Abstract
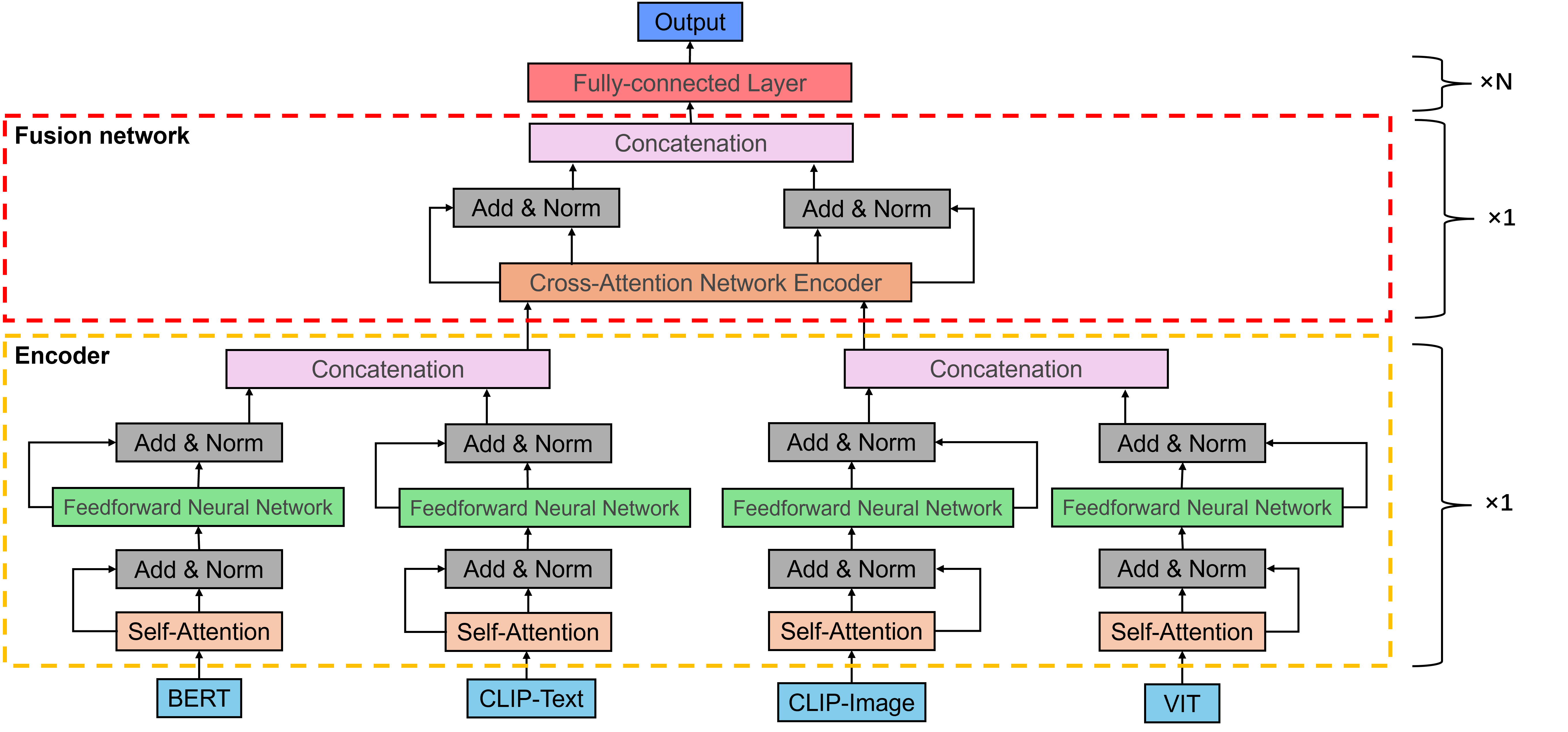
Multimodal Sentiment Analysis (MSA), a pivotal task in affective computing, aims to enhance sentiment understanding by integrating heterogeneous data from modalities such as text, images, and audio. However, existing methods continue to face challenges in semantic alignment, modality fusion, and interpretability. To address these limitations, we propose VBCSNet, a hybrid attention-based multimodal framework that leverages the complementary strengths of Vision Transformer (ViT), BERT, and CLIP architectures. VBCSNet employs a Structured Self-Attention (SSA) mechanism to optimize intra-modal feature representation and a Cross-Attention module to achieve fine-grained semantic alignment across modalities. Furthermore, we introduce a multi-objective optimization strategy that jointly minimizes classification loss, modality alignment loss, and contrastive loss, thereby enhancing semantic consistency and feature discriminability. We evaluated VBCSNet on three multilingual multimodal sentiment datasets, including MVSA, IJCAI2019, and a self-constructed Japanese Twitter corpus(JP-Buzz). Experimental results demonstrated that VBCSNet significantly outperformed state-of-the-art baselines in terms of Accuracy, Macro-F1, and cross-lingual generalization. Per-class performance analysis further highlighted the model’s interpretability and robustness. Overall, VBCSNet advances sentiment classification across languages and domains while offering a transparent reasoning mechanism suitable for real-world applications in affective computing, human-computer interaction, and socially aware AI systems.
Keywords
multimodal sentiment analysis
vision-language models
structured self-attention
cross-attention
contrastive learning
interpretability
cross-lingual evaluation
Data Availability Statement
Data will be made available on request.
Funding
This work was supported by the JSPS KAKENHI under Grant JP20K12027 and by JKA and its promotion funds from KEIRIN RACE.
Conflicts of Interest
The authors declare no conflicts of interest.
Ethical Approval and Consent to Participate
Not applicable.
Cite This Article
APA Style
Liu, Y., Kang, X., Matsumoto, K., & Zhou, J. (2025). VBCSNet: A Hybrid Attention-Based Multimodal Framework with Structured Self-Attention for Sentiment Classification. Chinese Journal of Information Fusion, 2(4), 356–369. https://doi.org/10.62762/CJIF.2025.537775
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions

Copyright © 2025 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (
https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.

 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue