Abstract
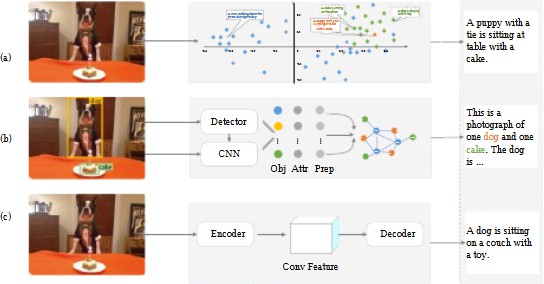
The capacity of robots to produce captions for images independently is a big step forward in the field of artificial intelligence and language understanding. This paper looks at an advanced picture captioning system that uses deep learning techniques, notably convolutional neural networks (CNNs) and recurrent neural networks (RNNs), to provide contextually appropriate and meaningful descriptions of visual content. The suggested technique extracts features using the DenseNet201 model, which allows for a more thorough and hierarchical comprehension of picture components. These collected characteristics are subsequently processed by a long short-term memory (LSTM) network, a specific RNN variation designed to capture sequential dependencies in language, resulting in captions that are coherent and fluent.The model is trained and assessed on the well-known Flickr8k dataset, attaining competitive performance as judged by BLEU score metrics and proving its capacity to provide humanlike descriptions. This use of CNNs and RNNs demonstrates the value of merging computer vision and natural language processing for automated caption development. This approach has the potential to be applied in a range of industries, including assistive technology for the visually impaired, automated content production for digital media, enhanced indexing and retrieval of multimedia assets, and improved human-computer interaction. Furthermore, advances in attention processes and transformer-based models offer opportunities to improve the accuracy and contextual relevance of picture captioning models. The study emphasizes machine-generated captions’ larger implications for increasing accessibility, boosting searchability in large-scale databases, and enabling seamless AI-human cooperation in content interpretation and storytelling.
Keywords
convolutional neural networks (CNN)
recurrent neural networks (RNN)
deep learning
image captioning
LSTM
DenseNet201
attention mechanism
BLEU scor
natural language processing (NLP)
multimodal learning
content retrieval
Data Availability Statement
Data will be made available on request.
Funding
This work was supported without any funding.
Conflicts of Interest
The authors declare no conflicts of interest.
Ethical Approval and Consent to Participate
Not applicable.
Cite This Article
APA Style
Khan, A., & Singh, J. (2025). A Novel Image Captioning Technique Using Deep Learning Methodology. ICCK Transactions on Machine Intelligence, 1(2), 52–68. https://doi.org/10.62762/TMI.2025.886122
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions
Institute of Central Computation and Knowledge (ICCK) or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.

 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue