K-Means Clustering-Based Feature Generation for Student Performance Prediction

Article Information
Abstract
With the development of educational technology and the accumulation of big data, student performance prediction has become a hot topic in the field of education. However, traditional manual statistical methods have limitations in dealing with complex data and are difficult to achieve high-precision prediction. To address this gap, this study proposes a clustering-based feature generation framework to enhance prediction performance. Firstly, the multilayer perceptron (MLP) model is employed to evaluate the effectiveness of the clustering algorithms (K-Means, DBSCAN, and hierarchical clustering) for feature generation. Then, the best clustering algorithm (K-Means) is applied to generate features that are subsequently integrated with original features to construct augmented datasets. Subsequently, grid search is adopted to optimize model hyperparameters, and six machine learning models, including MLP, support vector machine, random forest, Bagging, XGBoost, and CatBoost, are trained and evaluated on datasets with and without clustering-generated features. Experimental results demonstrate that K-Means-based feature generation can effectively improve prediction performance under certain conditions. However, the performance gains are influenced by data characteristics, feature distributions, and model structures. The findings also reveal that clustering-derived features do not universally enhance all machine learning algorithms, highlighting the necessity of selecting appropriate model–feature integration strategies in practical applications.
Graphical Abstract
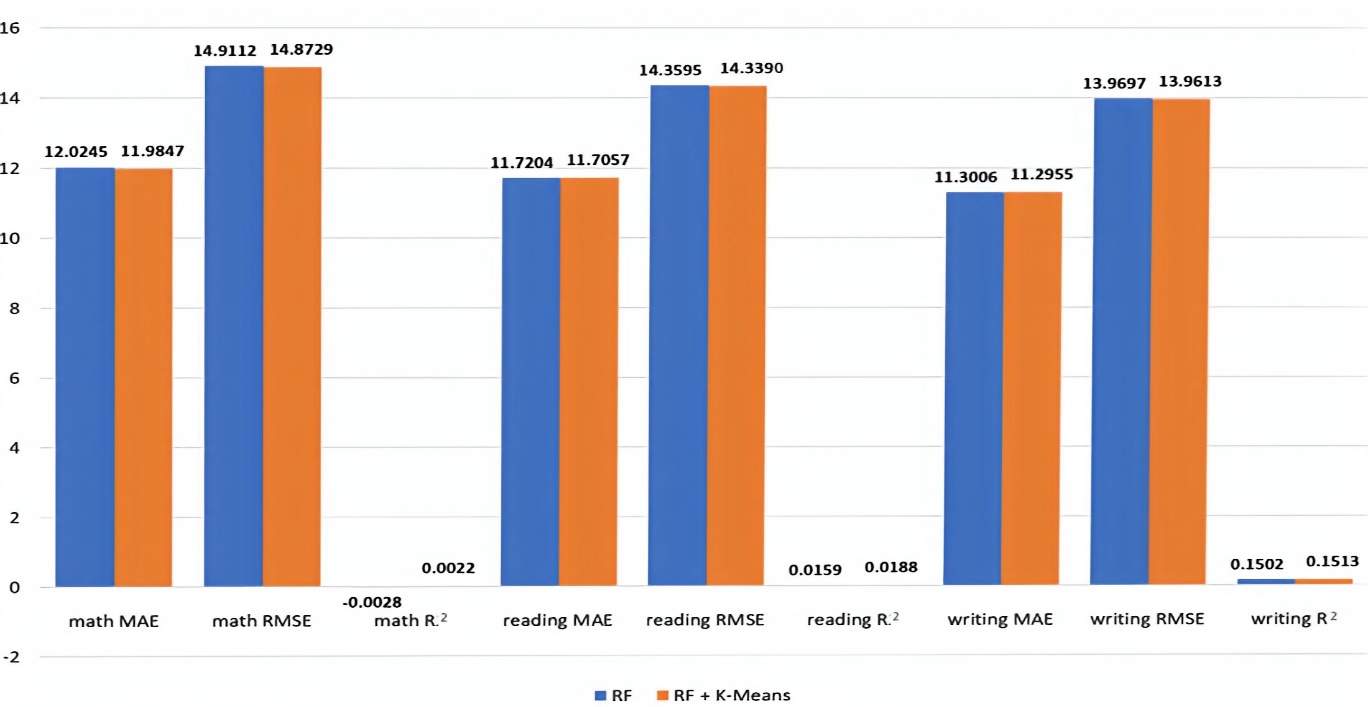
Keywords
Data Availability Statement
Funding
Conflicts of Interest
AI Use Statement
Ethical Approval and Consent to Participate
References
- Gonugunta, K. C., & Leo, K. (2024). Role of data-driven decision making in enhancing higher education performance: A comprehensive analysis of analytics in institutional management. International Journal of Acta Informatica, 3(1), 149-159.
