ICCK Transactions on Educational Data Mining
ISSN: pending (Online)
Email: [email protected]

 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue

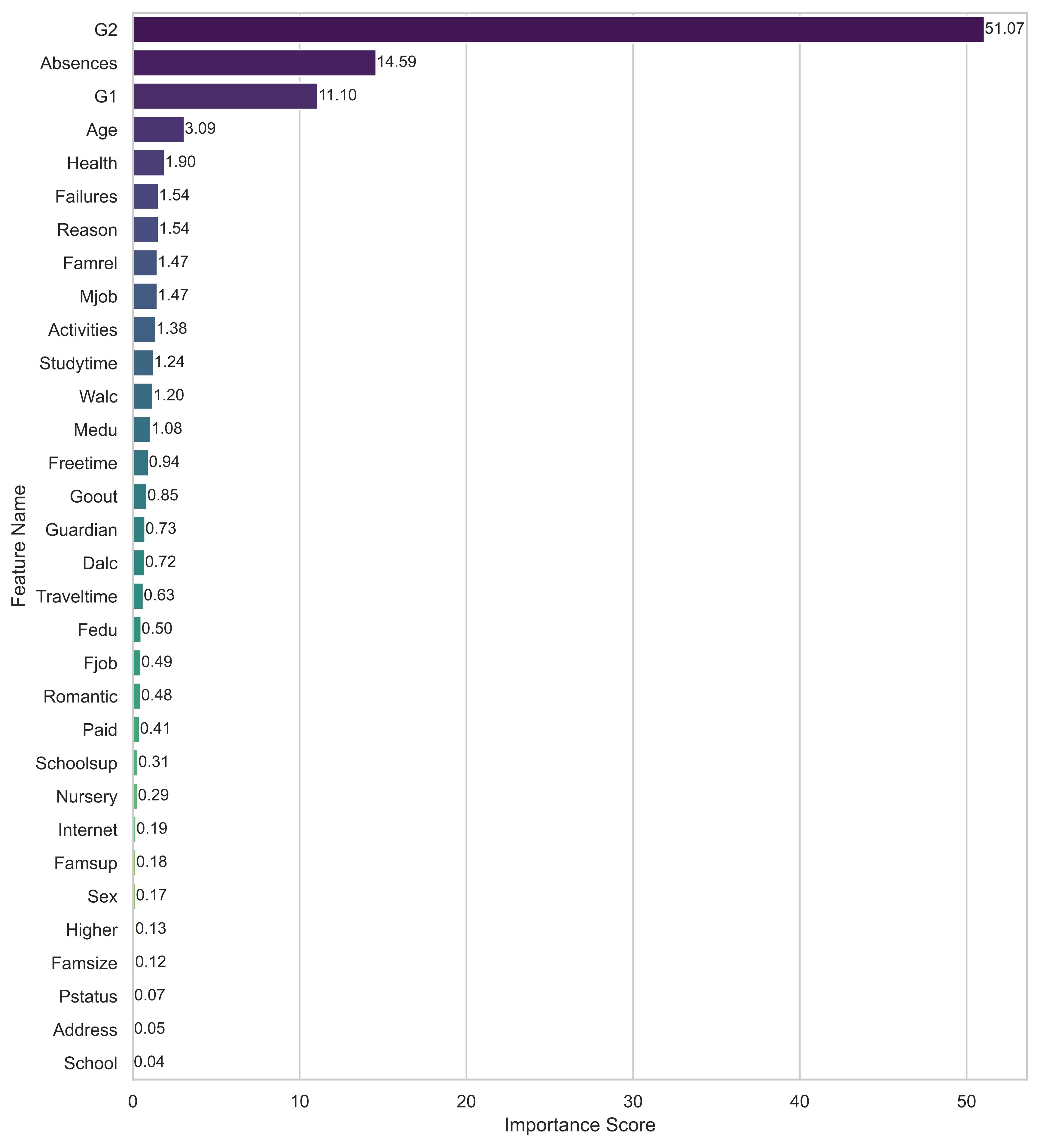
TY - JOUR AU - Weng, Shaoyuan AU - Zheng, Yuanyuan AU - Zhang, Chao AU - Liu, Zimeng PY - 2025 DA - 2025/11/28 TI - A Gradient Boosting-Based Feature Selection Framework for Predicting Student Performance JO - ICCK Transactions on Educational Data Mining T2 - ICCK Transactions on Educational Data Mining JF - ICCK Transactions on Educational Data Mining VL - 1 IS - 1 SP - 25 EP - 35 DO - 10.62762/TEDM.2025.414136 UR - https://www.icck.org/article/abs/TEDM.2025.414136 KW - feature selection KW - gradient boosting KW - student performance prediction KW - educational data mining AB - In educational data mining, accurate prediction of student performance is important for supporting timely intervention for at-risk students. However, educational datasets often include irrelevant or redundant features that could reduce the performance of prediction models. To tackle this issue, this study proposes a gradient boosting-based feature selection framework that can automatically identify and obtain the most important features for student performance prediction. The proposed framework leverages the gradient boosting model to calculate feature importance and refine the feature subset, aiming to achieve comparable or superior prediction performance using fewer but important input features. To ensure a robust evaluation of the results, we apply a 10-fold cross-validation strategy with 10 repetitions. Experimental results on the Mathematics and Portuguese Language course datasets demonstrate that the proposed framework is able to consistently outperform the baseline models in terms of the evaluation metrics used. These findings highlight the effectiveness of the proposed feature selection for student performance, which makes it a reliable tool for data-driven educational analytics. SN - pending PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Weng2025A,
author = {Shaoyuan Weng and Yuanyuan Zheng and Chao Zhang and Zimeng Liu},
title = {A Gradient Boosting-Based Feature Selection Framework for Predicting Student Performance},
journal = {ICCK Transactions on Educational Data Mining},
year = {2025},
volume = {1},
number = {1},
pages = {25-35},
doi = {10.62762/TEDM.2025.414136},
url = {https://www.icck.org/article/abs/TEDM.2025.414136},
abstract = {In educational data mining, accurate prediction of student performance is important for supporting timely intervention for at-risk students. However, educational datasets often include irrelevant or redundant features that could reduce the performance of prediction models. To tackle this issue, this study proposes a gradient boosting-based feature selection framework that can automatically identify and obtain the most important features for student performance prediction. The proposed framework leverages the gradient boosting model to calculate feature importance and refine the feature subset, aiming to achieve comparable or superior prediction performance using fewer but important input features. To ensure a robust evaluation of the results, we apply a 10-fold cross-validation strategy with 10 repetitions. Experimental results on the Mathematics and Portuguese Language course datasets demonstrate that the proposed framework is able to consistently outperform the baseline models in terms of the evaluation metrics used. These findings highlight the effectiveness of the proposed feature selection for student performance, which makes it a reliable tool for data-driven educational analytics.},
keywords = {feature selection, gradient boosting, student performance prediction, educational data mining},
issn = {pending},
publisher = {Institute of Central Computation and Knowledge}
}

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/