to be updated without disrupting services. This paper addresses the problem of adaptive risk scoring using a reinforcement learning approach by modeling the risk evaluation problem as a continuous-action Markov Decision Process and continuously optimizing the policy via streaming transactional, behavioral events and outcome driven reward feedback. In addition to the learning algorithm, we also view ARL-CPO as a deployable software architecture that separates online learning from inference serving to enable a modular approach to integrating ARL into production risk pipelines, such as an inference microservice, which is wrapped around an asynchronous update loop, updating ARL models continuously without periodic batch retraining — a capability not available in the Random Forest, Gradient Boosting, or Transformer baselines. We assess the approach on the prediction of credit default and adaptive asset allocation in a big data dataset of 8.5 million credit records, generated in a custom FinTech environment simulator. The performance based on precision and F1 score, of ARL-CPO is compared with the baselines, and it outperforms them with 97.4% classification accuracy, 98.8% trend adaptation rate (responsiveness to distributional shifts), and 96.1% cumulative long-term performance index (normalized long-horizon reward). The findings show that reinforcement learning-based continuous policy updates is an achievable, adaptive element for real-time risk systems in FinTech under the evolution of market and user conditions.
Graphical Abstract
Keywords
Data Availability Statement
Funding
Conflicts of Interest
AI Use Statement
Ethical Approval and Consent to Participate
References
- Mashrur, A., Luo, W., Zaidi, N. A., & Robles-Kelly, A. (2020). Machine learning for financial risk management: a survey. IEEE Access, 8, 203203-203223.
[CrossRef] [Google Scholar] - Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., & Zhang, G. (2018). Learning under concept drift: A review. IEEE transactions on knowledge and data engineering, 31(12), 2346-2363.
[CrossRef] [Google Scholar] - Climent, F., Momparler, A., & Carmona, P. (2019). Anticipating bank distress in the Eurozone: An extreme gradient boosting approach. Journal of business research, 101, 885-896.
[CrossRef] [Google Scholar] - Zeng, Z., Kaur, R., Siddagangappa, S., Rahimi, S., Balch, T., & Veloso, M. (2023). Financial time series forecasting using CNN and transformer. arXiv preprint arXiv:2304.04912.
[CrossRef] [Google Scholar] - Hambly, B., Xu, R., & Yang, H. (2023). Recent advances in reinforcement learning in finance. Mathematical Finance, 33(3), 437-503.
[CrossRef] [Google Scholar] - Liu, X. Y., Xiong, Z., Zhong, S., Yang, H., & Walid, A. (2018). Practical deep reinforcement learning approach for stock trading. arXiv preprint arXiv:1811.07522.
[CrossRef] [Google Scholar] - Zhang, Y., Zhao, P., Wu, Q., Li, B., Huang, J., & Tan, M. (2020). Cost-sensitive portfolio selection via deep reinforcement learning. IEEE Transactions on knowledge and data engineering, 34(1), 236-248.
[CrossRef] [Google Scholar] - Li, H., Cao, Y., Li, S., Zhao, J., & Sun, Y. (2020). XGBoost model and its application to personal credit evaluation. IEEE Intelligent Systems, 35(3), 52-61.
[CrossRef] [Google Scholar] - Alexandre, M., Silva, T. C., Connaughton, C., & Rodrigues, F. A. (2021). The drivers of systemic risk in financial networks: a data-driven machine learning analysis. Chaos, Solitons & Fractals, 153, 111588.
[CrossRef] [Google Scholar] - Xu, Q., Liao, Y., Li, Q., Zhang, J., Song, Z., Wang, L., & Yuan, X. (2024, August). SHAP-based Interpretable Models for Credit Default Assessment Using Machine Learning. In 2024 14th International Conference on Software Technology and Engineering (ICSTE) (pp. 213-217). IEEE.
