Capturing Poetic Essence: Text Summarization and Visual Generation via Multimodal

Article Information
Abstract
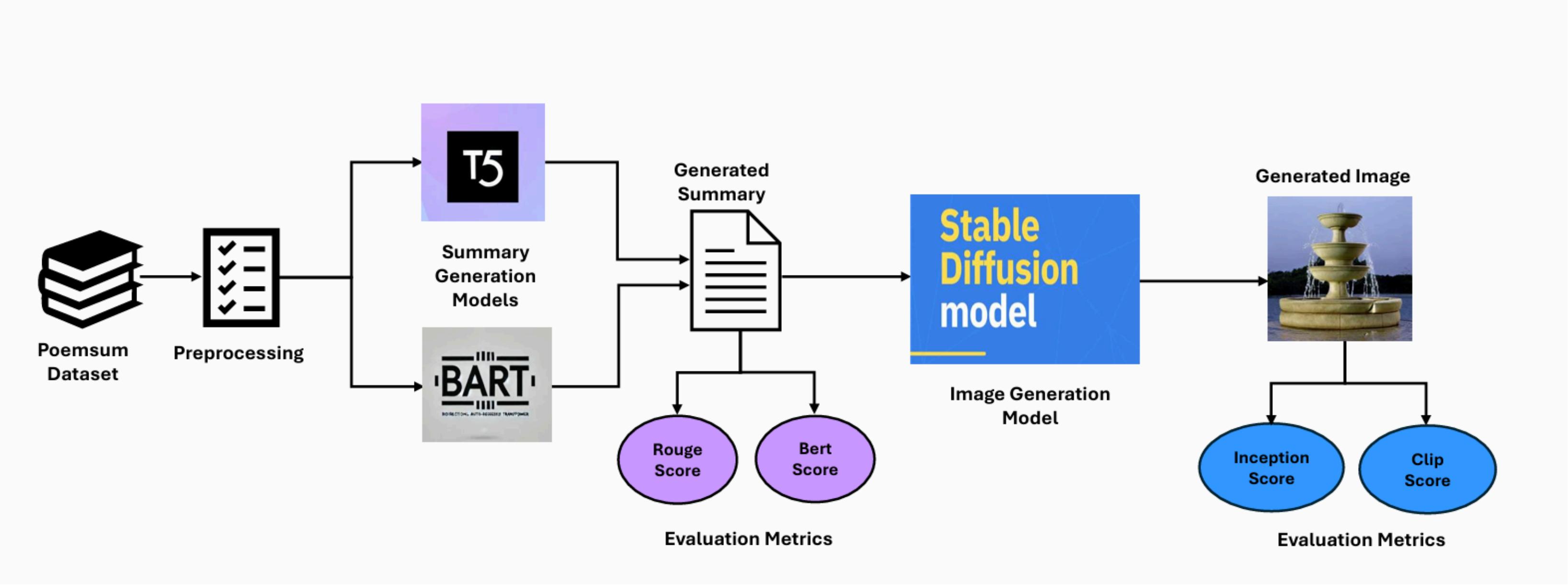
Multimodal intelligent systems that integrate natural language processing with generative visual synthesis represent a frontier in intelligent information processing. This work addresses the design and evaluation of such a pipeline, using poetic content as a stress-test domain due to its high density of figurative language and abstract semantics. Building upon the PoemSum dataset, we construct a two-stage multimodal pipeline: first employing transformer-based models (BART and T5) for abstractive summarization, then leveraging Stable Diffusion for visual synthesis from the generated summaries. The summarization stage focuses on figurative interpretation that captures metaphorical and symbolic elements inherent in poetic language. Evaluation results show that the BART model outperforms T5 in summarization, achieving a ROUGE score of 41.90% and a BERTScore of 85.22. For image generation, the Inception Score (IS) of 7.63 $\pm$ 0.62 reflects high visual quality and diversity, while the CLIP Score of 29.48 indicates strong semantic alignment between textual summaries and generated images. The proposed architecture demonstrates a generalizable framework for multimodal intelligent systems, with potential applications in intelligent tutoring, automated content generation, and human-computer interaction.
Graphical Abstract
Keywords
Data Availability Statement
Funding
Conflicts of Interest
Ethical Approval and Consent to Participate
References
- Mahbub, R., Khan, I., Anuva, S., Shahriar, M. S., Laskar, M. T. R., & Ahmed, S. (2023, December). Unveiling the essence of poetry: Introducing a comprehensive dataset and bench
[Google Scholar] - Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems (NeurIPS), 33, 6840–6851.
[CrossRef] [Google Scholar] - Li, B., Qi, X., Lukasiewicz, T., & Torr, P. (2019). Controllable text-to-image generation. Advances in neural information processing systems, 32.
[CrossRef] [Google Scholar] - Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., ... & Zettlemoyer, L. (2020). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (p. 7871). Association for Computational Linguistics.
[CrossRef] [Google Scholar] - Virmani, M., Pathak, M., Pai, K. S., & Prasad, V. B. (2023, May). Image synthesis from themes captured in poems using latent diffusion models. In 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC) (pp. 655-660). IEEE.
[CrossRef] [Google Scholar] - Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140), 1-67.
[Google Scholar] - Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695).