[Google Scholar] - Batool, S., Rashid, J., Nisar, M. W., Kim, J., Kwon, H. Y., & Hussain, A. (2023). Educational data mining to predict students' academic performance: A survey study. Education and Information Technologies, 28(1), 905-971.
[CrossRef] [Google Scholar] - Antonenko, P. D., Toy, S., & Niederhauser, D. S. (2012). Using cluster analysis for data mining in educational technology research. Educational Technology Research and Development, 60(3), 383-398.
[CrossRef] [Google Scholar] - Shen, Y. (2024, May). Using long short-term memory networks (LSTM) to predict student academic achievement: dynamic learning path adjustment. In Proceedings of the 2024 International Conference on Machine Intelligence and Digital Applications (pp. 627-634).
[CrossRef] [Google Scholar] - Li, M. (2018). A study on the influence of non-intelligence factors on college students’ English learning achievement based on C4. 5 algorithm of decision tree. Wireless personal communications, 102(2), 1213-1222.
[CrossRef] [Google Scholar] - Abdrakhmanov, R., Zhaxanova, A., Karatayeva, M., Niyazova, G. Z., Berkimbayev, K., & Tuimebayev, A. (2024). Development of a Framework for Predicting Students' Academic Performance in STEM Education using Machine Learning Methods. International Journal of Advanced Computer Science & Applications, 15(1).
[CrossRef] [Google Scholar] - Kinash, S., Naidu, V., Knight, D., Judd, M. M., Nair, C. S., Booth, S., ... & Tulloch, M. (2015). Student feedback: a learning and teaching performance indicator. Quality Assurance in Education, 23(4), 410-428.
[CrossRef] [Google Scholar] - Liu, Y., Hui, Y., Hou, D., & Liu, X. (2023). A novel student achievement prediction method based on deep learning and attention mechanism. IEEE Access, 11, 87245-87255.
[CrossRef] [Google Scholar] - Pandey, M., & Sharma, V. K. (2013). A decision tree algorithm pertaining to the student performance analysis and prediction. International Journal of Computer Applications, 61(13), 1-5.
[CrossRef] [Google Scholar] - Xu, Z., Yuan, H., & Liu, Q. (2020). Student performance prediction based on blended learning. IEEE Transactions on Education, 64(1), 66-73.
[CrossRef] [Google Scholar] - Yang, S. J., Lu, O. H., Huang, A. Y., Huang, J. C., Ogata, H., & Lin, A. J. (2018). Predicting students' academic performance using multiple linear regression and principal component analysis. Journal of Information Processing, 26, 170-176.
[CrossRef] [Google Scholar] - Waheed, H., Hassan, S. U., Aljohani, N. R., Hardman, J., Alelyani, S., & Nawaz, R. (2020). Predicting academic performance of students from VLE big data using deep learning models. Computers in Human behavior, 104, 106189.
[CrossRef] [Google Scholar] - Salah Hashim, A., Akeel Awadh, W., & Khalaf Hamoud, A. (2020, November). Student performance prediction model based on supervised machine learning algorithms. In IOP conference series: materials science and engineering (Vol. 928, No. 3, p. 032019). IOP Publishing.
[CrossRef] [Google Scholar] - Fan, Z., Gou, J., & Wang, C. (2023). Predicting secondary school student performance using a double particle swarm optimization-based categorical boosting model. Engineering Applications of Artificial Intelligence, 124, 106649.
[CrossRef] [Google Scholar] - Ali, Z. M., Hassoon, N. H., Ahmed, W. S., & Abed, H. N. (2020). The application of data mining for predicting academic performance using k-means clustering and naïve bayes classification. International Journal of Psychosocial Rehabilitation, 24(03), 2143-2151.
[CrossRef] [Google Scholar] - Sun, D., Luo, R., Guo, Q., Xie, J., Liu, H., Lyu, S., ... & Song, S. (2023). A university student performance prediction model and experiment based on multi-feature fusion and attention mechanism. IEEE Access, 11, 112307-112319.
[CrossRef] [Google Scholar] - Nachouki, M., & Abou Naaj, M. (2022). Predicting student performance to improve academic advising using the random forest algorithm. International Journal of Distance Education Technologies (IJDET), 20(1), 1-17.
[CrossRef] [Google Scholar] - Zaffar, M., Hashmani, M. A., Savita, K. S., & Rizvi, S. S. H. (2018). A study of feature selection algorithms for predicting students academic performance. International Journal of Advanced Computer Science and Applications, 9(5).
[Google Scholar] - Mashagba, E., Al-Saqqar, F., & Al-Shatnawi, A. (2023, March). Using gradient boosting algorithms in predicting student academic performance. In 2023 International Conference on Business Analytics for Technology and Security (ICBATS) (pp. 1-7). IEEE.
