DMFuse: Diffusion Model Guided Cross-Attention Learning for Infrared and Visible Image Fusion




Article Information
Abstract
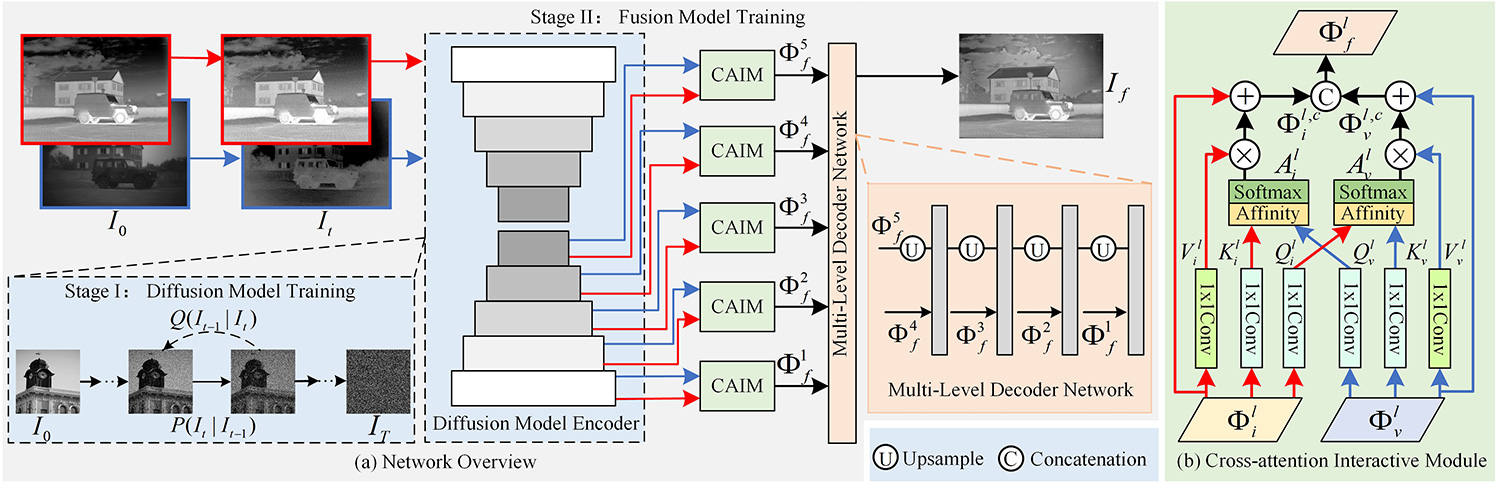
Image fusion aims to integrate complementary information from different sensors into a single fused output for superior visual description and scene understanding. The existing GAN-based fusion methods generally suffer from multiple challenges, such as unexplainable mechanism, unstable training, and mode collapse, which may affect the fusion quality. To overcome these limitations, this paper introduces a diffusion model guided cross-attention learning network, termed as DMFuse, for infrared and visible image fusion. Firstly, to improve the diffusion inference efficiency, we compress the quadruple channels of the denoising UNet network to achieve more efficient and robust model for fusion tasks. After that, we employ the pre-trained diffusion model as an autoencoder and incorporate its strong generative priors to further train the following fusion network. This design allows the generated diffusion features to effectively showcase high-quality distribution mapping ability. In addition, we devise a cross-attention interactive fusion module to establish the long-range dependencies from local diffusion features. This module integrates the global interactions to improve the complementary characteristics of different modalities. Finally, we propose a multi-level decoder network to reconstruct the fused output. Extensive experiments on fusion tasks and downstream applications, including object detection and semantic segmentation, indicate that the proposed model yields promising performance while maintaining competitive computational efficiency. The code and data are available at https://github.com/Zhishe-Wang/DMFuse.
Code (Data) Available
Graphical Abstract
Keywords
Data Availability Statement
Funding
Conflicts of Interest
Ethical Approval and Consent to Participate
References
- Liu, J., Wang, J., Huang, N., Zhang, Q., & Han, J. (2022). Revisiting modality-specific feature compensation for visible-infrared person re-identification. IEEE Transactions on Circuits and Systems for Video Technology, 32(10), 7226-7240.
[CrossRef] [Google Scholar] - Wang, J., Song, K., Bao, Y., Huang, L., & Yan, Y. (2021). CGFNet: Cross-guided fusion network for RGB-T salient object detection. IEEE Transactions on Circuits and Systems for Video Technology, 32(5), 2949-2961.
