M-SAITS: A Dual-Stage Time Series Imputation Network via Decoupled Large-Kernel Convolution and Diagonally-Masked Attention



Article Information
Abstract
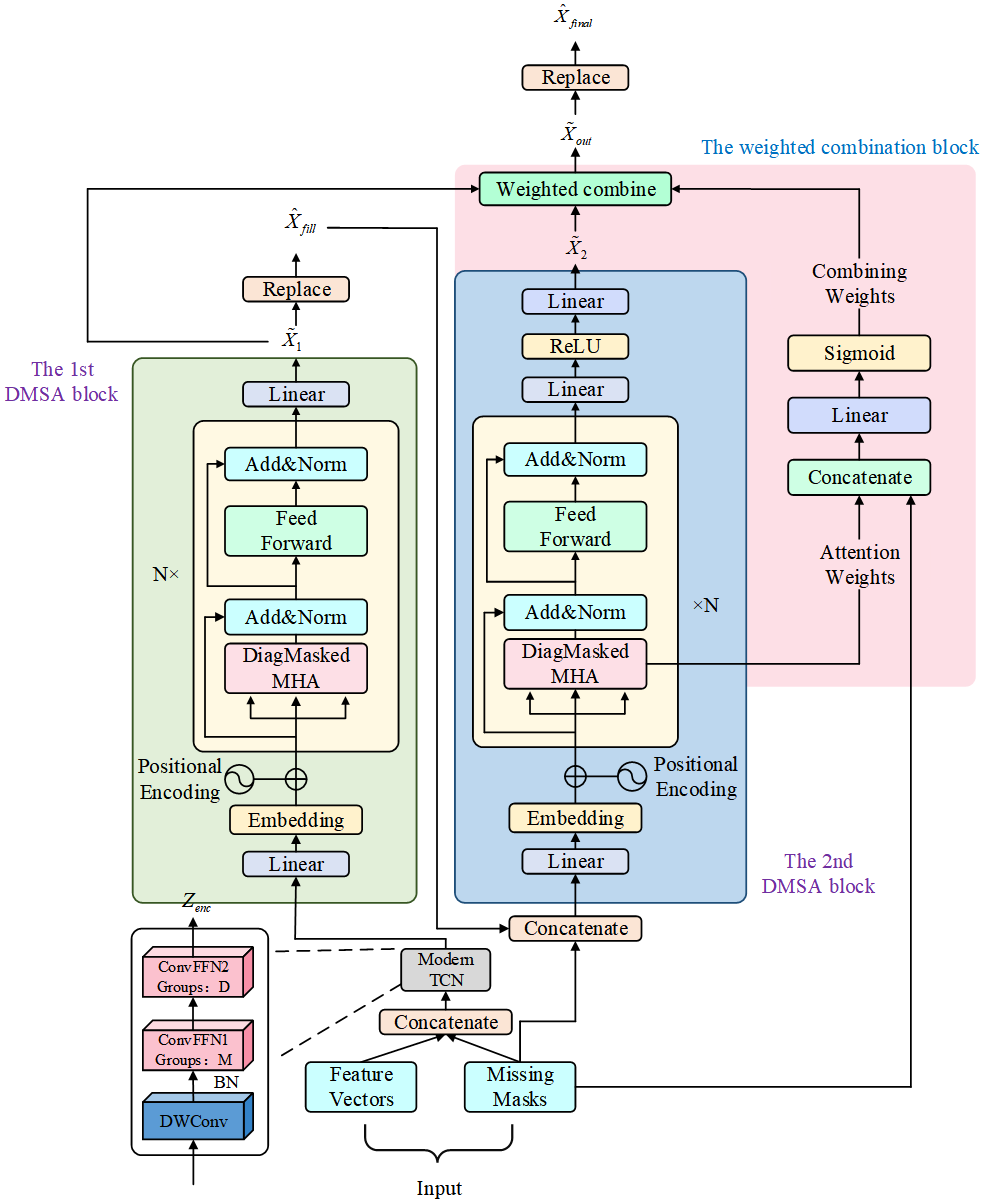
Missing value imputation in multivariate time series is a critical challenge in the field of data mining. Although Transformer-based methods excel in modeling long-range dependencies, their inherent point-wise attention mechanisms often lack explicit modeling of local inductive biases in time series, making it difficult to effectively capture local smoothness and evolutionary trends. Furthermore, existing feature embedding strategies struggle to fully decouple the internal temporal evolution of variables from complex cross-variable dependencies. To address these limitations, this paper proposes a novel dual-stage imputation framework named M-SAITS. This framework innovatively introduces a decoupled feature encoder based on large-kernel depthwise convolutions. By utilizing an extended effective receptive field, it explicitly enhances the model's perception of local trends. Additionally, it employs a grouped convolution structure to achieve decoupled modeling of intra-variable temporal patterns and inter-variable interaction features. On this basis, combined with a Diagonally-Masked Self-Attention mechanism, the framework physically blocks information leakage paths while achieving lossless global context aggregation. Relying on a "Preliminary Inference–Iterative Refinement" cascade strategy and a masked weighted joint optimization objective, the model achieves high-fidelity data reconstruction. Extensive experiments on multiple benchmark datasets, such as Electricity and Air Quality, demonstrate that this method significantly outperforms existing state-of-the-art models across multiple evaluation metrics. Notably, in high-dimensional electricity data imputation tasks, M-SAITS achieves substantial performance improvements over baseline models such as CSDI and Transformer, with the Mean Absolute Error significantly reduced (up to approximately 60% under low missing rates).
