LI3D-BiLSTM: A Lightweight Inception-3D Networks with BiLSTM for Video Action Recognition




Article Information
Abstract
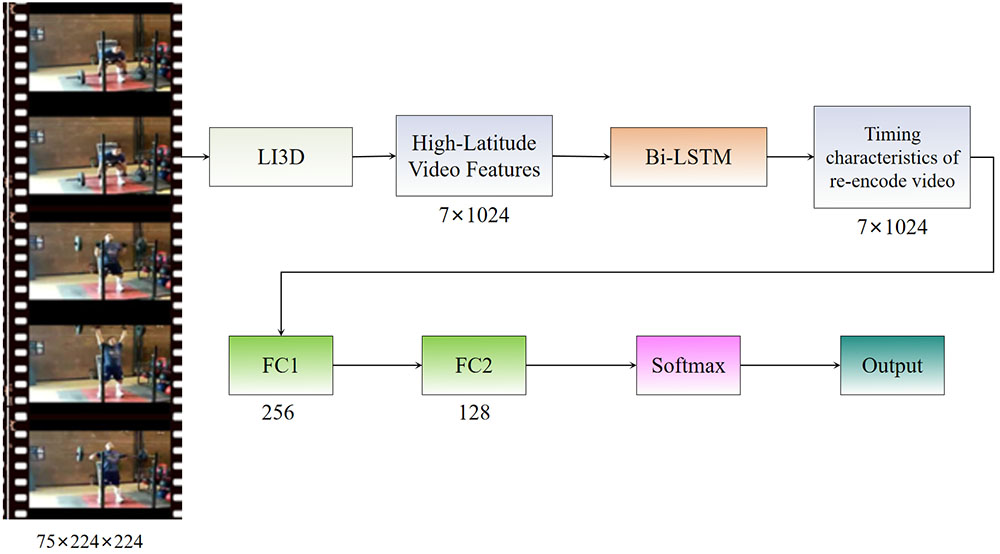
This paper proposes an improved video action recognition method, primarily consisting of three key components. Firstly, in the data preprocessing stage, we developed multi-temporal scale video frame extraction and multi-spatial scale video cropping techniques to enhance content information and standardize input formats. Secondly, we propose a lightweight Inception-3D networks (LI3D) network structure for spatio-temporal feature extraction and design a soft-association feature aggregation module to improve the recognition accuracy of key actions in videos. Lastly, we employ a bidirectional LSTM network to contextualize the feature sequences extracted by LI3D, enhancing the representation capability for temporal data. To improve the model’s robustness and generalization ability, we introduced spatial and temporal scale data augmentation techniques in the preprocessing stage, effectively extracting video key frames and capturing key regional actions. Furthermore, we conducted an in-depth study on spatio-temporal feature extraction methods for video data, effectively extracting spatial and temporal information through the LI3D network and transfer learning. Experimental results demonstrate that the proposed method achieves significant performance improvements in video action recognition tasks, providing new insights and approaches for research in related fields.
Code (Data) Available
Graphical Abstract
Keywords
Data Availability Statement
Funding
Conflicts of Interest
Ethical Approval and Consent to Participate
References
- Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2), 91-110.
[CrossRef] [Google Scholar] - Andrade-Ambriz, Y. A., Ledesma, S., Ibarra-Manzano, M. A., Oros-Flores, M. I., & Almanza-Ojeda, D. L. (2022). Human activity recognition using temporal convolutional neural network architecture. Expert Systems with Applications, 191, 116287.
[CrossRef] [Google Scholar] - Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., & Fei-Fei, L. (2014). Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 1725-1732).
[CrossRef] [Google Scholar] - Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. (2015). Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision (pp. 4489-4497).
[Google Scholar] - Zha, S., Luisier, F., Andrews, W., Srivastava, N., & Salakhutdinov, R. (2015). Exploiting image-trained CNN architectures for unconstrained video classification. arXiv preprint arXiv:1503.04144.
[CrossRef] [Google Scholar] - Yue-Hei Ng, J., Hausknecht, M., Vijayanarasimhan, S., Vinyals, O., Monga, R., & Toderici, G. (2015). Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4694-4702).