[CrossRef] [Google Scholar] - Wang, Y., Wei, X., Tang, X., Yu, K., & Luo, L. (2023). RGBT tracking using randomly projected CNN features. Expert Systems with Applications, 223, 119865.
[CrossRef] [Google Scholar] - Chen, J., Li, X., Luo, L., Mei, X., & Ma, J. (2020). Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Information Sciences, 508, 64-78.
[CrossRef] [Google Scholar] - Li, H., Wu, X. J., & Kittler, J. (2020). MDLatLRR: A novel decomposition method for infrared and visible image fusion. IEEE Transactions on Image Processing, 29, 4733-4746.
[CrossRef] [Google Scholar] - Kong, W., Lei, Y., & Zhao, H. (2014). Adaptive fusion method of visible light and infrared images based on non-subsampled shearlet transform and fast non-negative matrix factorization. Infrared Physics & Technology, 67, 161-172.
[CrossRef] [Google Scholar] - Ma, C., Nie, R., Ding, H., Cao, J., & Mei, J. (2023). A fractional-order variation with a novel norm to fuse infrared and visible images. IEEE Transactions on Instrumentation and Measurement, 72, 1-12.
[CrossRef] [Google Scholar] - Zou, D., & Yang, B. (2023). Infrared and low-light visible image fusion based on hybrid multiscale decomposition and adaptive light adjustment. Optics and Lasers in Engineering, 160, 107268.
[CrossRef] [Google Scholar] - Zhao, Z., Xu, S., Zhang, C., Liu, J., & Zhang, J. (2020). Bayesian fusion for infrared and visible images. Signal Processing, 177, 107734.
[CrossRef] [Google Scholar] - Li, H., & Wu, X. J. (2018). DenseFuse: A fusion approach to infrared and visible images. IEEE Transactions on Image Processing, 28(5), 2614-2623.
[CrossRef] [Google Scholar] - Li, H., Wu, X. J., & Durrani, T. (2020). NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Transactions on Instrumentation and Measurement, 69(12), 9645-9656.
[CrossRef] [Google Scholar] - Xu, H., Ma, J., Jiang, J., Guo, X., & Ling, H. (2020). U2Fusion: A unified unsupervised image fusion network. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(1), 502-518.
[CrossRef] [Google Scholar] - Li, H., Wu, X. J., & Kittler, J. (2021). RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Information Fusion, 73, 72-86.
[CrossRef] [Google Scholar] - Pang, S., Huo, H., Liu, X., Zheng, B., & Li, J. (2024). SDTFusion: A split-head dense transformer based network for infrared and visible image fusion. Infrared Physics & Technology, 138, 105209.
[CrossRef] [Google Scholar] - Tang, W., He, F., & Liu, Y. (2022). YDTR: Infrared and visible image fusion via Y-shape dynamic transformer. IEEE Transactions on Multimedia, 25, 5413-5428.
[CrossRef] [Google Scholar] - Ma, J., Yu, W., Liang, P., Li, C., & Jiang, J. (2019). FusionGAN: A generative adversarial network for infrared and visible image fusion. Information Fusion, 48, 11-26.
[CrossRef] [Google Scholar] - Ma, J., Zhang, H., Shao, Z., Liang, P., & Xu, H. (2020). GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Transactions on Instrumentation and Measurement, 70, 1-14.
[CrossRef] [Google Scholar] - Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
[Google Scholar] - Zhao, Z., Bai, H., Zhu, Y., Zhang, J., Xu, S., Zhang, Y., ... & Van Gool, L. (2023). DDFM: denoising diffusion model for multi-modality image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8082-8093).
[CrossRef] [Google Scholar] - Yue, J., Fang, L., Xia, S., Deng, Y., & Ma, J. (2023). Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models. IEEE Transactions on Image Processing.
[CrossRef] [Google Scholar] - Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 (pp. 740-755). Springer International Publishing.
[Google Scholar] - Zhao, Z., Xu, S., Zhang, J., Liang, C., Zhang, C., & Liu, J. (2021). Efficient and model-based infrared and visible image fusion via algorithm unrolling. IEEE Transactions on Circuits and Systems for Video Technology, 32(3), 1186-1196.