[CrossRef] [Google Scholar] - Ani, A., & Khor, E. T. (2024). Development and evaluation of predictive models for predicting students performance in MOOCs. Education and Information Technologies, 29(11), 13905-13928.
[CrossRef] [Google Scholar] - Pires, J. P., Brito Correia, F., Gomes, A., Borges, A. R., & Bernardino, J. (2024). Predicting student performance in introductory programming courses. Computers, 13(9), 219.
[CrossRef] [Google Scholar] - Angeioplastis, A., Aliprantis, J., Konstantakis, M., & Tsimpiris, A. (2025). Predicting student performance and enhancing learning outcomes: a data-driven approach using educational data mining techniques. Computers, 14(3), 83.
[CrossRef] [Google Scholar] - Tapio, R. (2025). Comparative analysis of multiple linear regression and random forest regression in predicting academic performance of students in higher education. Asian Research Journal of Mathematics, 21(4), 170-181.
[CrossRef] [Google Scholar] - Johora, F. T., Hasan, M. N., Rajbongshi, A., Ashrafuzzaman, M., & Akter, F. (2025). An explainable AI-based approach for predicting undergraduate students academic performance. Array, 26, 100384.
[CrossRef] [Google Scholar] - Khotimah, B. K., Irhamni, F. I. R. L. I., & Sundarwati, T. R. I. (2016). A Genetic algorithm for optimized initial centers K-means clustering in SMEs. Journal of Theoretical and Applied Information Technology, 90(1), 23.
[Google Scholar] - Feng, Y., Zou, J., Liu, W., & Lv, F. (2024). Distributed K-Means algorithm based on a Spark optimization sample. PLoS One, 19(12), e0308993.
[CrossRef] [Google Scholar] - Miraftabzadeh, S. M., Colombo, C. G., Longo, M., & Foiadelli, F. (2023). K-means and alternative clustering methods in modern power systems. IEEE Access, 11, 119596-119633.
[CrossRef] [Google Scholar] - Yang, S., Li, P., Wen, H., Xie, Y., & He, Z. (2018). K-hyperline clustering-based color image segmentation robust to illumination changes. Symmetry, 10(11), 610.
[CrossRef] [Google Scholar] - Ashabi, A., Sahibuddin, S. B., & Salkhordeh Haghighi, M. (2020, December). The systematic review of K-means clustering algorithm. In Proceedings of the 2020 9th international conference on networks, communication and computing (pp. 13-18).
[CrossRef] [Google Scholar] - Tan, L. (2015, April). A clustering K-means algorithm based on improved PSO algorithm. In 2015 Fifth International Conference on Communication Systems and Network Technologies (pp. 940-944). IEEE.
[CrossRef] [Google Scholar] - Li, H., Wang, J., Ren, Y., & Mao, F. (2021). Intercity online car-hailing travel demand prediction via a Spatiotemporal Transformer Method. Applied Sciences, 11(24), 11750.
[CrossRef] [Google Scholar] - Zhang, X., Lauber, L., Liu, H., Shi, J., Wu, J., & Pan, Y. (2021). Research on the method of travel area clustering of urban public transport based on Sage-Husa adaptive filter and improved DBSCAN algorithm. PLoS one, 16(12), e0259472.
[CrossRef] [Google Scholar] - Song, J., Guo, Y., & Wang, B. (2019). Research on parameter configuration method of DBSCAN clustering algorithm. Comput. Technol. Dev, 29(5), 44-48.
[Google Scholar] - Ma, B., Yang, C., Li, A., Chi, Y., & Chen, L. (2023). A faster DBSCAN algorithm based on self-adaptive determination of parameters. Procedia Computer Science, 221, 113-120.
[CrossRef] [Google Scholar] - Karypis, G., Han, E., & Kumar, V. (1999). A hierarchical clustering algorithm using dynamic modeling (Technical Report No. 99-007). University of Minnesota Digital Conservancy. Available at:https://hdl.handle.net/11299/215363
[Google Scholar] - Ranjeeth, S., Latchoumi, T. P., & Paul, P. V. (2021). Optimal stochastic gradient descent with multilayer perceptron based student's academic performance prediction model. Recent Advances in Computer Science and Communications (Formerly: Recent Patents on Computer Science), 14(6), 1728-1741.
[CrossRef] [Google Scholar] - Burman, I., & Som, S. (2019, February). Predicting students academic performance using support vector machine. In 2019 Amity international conference on artificial intelligence (AICAI) (pp. 756-759). IEEE.
[CrossRef] [Google Scholar] - Jayaprakash, S., Krishnan, S., & Jaiganesh, V. (2020, March). Predicting students academic performance using an improved random forest classifier. In 2020 international conference on emerging smart computing and informatics (ESCI) (pp. 238-243). IEEE.