[Google Scholar] - Lin, C. Y. (2004, July). Rouge: A package for automatic evaluation of summaries. In Text summarization branches out (pp. 74-81). https://aclanthology.org/W04-1013.pdf
[Google Scholar] - Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., & Artzi, Y. (2019). BERTScore: Evaluating text generation with BERT. arXiv preprint arXiv:1904.09675.
[Google Scholar] - Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved techniques for training gans. Advances in neural information processing systems, 29.
[Google Scholar] - Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PmLR.
[Google Scholar] - Nasfi, R., De Tré, G., & Bronselaer, A. (2025). Improving data cleaning by learning from unstructured textual data. IEEE Access.
[CrossRef] [Google Scholar] - Chu, X., Ilyas, I. F., Krishnan, S., & Wang, J. (2016, June). Data cleaning: Overview and emerging challenges. In Proceedings of the 2016 international conference on management of data (pp. 2201-2206).
[CrossRef] [Google Scholar]
Cited By (2)
-
Danping Han, Tao Xu, Jue Li, Qingqing Yu, Wenbin Nie, Jiayan Li. Element mining, network associations and scene reconstruction of qiantang river poetry road literary allusion landscapes.
npj Heritage Science, 2026 , 14 (1).
[CrossRef] -
Md. Ismiel Hossen Abir, Nayeema Ferdous, Afsara Tasnim, Nabiha Mustaqeem. .
2026 5th International Conference on Electrical, Computer & Telecommunication Engineering (ICECTE), 2026 .
[CrossRef]
Cite This Article
TY - JOUR AU - Yousaf, Junaid AU - Iqbal, Mazhar AU - Pervaiz, Iqra AU - Ismail, Muhammad AU - Islam, Toqeer Ul AU - Jadoon, Khurram Khan PY - 2025 DA - 2025/07/27 TI - Capturing Poetic Essence: Text Summarization and Visual Generation via Multimodal JO - ICCK Transactions on Intelligent Systematics T2 - ICCK Transactions on Intelligent Systematics JF - ICCK Transactions on Intelligent Systematics VL - 2 IS - 3 SP - 160 EP - 168 DO - 10.62762/TIS.2025.405393 UR - https://www.icck.org/article/abs/TIS.2025.405393 KW - multimodal intelligent systems KW - abstractive summarization KW - text-to-image synthesis KW - diffusion models KW - semantic alignment KW - transformer architectures AB - Multimodal intelligent systems that integrate natural language processing with generative visual synthesis represent a frontier in intelligent information processing. This work addresses the design and evaluation of such a pipeline, using poetic content as a stress-test domain due to its high density of figurative language and abstract semantics. Building upon the PoemSum dataset, we construct a two-stage multimodal pipeline: first employing transformer-based models (BART and T5) for abstractive summarization, then leveraging Stable Diffusion for visual synthesis from the generated summaries. The summarization stage focuses on figurative interpretation that captures metaphorical and symbolic elements inherent in poetic language. Evaluation results show that the BART model outperforms T5 in summarization, achieving a ROUGE score of 41.90% and a BERTScore of 85.22. For image generation, the Inception Score (IS) of 7.63 $\pm$ 0.62 reflects high visual quality and diversity, while the CLIP Score of 29.48 indicates strong semantic alignment between textual summaries and generated images. The proposed architecture demonstrates a generalizable framework for multimodal intelligent systems, with potential applications in intelligent tutoring, automated content generation, and human-computer interaction. SN - 3068-5079 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Yousaf2025Capturing,
author = {Junaid Yousaf and Mazhar Iqbal and Iqra Pervaiz and Muhammad Ismail and Toqeer Ul Islam and Khurram Khan Jadoon},
title = {Capturing Poetic Essence: Text Summarization and Visual Generation via Multimodal},
journal = {ICCK Transactions on Intelligent Systematics},
year = {2025},
volume = {2},
number = {3},
pages = {160-168},
doi = {10.62762/TIS.2025.405393},
url = {https://www.icck.org/article/abs/TIS.2025.405393},
abstract = {Multimodal intelligent systems that integrate natural language processing with generative visual synthesis represent a frontier in intelligent information processing. This work addresses the design and evaluation of such a pipeline, using poetic content as a stress-test domain due to its high density of figurative language and abstract semantics. Building upon the PoemSum dataset, we construct a two-stage multimodal pipeline: first employing transformer-based models (BART and T5) for abstractive summarization, then leveraging Stable Diffusion for visual synthesis from the generated summaries. The summarization stage focuses on figurative interpretation that captures metaphorical and symbolic elements inherent in poetic language. Evaluation results show that the BART model outperforms T5 in summarization, achieving a ROUGE score of 41.90\% and a BERTScore of 85.22. For image generation, the Inception Score (IS) of 7.63 \$\pm\$ 0.62 reflects high visual quality and diversity, while the CLIP Score of 29.48 indicates strong semantic alignment between textual summaries and generated images. The proposed architecture demonstrates a generalizable framework for multimodal intelligent systems, with potential applications in intelligent tutoring, automated content generation, and human-computer interaction.},
keywords = {multimodal intelligent systems, abstractive summarization, text-to-image synthesis, diffusion models, semantic alignment, transformer architectures},
issn = {3068-5079},
publisher = {Institute of Central Computation and Knowledge}
}
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions

Portico