Graphical Abstract
Keywords
Data Availability Statement
Funding
Conflicts of Interest
AI Use Statement
Ethical Approval and Consent to Participate
References
- Li, L., Zhang, J., Wang, Y., & Ran, B. (2018). Missing value imputation for traffic-related time series data based on a multi-view learning method. IEEE Transactions on Intelligent Transportation Systems, 20(8), 2933-2943.
[CrossRef] [Google Scholar] - Ren, H., Wang, Y., & Ma, H. (2024). Deep prediction network based on covariance intersection fusion for sensor data. ICCK Transactions on Intelligent Systematics, 1(1), 10-18.
[CrossRef] [Google Scholar] - Wang, J., Du, W., Yang, Y., Qian, L., Cao, W., Zhang, K., ... & Wen, Q. (2024). Deep learning for multivariate time series imputation: A survey. arXiv preprint arXiv:2402.04059.
[CrossRef] [Google Scholar] - Wang, J., Du, W., Yang, Y., Qian, L., Cao, W., Zhang, K., ... & Wen, Q. (2025, August). Deep learning for multivariate time series imputation: a survey. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (pp. 10696-10704).
[CrossRef] [Google Scholar] - Che, Z., Purushotham, S., Cho, K., Sontag, D., & Liu, Y. (2018). Recurrent neural networks for multivariate time series with missing values. Scientific Reports, 8(1), 6085.
[CrossRef] [Google Scholar] - Cao, W., Wang, D., Li, J., Zhou, H., Li, L., & Li, Y. (2018). BRITS: Bidirectional recurrent imputation for time series. Advances in Neural Information Processing Systems, 31.
[Google Scholar] - Yoon, J., Jordon, J., & Schaar, M. (2018, July). Gain: Missing data imputation using generative adversarial nets. In International conference on machine learning (pp. 5689-5698). PMLR.
[Google Scholar] - Miao, X., Wu, Y., Wang, J., Gao, Y., Mao, X., & Yin, J. (2021). Generative semi-supervised learning for multivariate time series imputation. In AAAI Conference on Artificial Intelligence (Vol. 35, No. 10, pp. 8983-8991).
[CrossRef] [Google Scholar] - Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.
[Google Scholar] - Du, W., Côté, D., & Liu, Y. (2023). Saits: Self-attention-based imputation for time series. Expert Systems with Applications, 219, 119619.
[CrossRef] [Google Scholar] - Wu, H., Xu, J., Wang, J., & Long, M. (2021). Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems, 34, 22419-22430.
[Google Scholar] - Qiu, Y., Zhou, G., Zhao, Q., & Xie, S. (2022). Noisy tensor completion via low-rank tensor ring. IEEE Transactions on Neural Networks and Learning Systems, 35(1), 1127-1141.
[CrossRef] [Google Scholar] - Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., & Long, M. (2023). TimesNet: Temporal 2D-variation modeling for general time series analysis. In International Conference on Learning Representations.
[Google Scholar] - Luo, D., & Wang, C. (2024). ModernTCN: A modern pure convolution structure for general time series analysis. In International Conference on Learning Representations.
[Google Scholar] - Tashiro, Y., Song, J., Song, Y., & Ermon, S. (2021). CSDI: Conditional score-based diffusion models for probabilistic time series imputation. Advances in Neural Information Processing Systems, 34, 24804-24816.
[Google Scholar] - Fortuin, V., Baranchuk, D., Rätsch, G., & Mandt, S. (2020, June). Gp-vae: Deep probabilistic time series imputation. In International conference on artificial intelligence and statistics (pp. 1651-1661). PMLR.
[Google Scholar] - Zhang, S., Guo, B., Dong, A., He, J., Xu, Z., & Chen, S. (2017). Cautionary tales on air-quality improvement in Beijing. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 473(2205), 20170457.
[CrossRef] [Google Scholar] - Dua, D., & Graff, C. (2017). UCI machine learning repository, 2017. URL http://archive. ics. uci. edu/ml, 7(1), 62.