[Google Scholar] - Donahue, J., Anne Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., & Darrell, T. (2015). Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2625-2634).
[CrossRef] [Google Scholar] - Zhang, H., Wu, C., Zhang, Z., Zhu, Y., Lin, H., Zhang, Z., ... & Smola, A. (2022). Resnest: Split-attention networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 2736-2746).
[Google Scholar] - Li, Z., Gavrilyuk, K., Gavves, E., Jain, M., & Snoek, C. G. (2018). Videolstm convolves, attends and flows for action recognition. Computer Vision and Image Understanding, 166, 41-50.
[CrossRef] [Google Scholar] - Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., & Van Gool, L. (2016, September). Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision (pp. 20-36). Cham: Springer International Publishing.
[CrossRef] [Google Scholar] - Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. Advances in neural information processing systems, 27.
[Google Scholar] - Diba, A., Fayyaz, M., Sharma, V., Karami, A. H., Arzani, M. M., Yousefzadeh, R., & Van Gool, L. (2017). Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv preprint arXiv:1711.08200.
[CrossRef] [Google Scholar] - Bertasius, G., Wang, H., & Torresani, L. (2021, July). Is space-time attention all you need for video understanding?. In ICML (Vol. 2, No. 3, p. 4).https://proceedings.mlr.press/v139/bertasius21a/bertasius21a-supp.pdf
[Google Scholar] - Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., & Feichtenhofer, C. (2021). Multiscale vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6824-6835).
[CrossRef] [Google Scholar] - Tong, Z., Song, Y., Wang, J., & Wang, L. (2022). Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Advances in neural information processing systems, 35, 10078-10093.
[Google Scholar] - Lin, J., Gan, C., & Han, S. (2019). Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 7083-7093).
[CrossRef] [Google Scholar] - Ryoo, M., Piergiovanni, A. J., Arnab, A., Dehghani, M., & Angelova, A. (2021). Tokenlearner: Adaptive space-time tokenization for videos. Advances in neural information processing systems, 34, 12786-12797.
[Google Scholar] - Yang, H., Huang, D., Wen, B., Wu, J., Yao, H., Jiang, Y., ... & Yuan, Z. (2022). Self-supervised video representation learning with motion-aware masked autoencoders. arXiv preprint arXiv:2210.04154.
[CrossRef] [Google Scholar] - Wei, C., Fan, H., Xie, S., Wu, C. Y., Yuille, A., & Feichtenhofer, C. (2022). Masked feature prediction for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14668-14678).
[CrossRef] [Google Scholar] - Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818-2826).
[Google Scholar] - Carreira, J., & Zisserman, A. (2017). Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4724-4733).
[CrossRef] [Google Scholar] - Soomro, K., Zamir, A. R., & Shah, M. (2012). UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402.
[CrossRef] [Google Scholar]
Cited By (6)
-
Aiman Khan Nazir, Lanfang Dong, Bei Hua, Qasim Jan, Kang Dong, Xiahan Feng. .
2026 11th International Conference on Intelligent Computing and Signal Processing (ICSP), 2026 .
[CrossRef] -
Zhiqun Lin, Kexin Feng, Diaa Ahmed Mohamed Ahmedien. Improved generative adversarial networks model for movie dance generation.
PLOS One, 2025 , 20 (5).
[CrossRef] -
Marjan Kia, Soroush Sadeghi, Homayoun Safarpour, Mohammadreza Kamsari, Saeid Jafarzadeh Ghoushchi, Ramin Ranjbarzadeh. Innovative fusion of VGG16, MobileNet, EfficientNet, AlexNet, and ResNet50 for MRI-based brain tumor identification.
Iran Journal of Computer Science, 2025 , 8 (1).
[CrossRef] -
Tianjing Wang, Chao Ren, Zhijun Zhang, Zhao Yang Dong. GPT-Assisted Multi-View Multi-Label Learning for Non-Intrusive Load Monitoring With Incomplete Labels and Data.
IEEE Transactions on Consumer Electronics, 2025 , 71 (4).
