
ICCK Transactions on Machine Intelligence
ISSN: 3068-7403 (Online)
Email: [email protected]
 Submit Manuscript
Edit a Special Issue
Submit Manuscript
Edit a Special Issue

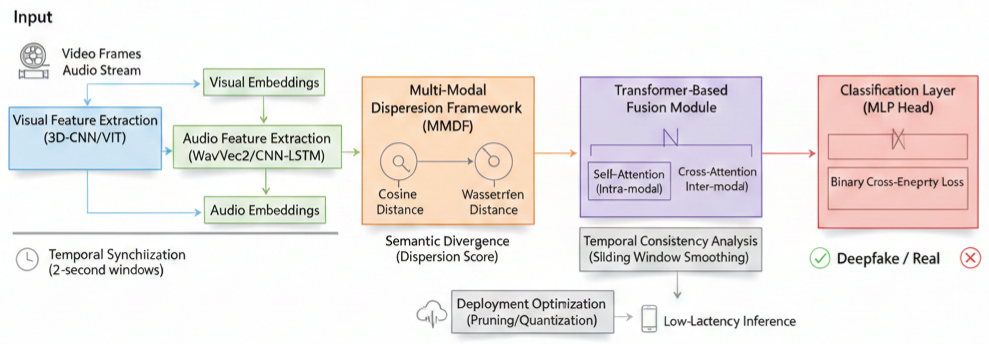
TY - JOUR AU - Banik, Barnali Gupta AU - Naziya, Shaik Nidha PY - 2026 DA - 2026/03/01 TI - Intelligent Deepfake Detector Using Audio-Visual Clues JO - ICCK Transactions on Machine Intelligence T2 - ICCK Transactions on Machine Intelligence JF - ICCK Transactions on Machine Intelligence VL - 2 IS - 2 SP - 100 EP - 105 DO - 10.62762/TMI.2025.601369 UR - https://www.icck.org/article/abs/TMI.2025.601369 KW - deepfake detection KW - multi-modal dispersion KW - audio-visual clues KW - cross-modal inconsistency KW - lip-sync analysis KW - AI forensics KW - transformer fusion AB - Deepfake media is growing rapidly and causing significant harm. Bad actors now use AI to create fake videos that appear increasingly realistic. Traditional detection tools often fail because they analyze audio or visual signals in isolation. This paper introduces an intelligent Deepfake Detection system that addresses this limitation through a novel Multi-Modal Dispersion Framework. The system identifies subtle inconsistencies by tracking how lip movements align with speech patterns. By projecting these features into a shared latent space, the model quantifies the semantic divergence between modalities. A transformer module then captures cross-modal context to detect fine-grained manipulation artifacts. Evaluated on the DFDC and FakeAVCeleb datasets, the system achieves 94.3% accuracy, demonstrating strong potential for real-time deployment. This framework provides a reliable approach to media authentication and contributes to advancing AI safety. SN - 3068-7403 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Banik2026Intelligen,
author = {Barnali Gupta Banik and Shaik Nidha Naziya},
title = {Intelligent Deepfake Detector Using Audio-Visual Clues},
journal = {ICCK Transactions on Machine Intelligence},
year = {2026},
volume = {2},
number = {2},
pages = {100-105},
doi = {10.62762/TMI.2025.601369},
url = {https://www.icck.org/article/abs/TMI.2025.601369},
abstract = {Deepfake media is growing rapidly and causing significant harm. Bad actors now use AI to create fake videos that appear increasingly realistic. Traditional detection tools often fail because they analyze audio or visual signals in isolation. This paper introduces an intelligent Deepfake Detection system that addresses this limitation through a novel Multi-Modal Dispersion Framework. The system identifies subtle inconsistencies by tracking how lip movements align with speech patterns. By projecting these features into a shared latent space, the model quantifies the semantic divergence between modalities. A transformer module then captures cross-modal context to detect fine-grained manipulation artifacts. Evaluated on the DFDC and FakeAVCeleb datasets, the system achieves 94.3\% accuracy, demonstrating strong potential for real-time deployment. This framework provides a reliable approach to media authentication and contributes to advancing AI safety.},
keywords = {deepfake detection, multi-modal dispersion, audio-visual clues, cross-modal inconsistency, lip-sync analysis, AI forensics, transformer fusion},
issn = {3068-7403},
publisher = {Institute of Central Computation and Knowledge}
}

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/icck/