[CrossRef] [Google Scholar] - Jian, L., Yang, X., Liu, Z., Jeon, G., Gao, M., & Chisholm, D. (2020). SEDRFuse: A symmetric encoder–decoder with residual block network for infrared and visible image fusion. IEEE Transactions on Instrumentation and Measurement, 70, 1-15.
[CrossRef] [Google Scholar] - Jian, L., Rayhana, R., Ma, L., Wu, S., Liu, Z., & Jiang, H. (2021). Infrared and visible image fusion based on deep decomposition network and saliency analysis. IEEE Transactions on Multimedia, 24, 3314-3326.
[CrossRef] [Google Scholar] - Li, H., Xu, T., Wu, X. J., Lu, J., & Kittler, J. (2023). Lrrnet: A novel representation learning guided fusion network for infrared and visible images. IEEE transactions on pattern analysis and machine intelligence, 45(9), 11040-11052.
[CrossRef] [Google Scholar] - An, R., Liu, G., Qian, Y., Xing, M., & Tang, H. (2024). MRASFusion: A multi-scale residual attention infrared and visible image fusion network based on semantic segmentation guidance. Infrared Physics & Technology, 139, 105343.
[CrossRef] [Google Scholar] - Chen, B., Luo, S., Wu, H., Chen, M., & He, C. (2024). Infrared and visible image fusion and detection based on interactive training strategy and feature filter extraction module. Optics & Laser Technology, 179, 111383.
[CrossRef] [Google Scholar] - Zhu, P., Yin, Y., & Zhou, X. (2025). MGRCFusion: An infrared and visible image fusion network based on multi-scale group residual convolution. Optics & Laser Technology, 180, 111576.
[CrossRef] [Google Scholar] - Tang, W., He, F., Liu, Y., Duan, Y., & Si, T. (2023). DATFuse: Infrared and visible image fusion via dual attention transformer. IEEE Transactions on Circuits and Systems for Video Technology, 33(7), 3159-3172.
[CrossRef] [Google Scholar] - Ma, J., Tang, L., Fan, F., Huang, J., Mei, X., & Ma, Y. (2022). SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA Journal of Automatica Sinica, 9(7), 1200-1217.
[CrossRef] [Google Scholar] - Tang, W., He, F., & Liu, Y. (2023). TCCFusion: An infrared and visible image fusion method based on transformer and cross correlation. Pattern Recognition, 137, 109295.
[CrossRef] [Google Scholar] - Liu, J., Liu, Z., Wu, G., Ma, L., Liu, R., Zhong, W., ... & Fan, X. (2023). Multi-interactive feature learning and a full-time multi-modality benchmark for image fusion and segmentation. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 8115-8124).
[CrossRef] [Google Scholar] - Liu, J., Fan, X., Huang, Z., Wu, G., Liu, R., Zhong, W., & Luo, Z. (2022). Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5802-5811).
[CrossRef] [Google Scholar] - Wang, Z., Shao, W., Chen, Y., Xu, J., & Zhang, X. (2022). Infrared and visible image fusion via interactive compensatory attention adversarial learning. IEEE Transactions on Multimedia, 25, 7800-7813.
[CrossRef] [Google Scholar] - Wang, Z., Shao, W., Chen, Y., Xu, J., & Zhang, L. (2023). A cross-scale iterative attentional adversarial fusion network for infrared and visible images. IEEE Transactions on Circuits and Systems for Video Technology, 33(8), 3677-3688.
[CrossRef] [Google Scholar] - Wang, Z., Zhang, Z., Qi, W., Yang, F., & Xu, J. (2024). FreqGAN: Infrared and Visible Image Fusion via Unified Frequency Adversarial Learning. IEEE Transactions on Circuits and Systems for Video Technology.
[CrossRef] [Google Scholar] - Huang, Z., Wang, X., Wei, Y., Huang, L., Shi, H., Liu, W., & Huang, T. S. (2023). CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6), 6896-6908.
[CrossRef] [Google Scholar] - Roberts, J. W., Van Aardt, J. A., & Ahmed, F. B. (2008). Assessment of image fusion procedures using entropy, image quality, and multispectral classification. Journal of Applied Remote Sensing, 2(1), 023522.
[CrossRef] [Google Scholar] - Rao, Y. J. (1997). In-fibre Bragg grating sensors. Measurement science and technology, 8(4), 355.