[CrossRef] -
Marjan Kia. Attention-guided deep learning for effective customer loyalty management and multi-criteria decision analysis.
Iran Journal of Computer Science, 2025 , 8 (1).
[CrossRef] -
Lei Shi, Yaodong Gu. Verification and application of deep learning models in daily sports activities of teenagers.
PLOS One, 2025 , 20 (6).
[CrossRef]
Cite This Article
TY - JOUR AU - Wang, Fafa AU - Jin, Xuebo AU - Yi, Shenglun PY - 2024 DA - 2024/08/09 TI - LI3D-BiLSTM: A Lightweight Inception-3D Networks with BiLSTM for Video Action Recognition JO - ICCK Transactions on Emerging Topics in Artificial Intelligence T2 - ICCK Transactions on Emerging Topics in Artificial Intelligence JF - ICCK Transactions on Emerging Topics in Artificial Intelligence VL - 1 IS - 1 SP - 58 EP - 70 DO - 10.62762/TETAI.2024.628205 UR - https://www.icck.org/article/abs/TETAI.2024.628205 KW - video action recognition KW - multi-scale preprocessing KW - lightweight I3D (LI3D) KW - spatio-temporal feature extraction KW - bidirectional LSTM AB - This paper proposes an improved video action recognition method, primarily consisting of three key components. Firstly, in the data preprocessing stage, we developed multi-temporal scale video frame extraction and multi-spatial scale video cropping techniques to enhance content information and standardize input formats. Secondly, we propose a lightweight Inception-3D networks (LI3D) network structure for spatio-temporal feature extraction and design a soft-association feature aggregation module to improve the recognition accuracy of key actions in videos. Lastly, we employ a bidirectional LSTM network to contextualize the feature sequences extracted by LI3D, enhancing the representation capability for temporal data. To improve the model’s robustness and generalization ability, we introduced spatial and temporal scale data augmentation techniques in the preprocessing stage, effectively extracting video key frames and capturing key regional actions. Furthermore, we conducted an in-depth study on spatio-temporal feature extraction methods for video data, effectively extracting spatial and temporal information through the LI3D network and transfer learning. Experimental results demonstrate that the proposed method achieves significant performance improvements in video action recognition tasks, providing new insights and approaches for research in related fields. SN - 3068-6652 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Wang2024LI3DBiLSTM,
author = {Fafa Wang and Xuebo Jin and Shenglun Yi},
title = {LI3D-BiLSTM: A Lightweight Inception-3D Networks with BiLSTM for Video Action Recognition},
journal = {ICCK Transactions on Emerging Topics in Artificial Intelligence},
year = {2024},
volume = {1},
number = {1},
pages = {58-70},
doi = {10.62762/TETAI.2024.628205},
url = {https://www.icck.org/article/abs/TETAI.2024.628205},
abstract = {This paper proposes an improved video action recognition method, primarily consisting of three key components. Firstly, in the data preprocessing stage, we developed multi-temporal scale video frame extraction and multi-spatial scale video cropping techniques to enhance content information and standardize input formats. Secondly, we propose a lightweight Inception-3D networks (LI3D) network structure for spatio-temporal feature extraction and design a soft-association feature aggregation module to improve the recognition accuracy of key actions in videos. Lastly, we employ a bidirectional LSTM network to contextualize the feature sequences extracted by LI3D, enhancing the representation capability for temporal data. To improve the model’s robustness and generalization ability, we introduced spatial and temporal scale data augmentation techniques in the preprocessing stage, effectively extracting video key frames and capturing key regional actions. Furthermore, we conducted an in-depth study on spatio-temporal feature extraction methods for video data, effectively extracting spatial and temporal information through the LI3D network and transfer learning. Experimental results demonstrate that the proposed method achieves significant performance improvements in video action recognition tasks, providing new insights and approaches for research in related fields.},
keywords = {video action recognition, multi-scale preprocessing, lightweight I3D (LI3D), spatio-temporal feature extraction, bidirectional LSTM},
issn = {3068-6652},
publisher = {Institute of Central Computation and Knowledge}
}
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions
 Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.

Portico
