MAFNet: Multi-level Attention Fusion Network for Precise Prominence Analysis in Visual Sensing Systems


Article Information
Abstract
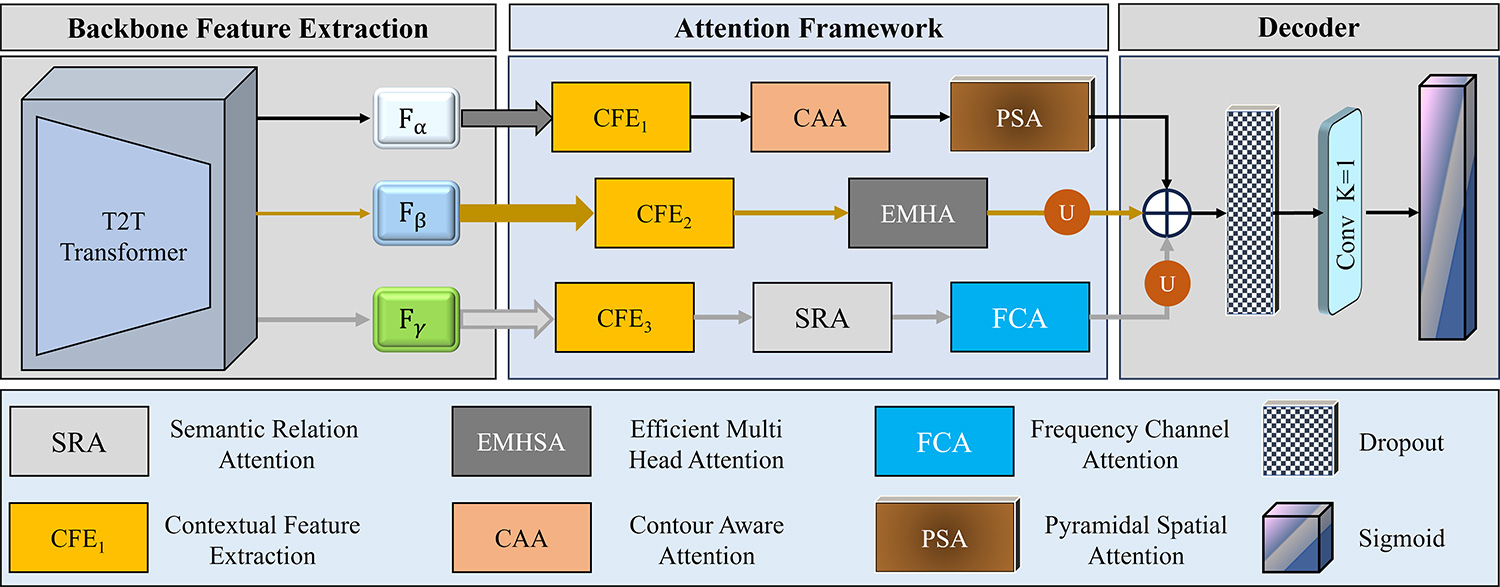
Salient object detection aims to identify and segment the most visually prominent objects in images. Despite significant advances in deep learning, existing methods struggle to balance global context modeling, boundary preservation, and multi-scale feature integration. To address these limitations, we propose MAFNet (Multi-level Attention Fusion Network), a novel attention-driven framework that leverages specialized attention mechanisms tailored to different semantic levels. Our approach employs a Tokens-to-Token (T2T) Transformer backbone for hierarchical feature extraction, capturing both local structural details and global contextual relationships. The core contribution lies in a comprehensive attention framework comprising six specialized modules: Contextual Feature Extraction (CFE) for multi-scale context refinement, Contour Aware Attention (CAA) for boundary preservation, Pyramidal Spatial Attention (PSA) for hierarchical spatial reasoning, Efficient Multi-Head Attention (EMHA) for semantic enhancement, Semantic Relation Attention (SRA) for global context modeling, and Frequency Channel Attention (FCA) for frequency-domain feature enhancement. These refined features are integrated through a parallel multi-path decoder that efficiently fuses information from different semantic levels. Extensive experiments on six benchmark datasets (ECSSD, PASCAL-S, SOD, DUTS-TE, HKU-IS, and DUT-OMRON) demonstrate that MAFNet achieves state-of-the-art performance, with particular strengths in handling complex object configurations and preserving fine-grained boundaries.