[CrossRef] [Google Scholar] - Jospin, L. V., Laga, H., Boussaid, F., Buntine, W., & Bennamoun, M. (2022). Hands-on Bayesian neural networks—A tutorial for deep learning users. IEEE Computational Intelligence Magazine, 17(2), 29-48.
[CrossRef] [Google Scholar] - Alasbahi, R., & Zheng, X. (2022). An online transfer learning framework with extreme learning machine for automated credit scoring. IEEE Access, 10, 46697-46716.
[CrossRef] [Google Scholar] - Cheng, D., Niu, Z., Li, J., & Jiang, C. (2022). Regulating systemic crises: Stemming the contagion risk in networked-loans through deep graph learning. IEEE Transactions on Knowledge and Data Engineering, 35(6), 6278-6289.
[CrossRef] [Google Scholar] - Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. (2020). Explainable AI in fintech risk management. Frontiers in Artificial Intelligence, 3, 26.
[CrossRef] [Google Scholar] - Brim, A. (2020, January). Deep reinforcement learning pairs trading with a double deep Q-network. In 2020 10th annual computing and communication workshop and conference (CCWC) (pp. 0222-0227). IEEE.
[CrossRef] [Google Scholar] - Gašperov, B., & Kostanjčar, Z. (2022). Deep reinforcement learning for market making under a Hawkes process-based limit order book model. IEEE control systems letters, 6, 2485-2490.
[CrossRef] [Google Scholar] - Mashetty, P. C., Gangabathula, S., Gangabathula, N. V., Pullalarevu, N., Chaganti, K. R., & Chaganti, S. R. (2025, July). Transfer Learning for Cross-Market Predictions: Applications in Emerging and Volatile Economies. In 2025 6th International Conference on Data Intelligence and Cognitive Informatics (ICDICI) (pp. 621-626). IEEE.
[CrossRef] [Google Scholar] - Ghavamzadeh, M., Mannor, S., Pineau, J., & Tamar, A. (2015). Bayesian reinforcement learning: A survey. Foundations and Trends® in Machine Learning, 8(5-6), 359-483.
[CrossRef] [Google Scholar] - Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM computing surveys (CSUR), 46(4), 1-37.
[CrossRef] [Google Scholar] - Kreuzberger, D., Kühl, N., & Hirschl, S. (2023). Machine learning operations (mlops): Overview, definition, and architecture. IEEE Access, 11, 31866-31879.
[CrossRef] [Google Scholar] - Liu, X. Y., Xia, Z., Rui, J., Gao, J., Yang, H., Zhu, M., ... & Guo, J. (2022). FinRL-Meta: Market environments and benchmarks for data-driven financial reinforcement learning. Advances in Neural Information Processing Systems, 35, 1835-1849.
[Google Scholar] - Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., ... & Dennison, D. (2015). Hidden technical debt in machine learning systems. Advances in neural information processing systems, 28.
[Google Scholar] - Breck, E., Cai, S., Nielsen, E., Salib, M., & Sculley, D. (2017, December). The ML test score: A rubric for ML production readiness and technical debt reduction. In 2017 IEEE international conference on big data (big data) (pp. 1123-1132). IEEE.
[CrossRef] [Google Scholar] - Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., ... & Zimmermann, T. (2019, May). Software engineering for machine learning: A case study. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP) (pp. 291-300). IEEE.
[CrossRef] [Google Scholar] - Kim, M., Zimmermann, T., DeLine, R., & Begel, A. (2017). Data scientists in software teams: State of the art and challenges. IEEE Transactions on Software Engineering, 44(11), 1024-1038.