[CrossRef] [Google Scholar] - Duan, D., Dai, C., & Tu, R. (2021, December). Research on the Prediction of Students' Academic Performance Based on XGBoost. In 2021 Tenth International Conference of Educational Innovation through Technology (EITT) (pp. 316-319). IEEE.
[CrossRef] [Google Scholar] - Joshi, A., Saggar, P., Jain, R., Sharma, M., Gupta, D., & Khanna, A. (2021). CatBoost—An ensemble machine learning model for prediction and classification of student academic performance. Advances in Data Science and Adaptive Analysis, 13(03n04), 2141002.
[CrossRef] [Google Scholar] - Kee, T., & Ho, W. K. (2025). Optimizing machine learning models for urban sciences: a comparative analysis of hyperparameter tuning methods. Urban Science, 9(9), 348.
[CrossRef] [Google Scholar] - Zhang, W., Cheng, S., & Lu, F. (2026). A geographic evolutionary framework with multi-task optimization of automatic hyperparameter tuning for spatially stratified machine learning models. International Journal of Geographical Information Science, 40(1), 25-48.
[CrossRef] [Google Scholar]
Cite This Article
TY - JOUR AU - Wu, Meiting PY - 2026 DA - 2026/03/07 TI - K-Means Clustering-Based Feature Generation for Student Performance Prediction JO - ICCK Transactions on Educational Data Mining T2 - ICCK Transactions on Educational Data Mining JF - ICCK Transactions on Educational Data Mining VL - 2 IS - 1 SP - 14 EP - 28 DO - 10.62762/TEDM.2026.716076 UR - https://www.icck.org/article/abs/TEDM.2026.716076 KW - clustering feature generation KW - academic performance prediction KW - educational data mining KW - machine learning KW - clustering algorithm AB - With the development of educational technology and the accumulation of big data, student performance prediction has become a hot topic in the field of education. However, traditional manual statistical methods have limitations in dealing with complex data and are difficult to achieve high-precision prediction. To address this gap, this study proposes a clustering-based feature generation framework to enhance prediction performance. Firstly, the multilayer perceptron (MLP) model is employed to evaluate the effectiveness of the clustering algorithms (K-Means, DBSCAN, and hierarchical clustering) for feature generation. Then, the best clustering algorithm (K-Means) is applied to generate features that are subsequently integrated with original features to construct augmented datasets. Subsequently, grid search is adopted to optimize model hyperparameters, and six machine learning models, including MLP, support vector machine, random forest, Bagging, XGBoost, and CatBoost, are trained and evaluated on datasets with and without clustering-generated features. Experimental results demonstrate that K-Means-based feature generation can effectively improve prediction performance under certain conditions. However, the performance gains are influenced by data characteristics, feature distributions, and model structures. The findings also reveal that clustering-derived features do not universally enhance all machine learning algorithms, highlighting the necessity of selecting appropriate model–feature integration strategies in practical applications. SN - 3070-5843 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Wu2026KMeans,
author = {Meiting Wu},
title = {K-Means Clustering-Based Feature Generation for Student Performance Prediction},
journal = {ICCK Transactions on Educational Data Mining},
year = {2026},
volume = {2},
number = {1},
pages = {14-28},
doi = {10.62762/TEDM.2026.716076},
url = {https://www.icck.org/article/abs/TEDM.2026.716076},
abstract = {With the development of educational technology and the accumulation of big data, student performance prediction has become a hot topic in the field of education. However, traditional manual statistical methods have limitations in dealing with complex data and are difficult to achieve high-precision prediction. To address this gap, this study proposes a clustering-based feature generation framework to enhance prediction performance. Firstly, the multilayer perceptron (MLP) model is employed to evaluate the effectiveness of the clustering algorithms (K-Means, DBSCAN, and hierarchical clustering) for feature generation. Then, the best clustering algorithm (K-Means) is applied to generate features that are subsequently integrated with original features to construct augmented datasets. Subsequently, grid search is adopted to optimize model hyperparameters, and six machine learning models, including MLP, support vector machine, random forest, Bagging, XGBoost, and CatBoost, are trained and evaluated on datasets with and without clustering-generated features. Experimental results demonstrate that K-Means-based feature generation can effectively improve prediction performance under certain conditions. However, the performance gains are influenced by data characteristics, feature distributions, and model structures. The findings also reveal that clustering-derived features do not universally enhance all machine learning algorithms, highlighting the necessity of selecting appropriate model–feature integration strategies in practical applications.},
keywords = {clustering feature generation, academic performance prediction, educational data mining, machine learning, clustering algorithm},
issn = {3070-5843},
publisher = {Institute of Central Computation and Knowledge}
}
Article Metrics
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions

Portico