Graphical Abstract
Keywords
Data Availability Statement
Funding
Conflicts of Interest
AI Use Statement
Ethical Approval and Consent to Participate
References
- Borji, A., Cheng, M. M., Jiang, H., & Li, J. (2015). Salient object detection: A benchmark. IEEE transactions on image processing, 24(12), 5706-5722.
[CrossRef] [Google Scholar] - Wang, Y., Wang, R., Liu, J., Xu, R., Wang, T., Hou, F., ... & Lei, N. (2025). TFGNet: Frequency-guided saliency detection for complex scenes. Applied Soft Computing, 170, 112685.
[CrossRef] [Google Scholar] - Borji, A., & Itti, L. (2012, June). Exploiting local and global patch rarities for saliency detection. In 2012 IEEE conference on computer vision and pattern recognition (pp. 478-485). IEEE.
[CrossRef] [Google Scholar] - Yang, C., Zhang, L., Lu, H., Ruan, X., & Yang, M. H. (2013, June). Saliency Detection via Graph-Based Manifold Ranking. In 2013 IEEE Conference on Computer Vision and Pattern Recognition (pp. 3166-3173). IEEE.
[CrossRef] [Google Scholar] - Huo, L., Jiao, L., Wang, S., & Yang, S. (2016). Object-level saliency detection with color attributes. Pattern recognition, 49, 162-173.
[CrossRef] [Google Scholar] - Amjoud, A. B., & Amrouch, M. (2023). Object detection using deep learning, CNNs and vision transformers: A review. IEEE Access, 11, 35479-35516.
[CrossRef] [Google Scholar] - Wei, L., Zhu, Z., Mi, Y., & Hu, W. (2025). PDNet: Pluralistic depth-aware network for RGB-D salient object detection. Signal Processing, 110271.
[CrossRef] [Google Scholar] - Wan, B., Zhou, X., Sun, Y., Wang, T., Lv, C., Wang, S., ... & Yan, C. (2023). MFFNet: Multi-modal feature fusion network for VDT salient object detection. IEEE Transactions on Multimedia, 26, 2069-2081.
[CrossRef] [Google Scholar] - Liu, N., Zhang, N., Wan, K., Shao, L., & Han, J. (2021, October). Visual Saliency Transformer. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (pp. 4702-4712). IEEE.
[CrossRef] [Google Scholar] - Wang, W., Lai, Q., Fu, H., Shen, J., Ling, H., & Yang, R. (2021). Salient object detection in the deep learning era: An in-depth survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(6), 3239-3259.
[CrossRef] [Google Scholar] - Qin, X., Zhang, Z., Huang, C., Gao, C., Dehghan, M., & Jagersand, M. (2019, June). BASNet: Boundary-Aware Salient Object Detection. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 7471-7481). IEEE.
[CrossRef] [Google Scholar] - Usman, M. T., Khan, H., Rida, I., & Koo, J. (2025). Lightweight transformer-driven multi-scale trapezoidal attention network for saliency detection. Engineering Applications of Artificial Intelligence, 155, 110917.
[CrossRef] [Google Scholar] - Chen, S., Tan, X., Wang, B., & Hu, X. (2018, September). Reverse Attention for Salient Object Detection. In European Conference on Computer Vision (pp. 236-252). Cham: Springer International Publishing.
[CrossRef] [Google Scholar] - Zhao, T., & Wu, X. (2019, June). Pyramid Feature Attention Network for Saliency Detection. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3080-3089). IEEE.