[CrossRef] [Google Scholar]
Cite This Article
TY - JOUR AU - Contreras, Edimer Mahecha PY - 2026 DA - 2026/06/11 TI - Adaptive Risk Evaluation in FinTech Systems via Reinforcement-Based Continuous Policy Optimization JO - ICCK Journal of Software Engineering T2 - ICCK Journal of Software Engineering JF - ICCK Journal of Software Engineering VL - 2 IS - 2 SP - 156 EP - 168 DO - 10.62762/JSE.2026.605759 UR - https://www.icck.org/article/abs/JSE.2026.605759 KW - reinforcement learning KW - continuous policy optimization KW - adaptive risk evaluation KW - FinTech software systems KW - sequential decision learning KW - credit risk modeling AB - The key feature of FinTech software systems is the ability to accurately assess risk in real time, making decisions on high-volume streams of information that are associated with very low latency and are robust to concept drift, and able to be updated without disrupting services. This paper addresses the problem of adaptive risk scoring using a reinforcement learning approach by modeling the risk evaluation problem as a continuous-action Markov Decision Process and continuously optimizing the policy via streaming transactional, behavioral events and outcome driven reward feedback. In addition to the learning algorithm, we also view ARL-CPO as a deployable software architecture that separates online learning from inference serving to enable a modular approach to integrating ARL into production risk pipelines, such as an inference microservice, which is wrapped around an asynchronous update loop, updating ARL models continuously without periodic batch retraining — a capability not available in the Random Forest, Gradient Boosting, or Transformer baselines. We assess the approach on the prediction of credit default and adaptive asset allocation in a big data dataset of 8.5 million credit records, generated in a custom FinTech environment simulator. The performance based on precision and F1 score, of ARL-CPO is compared with the baselines, and it outperforms them with 97.4% classification accuracy, 98.8% trend adaptation rate (responsiveness to distributional shifts), and 96.1% cumulative long-term performance index (normalized long-horizon reward). The findings show that reinforcement learning-based continuous policy updates is an achievable, adaptive element for real-time risk systems in FinTech under the evolution of market and user conditions. SN - 3069-1834 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Contreras2026Adaptive,
author = {Edimer Mahecha Contreras},
title = {Adaptive Risk Evaluation in FinTech Systems via Reinforcement-Based Continuous Policy Optimization},
journal = {ICCK Journal of Software Engineering},
year = {2026},
volume = {2},
number = {2},
pages = {156-168},
doi = {10.62762/JSE.2026.605759},
url = {https://www.icck.org/article/abs/JSE.2026.605759},
abstract = {The key feature of FinTech software systems is the ability to accurately assess risk in real time, making decisions on high-volume streams of information that are associated with very low latency and are robust to concept drift, and able to be updated without disrupting services. This paper addresses the problem of adaptive risk scoring using a reinforcement learning approach by modeling the risk evaluation problem as a continuous-action Markov Decision Process and continuously optimizing the policy via streaming transactional, behavioral events and outcome driven reward feedback. In addition to the learning algorithm, we also view ARL-CPO as a deployable software architecture that separates online learning from inference serving to enable a modular approach to integrating ARL into production risk pipelines, such as an inference microservice, which is wrapped around an asynchronous update loop, updating ARL models continuously without periodic batch retraining — a capability not available in the Random Forest, Gradient Boosting, or Transformer baselines. We assess the approach on the prediction of credit default and adaptive asset allocation in a big data dataset of 8.5 million credit records, generated in a custom FinTech environment simulator. The performance based on precision and F1 score, of ARL-CPO is compared with the baselines, and it outperforms them with 97.4\% classification accuracy, 98.8\% trend adaptation rate (responsiveness to distributional shifts), and 96.1\% cumulative long-term performance index (normalized long-horizon reward). The findings show that reinforcement learning-based continuous policy updates is an achievable, adaptive element for real-time risk systems in FinTech under the evolution of market and user conditions.},
keywords = {reinforcement learning, continuous policy optimization, adaptive risk evaluation, FinTech software systems, sequential decision learning, credit risk modeling},
issn = {3069-1834},
publisher = {Institute of Central Computation and Knowledge}
}
Article Metrics
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions
 Copyright © 2026 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2026 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.

Portico