[Google Scholar] - Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., & Zhang, W. (2021, May). Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence (Vol. 35, No. 12, pp. 11106-11115).
[CrossRef] [Google Scholar]
Cite This Article
TY - JOUR AU - Su, Tingli AU - Wang, Gongxin AU - Bai, Yuting AU - Wan, Rui PY - 2026 DA - 2026/03/08 TI - M-SAITS: A Dual-Stage Time Series Imputation Network via Decoupled Large-Kernel Convolution and Diagonally-Masked Attention JO - ICCK Transactions on Machine Intelligence T2 - ICCK Transactions on Machine Intelligence JF - ICCK Transactions on Machine Intelligence VL - 2 IS - 2 SP - 106 EP - 115 DO - 10.62762/TMI.2026.671182 UR - https://www.icck.org/article/abs/TMI.2026.671182 KW - time series imputation KW - large-kernel convolution KW - decoupled feature representation KW - diagonally-masked attention KW - self-supervised learning AB - Missing value imputation in multivariate time series is a critical challenge in the field of data mining. Although Transformer-based methods excel in modeling long-range dependencies, their inherent point-wise attention mechanisms often lack explicit modeling of local inductive biases in time series, making it difficult to effectively capture local smoothness and evolutionary trends. Furthermore, existing feature embedding strategies struggle to fully decouple the internal temporal evolution of variables from complex cross-variable dependencies. To address these limitations, this paper proposes a novel dual-stage imputation framework named M-SAITS. This framework innovatively introduces a decoupled feature encoder based on large-kernel depthwise convolutions. By utilizing an extended effective receptive field, it explicitly enhances the model's perception of local trends. Additionally, it employs a grouped convolution structure to achieve decoupled modeling of intra-variable temporal patterns and inter-variable interaction features. On this basis, combined with a Diagonally-Masked Self-Attention mechanism, the framework physically blocks information leakage paths while achieving lossless global context aggregation. Relying on a "Preliminary Inference–Iterative Refinement" cascade strategy and a masked weighted joint optimization objective, the model achieves high-fidelity data reconstruction. Extensive experiments on multiple benchmark datasets, such as Electricity and Air Quality, demonstrate that this method significantly outperforms existing state-of-the-art models across multiple evaluation metrics. Notably, in high-dimensional electricity data imputation tasks, M-SAITS achieves substantial performance improvements over baseline models such as CSDI and Transformer, with the Mean Absolute Error significantly reduced (up to approximately 60% under low missing rates). SN - 3068-7403 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Su2026MSAITS,
author = {Tingli Su and Gongxin Wang and Yuting Bai and Rui Wan},
title = {M-SAITS: A Dual-Stage Time Series Imputation Network via Decoupled Large-Kernel Convolution and Diagonally-Masked Attention},
journal = {ICCK Transactions on Machine Intelligence},
year = {2026},
volume = {2},
number = {2},
pages = {106-115},
doi = {10.62762/TMI.2026.671182},
url = {https://www.icck.org/article/abs/TMI.2026.671182},
abstract = {Missing value imputation in multivariate time series is a critical challenge in the field of data mining. Although Transformer-based methods excel in modeling long-range dependencies, their inherent point-wise attention mechanisms often lack explicit modeling of local inductive biases in time series, making it difficult to effectively capture local smoothness and evolutionary trends. Furthermore, existing feature embedding strategies struggle to fully decouple the internal temporal evolution of variables from complex cross-variable dependencies. To address these limitations, this paper proposes a novel dual-stage imputation framework named M-SAITS. This framework innovatively introduces a decoupled feature encoder based on large-kernel depthwise convolutions. By utilizing an extended effective receptive field, it explicitly enhances the model's perception of local trends. Additionally, it employs a grouped convolution structure to achieve decoupled modeling of intra-variable temporal patterns and inter-variable interaction features. On this basis, combined with a Diagonally-Masked Self-Attention mechanism, the framework physically blocks information leakage paths while achieving lossless global context aggregation. Relying on a "Preliminary Inference–Iterative Refinement" cascade strategy and a masked weighted joint optimization objective, the model achieves high-fidelity data reconstruction. Extensive experiments on multiple benchmark datasets, such as Electricity and Air Quality, demonstrate that this method significantly outperforms existing state-of-the-art models across multiple evaluation metrics. Notably, in high-dimensional electricity data imputation tasks, M-SAITS achieves substantial performance improvements over baseline models such as CSDI and Transformer, with the Mean Absolute Error significantly reduced (up to approximately 60\% under low missing rates).},
keywords = {time series imputation, large-kernel convolution, decoupled feature representation, diagonally-masked attention, self-supervised learning},
issn = {3068-7403},
publisher = {Institute of Central Computation and Knowledge}
}
Article Metrics
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions

Portico
