ICCK Transactions on Educational Data Mining
ISSN: 3070-5843 (Online)
Email: [email protected]
 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue

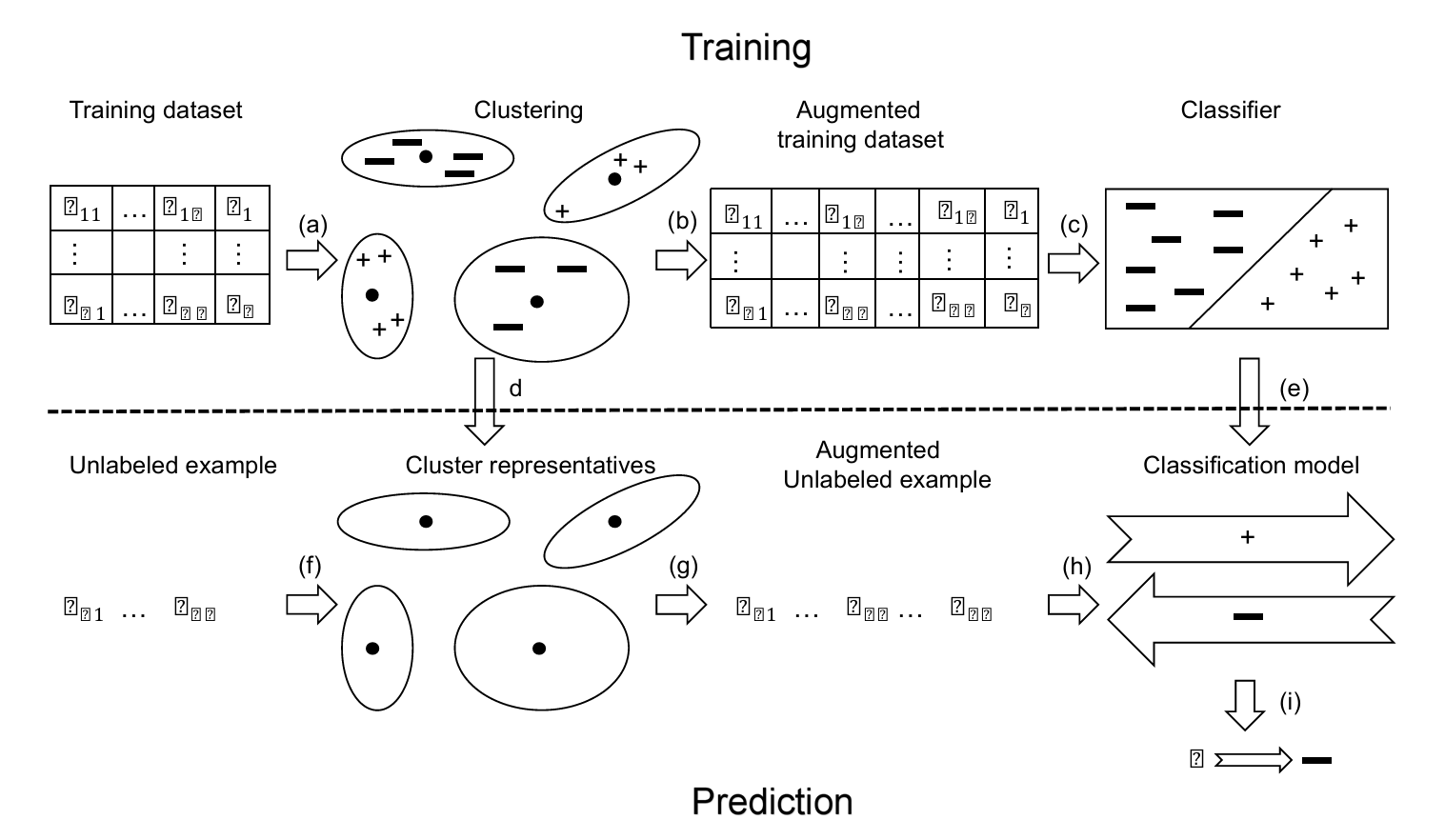
TY - JOUR AU - Yu, Zhihong PY - 2026 DA - 2026/02/28 TI - KFWAdaBoost-Based Soft Label Learning Framework for Student Performance Prediction JO - ICCK Transactions on Educational Data Mining T2 - ICCK Transactions on Educational Data Mining JF - ICCK Transactions on Educational Data Mining VL - 2 IS - 1 SP - 1 EP - 13 DO - 10.62762/TEDM.2026.459733 UR - https://www.icck.org/article/abs/TEDM.2026.459733 KW - soft label learning KW - KFWAdaBoost KW - K-means++ clustering KW - student performance prediction KW - educational data mining AB - Student performance prediction is a core task in educational data mining, as it enables early intervention, personalized learning support, and data-driven decision-making. Although existing machine learning models have shown promising results in this domain, challenges persist due to hard-to-classify samples—particularly students exhibiting borderline performance—and the discrete nature of hard labels, which together limit predictive effectiveness. To overcome these limitations, this paper proposes a KFWAdaBoost-based soft label learning framework that systematically enhances baseline model performance through a two-stage synergistic mechanism. In the first stage, K-means++ clustering is employed to generate similarity features, thereby providing structural awareness of underlying data patterns. In the second stage, probabilistic soft labels are derived from ensemble confidence scores to refine decision boundaries and better handle ambiguous cases. Experimental results on the widely used Mathematics and Portuguese Language course datasets demonstrate that the proposed framework consistently improves baseline performance across Accuracy, Precision, Recall, and F1-Score for models including LDA, Decision Tree, and SVM, with Decision Tree exhibiting the most substantial gains. This framework offers a reliable and effective approach for student performance prediction and holds strong potential for broader applications in educational data analytics. SN - 3070-5843 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Yu2026KFWAdaBoos,
author = {Zhihong Yu},
title = {KFWAdaBoost-Based Soft Label Learning Framework for Student Performance Prediction},
journal = {ICCK Transactions on Educational Data Mining},
year = {2026},
volume = {2},
number = {1},
pages = {1-13},
doi = {10.62762/TEDM.2026.459733},
url = {https://www.icck.org/article/abs/TEDM.2026.459733},
abstract = {Student performance prediction is a core task in educational data mining, as it enables early intervention, personalized learning support, and data-driven decision-making. Although existing machine learning models have shown promising results in this domain, challenges persist due to hard-to-classify samples—particularly students exhibiting borderline performance—and the discrete nature of hard labels, which together limit predictive effectiveness. To overcome these limitations, this paper proposes a KFWAdaBoost-based soft label learning framework that systematically enhances baseline model performance through a two-stage synergistic mechanism. In the first stage, K-means++ clustering is employed to generate similarity features, thereby providing structural awareness of underlying data patterns. In the second stage, probabilistic soft labels are derived from ensemble confidence scores to refine decision boundaries and better handle ambiguous cases. Experimental results on the widely used Mathematics and Portuguese Language course datasets demonstrate that the proposed framework consistently improves baseline performance across Accuracy, Precision, Recall, and F1-Score for models including LDA, Decision Tree, and SVM, with Decision Tree exhibiting the most substantial gains. This framework offers a reliable and effective approach for student performance prediction and holds strong potential for broader applications in educational data analytics.},
keywords = {soft label learning, KFWAdaBoost, K-means++ clustering, student performance prediction, educational data mining},
issn = {3070-5843},
publisher = {Institute of Central Computation and Knowledge}
}

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/