by
,
ICCK Transactions on Systems Safety and Reliability | Volume 2, Issue 3: 162-175, 2026 | DOI: 10.62762/TSSR.2026.881557
Abstract
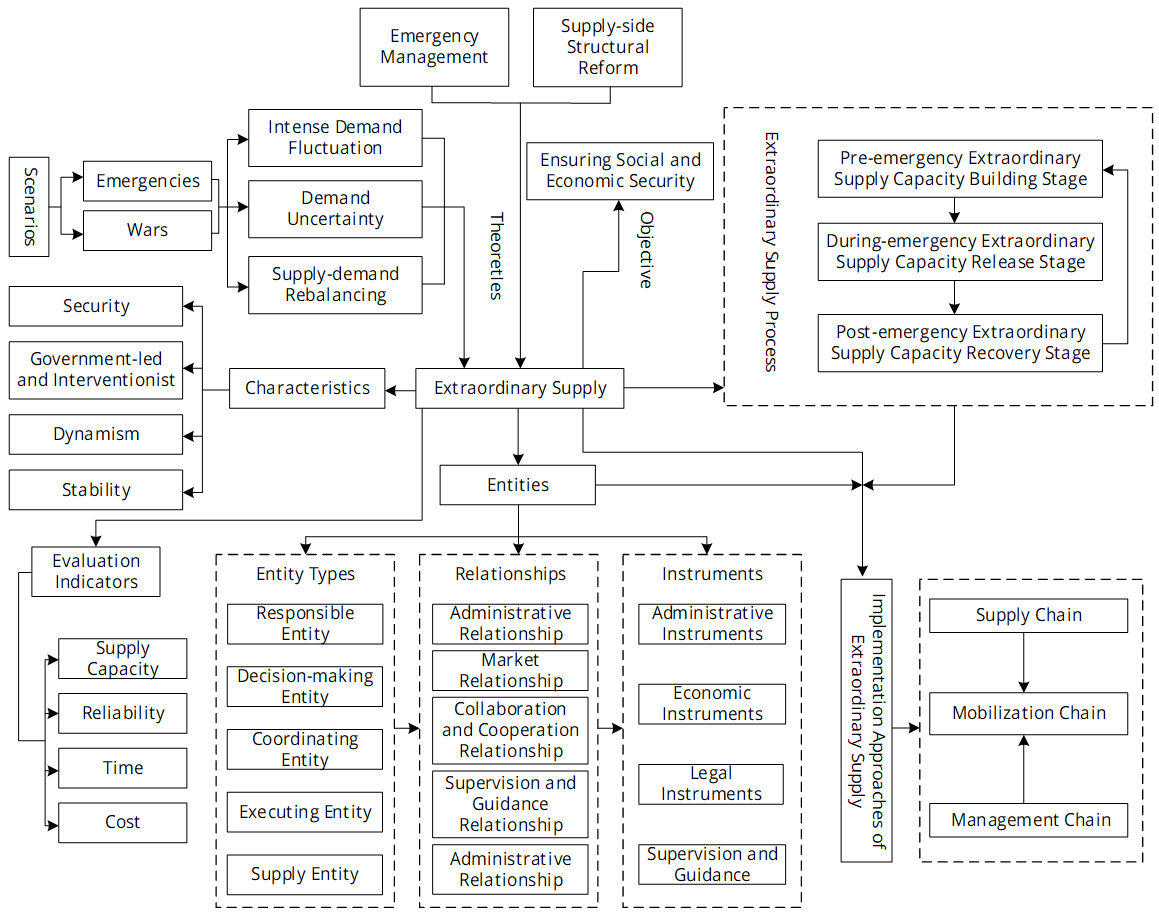
To address the practical challenge of severe supply-demand imbalances for emergency supplies in highly uncertain emergencies, this paper systematically explores the construction and design of emergency supplies mobilization chains based on the extraordinary supply theory. First, it analyzes the dissipative structural properties of the emergency supplies support system as a complex system, pointing out that its core objective is to achieve dynamic supply-demand balance throughout its lifetime through the transition between normal and extraordinary supply. Second, it clarifies the concept and connotation of the emergency supplies mobilization chain, revealing its chain structure composed of th... More >
Graphical Abstract