[CrossRef] [Google Scholar] - Zhang, J., Shi, Y., Zhang, Q., Cui, L., Chen, Y., & Yi, Y. (2022). Attention guided contextual feature fusion network for salient object detection. Image and Vision Computing, 117, 104337.
[CrossRef] [Google Scholar] - Khan, H., Usman, M. T., Rida, I., & Koo, J. (2024). Attention enhanced machine instinctive vision with human-inspired saliency detection. Image and Vision Computing, 152, 105308.
[CrossRef] [Google Scholar] - Zhao, R., Ouyang, W., Li, H., & Wang, X. (2015, June). Saliency detection by multi-context deep learning. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 1265-1274). IEEE.
[CrossRef] [Google Scholar] - Li, G., & Yu, Y. (2015, June). Visual saliency based on multiscale deep features. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 5455-5463). IEEE.
[CrossRef] [Google Scholar] - Liu, N., & Han, J. (2016, June). DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 678-686). IEEE.
[CrossRef] [Google Scholar] - Wang, L., Wang, L., Lu, H., Zhang, P., & Ruan, X. (2016, September). Saliency detection with recurrent fully convolutional networks. In European conference on computer vision (pp. 825-841). Cham: Springer International Publishing.
[CrossRef] [Google Scholar] - Zhang, L., Dai, J., Lu, H., He, Y., & Wang, G. (2018, June). A Bi-Directional Message Passing Model for Salient Object Detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1741-1750). IEEE.
[CrossRef] [Google Scholar] - Zeng, Y., Lu, H., Zhang, L., Feng, M., & Borji, A. (2018, June). Learning to Promote Saliency Detectors. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1644-1653). IEEE.
[CrossRef] [Google Scholar] - Jiang, Y., Yang, Z., Deng, L., & Zhou, T. (2025). Multi-Scale attention Coordination Network for remote sensing image salient object detection. Optics & Laser Technology, 192, 113751.
[CrossRef] [Google Scholar] - Islam, M. A., Kalash, M., & Bruce, N. D. (2018, June). Revisiting Salient Object Detection: Simultaneous Detection, Ranking, and Subitizing of Multiple Salient Objects. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7142-7150). IEEE.
[CrossRef] [Google Scholar] - Jia, S., & Bruce, N. D. (2019). Richer and deeper supervision network for salient object detection. arXiv preprint arXiv:1901.02425.
[CrossRef] [Google Scholar] - Cong, R., Zhang, Y., Fang, L., Li, J., Zhao, Y., & Kwong, S. (2021). RRNet: Relational reasoning network with parallel multiscale attention for salient object detection in optical remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 60, 1-11.
[CrossRef] [Google Scholar] - Liu, Y., Cheng, M. M., Zhang, X. Y., Nie, G. Y., & Wang, M. (2021). DNA: Deeply supervised nonlinear aggregation for salient object detection. IEEE Transactions on Cybernetics, 52(7), 6131-6142.
[CrossRef] [Google Scholar] - Song, S., Jia, Z., Yang, J., & Kasabov, N. (2022). Salient detection via the fusion of background-based and multiscale frequency-domain features. Information Sciences, 618, 53-71.
[CrossRef] [Google Scholar] - Chen, Z., Lu, Y., Long, S., & Bai, J. (2024). Dual-path multi-branch feature residual network for salient object detection. Engineering Applications of Artificial Intelligence, 133, 108530.
[CrossRef] [Google Scholar] - Zhang, L., Li, X., Sun, Y., & Guo, H. (2025). Triple-attentions based salient object detector for strip steel surface defects. Scientific Reports, 15(1), 2537.
[CrossRef] [Google Scholar] - Noori, M., Mohammadi, S., Majelan, S. G., Bahri, A., & Havaei, M. (2020). DFNet: Discriminative feature extraction and integration network for salient object detection. Engineering Applications of Artificial Intelligence, 89, 103419.
