

ICCK Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3068-6652 (Online)
Email: [email protected]
 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue

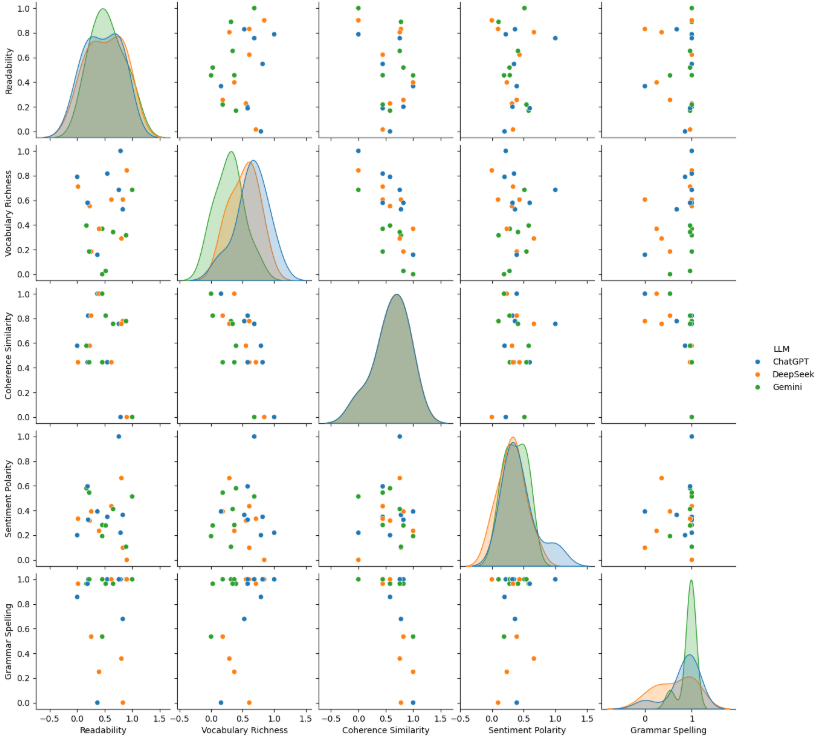
TY - JOUR AU - Nasa, Qazi Novera Tansue AU - Das, Ashik Chandra PY - 2026 DA - 2026/02/01 TI - An NLP-Based Evaluation of LLMs Across Creativity, Factual Accuracy, Open-Ended and Technical Explanations JO - ICCK Transactions on Emerging Topics in Artificial Intelligence T2 - ICCK Transactions on Emerging Topics in Artificial Intelligence JF - ICCK Transactions on Emerging Topics in Artificial Intelligence VL - 3 IS - 2 SP - 76 EP - 85 DO - 10.62762/TETAI.2025.264517 UR - https://www.icck.org/article/abs/TETAI.2025.264517 KW - LLMs evaluation KW - NLP KW - ChatGPT KW - Gemini KW - DeepSeek KW - ANOVA AB - The rapid advancement of AI-based language models has transformed the field of Natural Language Processing (NLP) into a powerful tool for text generation. This study evaluates the performance of models in different categories such as factual accuracy, creative writing, open-ended writing, and technical explanation. We have considered three popular and advanced large language models (LLMs) for this analysis. To quantify their performance, we have applied a combination of statistical and linguistic metrics. We have used Dale-Chall to analyze the readability score of the responses. For lexical diversity, we have used the type-token ratio technique. In addition, a cosine similarity with TF-IDF is used for semantic similarity. Furthermore, sentiment polarity and grammatical correctness are also analyzed. Moreover, we have conducted an F-test to determine whether the differences in performance among the LLMs are statistically significant (p < 0.05). We have found minimal differences between LLMs, with ChatGPT showing slightly better performance compared to the others. SN - 3068-6652 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Nasa2026An,
author = {Qazi Novera Tansue Nasa and Ashik Chandra Das},
title = {An NLP-Based Evaluation of LLMs Across Creativity, Factual Accuracy, Open-Ended and Technical Explanations},
journal = {ICCK Transactions on Emerging Topics in Artificial Intelligence},
year = {2026},
volume = {3},
number = {2},
pages = {76-85},
doi = {10.62762/TETAI.2025.264517},
url = {https://www.icck.org/article/abs/TETAI.2025.264517},
abstract = {The rapid advancement of AI-based language models has transformed the field of Natural Language Processing (NLP) into a powerful tool for text generation. This study evaluates the performance of models in different categories such as factual accuracy, creative writing, open-ended writing, and technical explanation. We have considered three popular and advanced large language models (LLMs) for this analysis. To quantify their performance, we have applied a combination of statistical and linguistic metrics. We have used Dale-Chall to analyze the readability score of the responses. For lexical diversity, we have used the type-token ratio technique. In addition, a cosine similarity with TF-IDF is used for semantic similarity. Furthermore, sentiment polarity and grammatical correctness are also analyzed. Moreover, we have conducted an F-test to determine whether the differences in performance among the LLMs are statistically significant (p < 0.05). We have found minimal differences between LLMs, with ChatGPT showing slightly better performance compared to the others.},
keywords = {LLMs evaluation, NLP, ChatGPT, Gemini, DeepSeek, ANOVA},
issn = {3068-6652},
publisher = {Institute of Central Computation and Knowledge}
}
 Copyright © 2026 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2026 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. ICCK Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3068-6652 (Online)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/