[CrossRef] [Google Scholar] - Liu, Z., Forsyth, D. S., & Laganière, R. (2008). A feature-based metric for the quantitative evaluation of pixel-level image fusion. Computer Vision and Image Understanding, 109(1), 56-68.
[CrossRef] [Google Scholar] - Haghighat, M., & Razian, M. A. (2014, October). Fast-FMI: Non-reference image fusion metric. In 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT) (pp. 1-3). IEEE.
[CrossRef] [Google Scholar] - Piella, G., & Heijmans, H. (2003, September). A new quality metric for image fusion. In Proceedings 2003 international conference on image processing (Cat. No. 03CH37429) (Vol. 3, pp. III-173). IEEE.
[CrossRef] [Google Scholar] - Xydeas, C. S., & Petrovic, V. (2000). Objective image fusion performance measure. Electronics letters, 36(4), 308-309.
[Google Scholar] - Ma, K., Zeng, K., & Wang, Z. (2015). Perceptual quality assessment for multi-exposure image fusion. IEEE Transactions on Image Processing, 24(11), 3345-3356.
[CrossRef] [Google Scholar] - Han, Y., Cai, Y., Cao, Y., & Xu, X. (2013). A new image fusion performance metric based on visual information fidelity. Information fusion, 14(2), 127-135.
[CrossRef] [Google Scholar] - Sun, Y., Meng, Y., Wang, Q., Tang, M., Shen, T., & Wang, Q. (2023, August). Visible and infrared image fusion for object detection: a survey. In International Conference on Image, Vision and Intelligent Systems (pp. 236-248). Singapore: Springer Nature Singapore.
[CrossRef] [Google Scholar] - Wang, D., Liu, J., Liu, R., & Fan, X. (2023). An interactively reinforced paradigm for joint infrared-visible image fusion and saliency object detection. Information Fusion, 98, 101828.
[CrossRef] [Google Scholar] - Xue, S., Liu, Z., Chen, F., Zhang, S., Hu, T., Xie, E., & Li, Z. (2024). Accelerating diffusion sampling with optimized time steps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8292-8301).
[Google Scholar] - Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695).
[CrossRef] [Google Scholar]
Cited By (11)
-
Limin Guo, Yuwu Wang, Xiaohai Zhou, Yue Wu, Guifu Yang. Infrared and Visible Ship Image Fusion Based on Adaptive Cross-Modal Feature Interaction and Multiscale Frequency-Domain Transformation.
IEEE Transactions on Geoscience and Remote Sensing, 2026 , 64 .
[CrossRef] -
Yucheng Zhang, You Ma, Lin Chai. SamFusion:A model for multimodal image fusion guided by SAM’s rich semantics.
Infrared Physics & Technology, 2026 , 154 .
[CrossRef] -
Sheng Wang, Boxun Han, Linzhe Yang, Kexin Chen, Guodong Sun, Fu Xu. FPZNet: Fuzzy Perception Zero-Shot Learning for Infrared and Visible Image Fusion.
IEEE Transactions on Circuits and Systems for Video Technology, 2026 , 36 (6).
[CrossRef] -
Jun Xie, Hua Huang, Lingfei Song. A Model-Free Method for Irregular Bias Field Correction in Infrared Images.
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2026 , 19 .
[CrossRef] -
Shaobing Gao, Minjie Tan, Shun Lv, Yiguang Liu, Yongjie Li. Infrared and Visible Image Fusion Using Bimodal Neuron and Dynamic Receptive Field Mechanisms.
IEEE Transactions on Image Processing, 2026 , 35 .
[CrossRef] -
Yucheng Zhang, You Ma, Lin Chai. MKDFusion: modality knowledge decoupled for infrared and visible image fusion.
Applied Intelligence, 2025 , 55 (7).
[CrossRef] -
Jun Chen, Liling Yang, Wei Yu, Wenping Gong, Zhanchuan Cai, Jiayi Ma. SDSFusion: A Semantic-Aware Infrared and Visible Image Fusion Network for Degraded Scenes.
IEEE Transactions on Image Processing, 2025 , 34 .
[CrossRef] -
Xinyu Xiang, Qinglong Yan, Hao Zhang, Jiayi Ma. .
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 .
[CrossRef] -
Yingchun Xie, Wei Su, Chongliang Zhong, Chuan Cai, Yongna Yuan. Gloss-free sign language translation based on fusion attention.
Applied Soft Computing, 2025 , 185 .
[CrossRef] -
Sihan Zhai, Jianan Tang, Guangyu Ren, Hengyan Liu. .
2025 International Conference on Big Data and Data Mining (BDDM), 2025 .
[CrossRef] -
Xunpeng Yi, Yibing Zhang, Xinyu Xiang, Qinglong Yan, Han Xu, Jiayi Ma. .
2025 IEEE/CVF International Conference on Computer Vision (ICCV), 2025 .
[CrossRef]
Cite This Article
TY - JOUR AU - Qi, Wuqiang AU - Zhang, Zhuoqun AU - Wang, Zhishe PY - 2024 DA - 2024/12/31 TI - DMFuse: Diffusion Model Guided Cross-Attention Learning for Infrared and Visible Image Fusion JO - Chinese Journal of Information Fusion T2 - Chinese Journal of Information Fusion JF - Chinese Journal of Information Fusion VL - 1 IS - 3 SP - 226 EP - 242 DO - 10.62762/CJIF.2024.655617 UR - https://www.icck.org/article/abs/CJIF.2024.655617 KW - image fusion KW - diffusion model KW - feature interaction KW - attention mechanism KW - deep generative model AB - Image fusion aims to integrate complementary information from different sensors into a single fused output for superior visual description and scene understanding. The existing GAN-based fusion methods generally suffer from multiple challenges, such as unexplainable mechanism, unstable training, and mode collapse, which may affect the fusion quality. To overcome these limitations, this paper introduces a diffusion model guided cross-attention learning network, termed as DMFuse, for infrared and visible image fusion. Firstly, to improve the diffusion inference efficiency, we compress the quadruple channels of the denoising UNet network to achieve more efficient and robust model for fusion tasks. After that, we employ the pre-trained diffusion model as an autoencoder and incorporate its strong generative priors to further train the following fusion network. This design allows the generated diffusion features to effectively showcase high-quality distribution mapping ability. In addition, we devise a cross-attention interactive fusion module to establish the long-range dependencies from local diffusion features. This module integrates the global interactions to improve the complementary characteristics of different modalities. Finally, we propose a multi-level decoder network to reconstruct the fused output. Extensive experiments on fusion tasks and downstream applications, including object detection and semantic segmentation, indicate that the proposed model yields promising performance while maintaining competitive computational efficiency. The code and data are available at https://github.com/Zhishe-Wang/DMFuse. SN - 2998-3371 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Qi2024DMFuse,
author = {Wuqiang Qi and Zhuoqun Zhang and Zhishe Wang},
title = {DMFuse: Diffusion Model Guided Cross-Attention Learning for Infrared and Visible Image Fusion},
journal = {Chinese Journal of Information Fusion},
year = {2024},
volume = {1},
number = {3},
pages = {226-242},
doi = {10.62762/CJIF.2024.655617},
url = {https://www.icck.org/article/abs/CJIF.2024.655617},
abstract = {Image fusion aims to integrate complementary information from different sensors into a single fused output for superior visual description and scene understanding. The existing GAN-based fusion methods generally suffer from multiple challenges, such as unexplainable mechanism, unstable training, and mode collapse, which may affect the fusion quality. To overcome these limitations, this paper introduces a diffusion model guided cross-attention learning network, termed as DMFuse, for infrared and visible image fusion. Firstly, to improve the diffusion inference efficiency, we compress the quadruple channels of the denoising UNet network to achieve more efficient and robust model for fusion tasks. After that, we employ the pre-trained diffusion model as an autoencoder and incorporate its strong generative priors to further train the following fusion network. This design allows the generated diffusion features to effectively showcase high-quality distribution mapping ability. In addition, we devise a cross-attention interactive fusion module to establish the long-range dependencies from local diffusion features. This module integrates the global interactions to improve the complementary characteristics of different modalities. Finally, we propose a multi-level decoder network to reconstruct the fused output. Extensive experiments on fusion tasks and downstream applications, including object detection and semantic segmentation, indicate that the proposed model yields promising performance while maintaining competitive computational efficiency. The code and data are available at https://github.com/Zhishe-Wang/DMFuse.},
keywords = {image fusion, diffusion model, feature interaction, attention mechanism, deep generative model},
issn = {2998-3371},
publisher = {Institute of Central Computation and Knowledge}
}
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions
 Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Central Computation and Knowledge. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.

Portico