[CrossRef] [Google Scholar] - Lin, Y., Sun, H., Liu, N., Bian, Y., Cen, J., & Zhou, H. (2022, September). Attention guided network for salient object detection in optical remote sensing images. In International conference on artificial neural networks (pp. 25-36). Cham: Springer International Publishing.
[CrossRef] [Google Scholar] - Li, H., Han, Y., Li, P., Li, X., & Shi, L. (2023). Hybrid attention mechanism and forward feedback unit for RGB-D salient object detection. IEEE Access, 11, 96068-96080.
[CrossRef] [Google Scholar] - Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
[CrossRef] [Google Scholar] - Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., & Jégou, H. (2021, July). Training data-efficient image transformers & distillation through attention. In International conference on machine learning (pp. 10347-10357). PMLR. https://proceedings.mlr.press/v139/touvron21a
[Google Scholar] - Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., ... & Shao, L. (2021, October). Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (pp. 548-558). IEEE.
[CrossRef] [Google Scholar] - Yuan, L., Chen, Y., Wang, T., Yu, W., Shi, Y., Jiang, Z., ... & Yan, S. (2021, October). Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV) (pp. 538-547). IEEE.
[CrossRef] [Google Scholar] - Li, G., Bai, Z., Liu, Z., Zhang, X., & Ling, H. (2023). Salient object detection in optical remote sensing images driven by transformer. IEEE Transactions on Image Processing, 32, 5257-5269.
[CrossRef] [Google Scholar] - Qiu, Y., Liu, Y., Zhang, L., Lu, H., & Xu, J. (2023). Boosting salient object detection with transformer-based asymmetric bilateral U-Net. IEEE Transactions on Circuits and Systems for Video Technology, 34(4), 2332-2345.
[CrossRef] [Google Scholar] - Zeng, C., Kwong, S., & Ip, H. (2023). Dual swin-transformer based mutual interactive network for RGB-D salient object detection. Neurocomputing, 559, 126779.
[CrossRef] [Google Scholar] - Ren, S., Zhao, N., Wen, Q., Han, G., & He, S. (2024). Unifying global-local representations in salient object detection with transformers. IEEE Transactions on Emerging Topics in Computational Intelligence, 8(4), 2870-2879.
[CrossRef] [Google Scholar] - Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7794-7803).
[CrossRef] [Google Scholar] - Wang, L., Lu, H., Wang, Y., Feng, M., Wang, D., Yin, B., & Ruan, X. (2017, July). Learning to Detect Salient Objects with Image-Level Supervision. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3796-3805). IEEE.
[CrossRef] [Google Scholar] - Yan, Q., Xu, L., Shi, J., & Jia, J. (2013, June). Hierarchical Saliency Detection. In 2013 IEEE Conference on Computer Vision and Pattern Recognition (pp. 1155-1162). IEEE.
[CrossRef] [Google Scholar] - Li, Y., Hou, X., Koch, C., Rehg, J. M., & Yuille, A. L. (2014, June). The Secrets of Salient Object Segmentation. In 2014 IEEE Conference on Computer Vision and Pattern Recognition (pp. 280-287). IEEE.
[CrossRef] [Google Scholar] - Movahedi, V., & Elder, J. H. (2010, June). Design and perceptual validation of performance measures for salient object segmentation. In 2010 IEEE computer society conference on computer vision and pattern recognition-workshops (pp. 49-56). IEEE.
[CrossRef] [Google Scholar] - Liu, N., Han, J., & Yang, M. H. (2018, June). PiCANet: Learning Pixel-Wise Contextual Attention for Saliency Detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3089-3098). IEEE.
[CrossRef] [Google Scholar] - Deng, Z., Hu, X., Zhu, L., Xu, X., Qin, J., Han, G., & Heng, P. A. (2018, July). R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th international joint conference on artificial intelligence (Vol. 684690). Menlo Park, CA, USA: AAAI Press. https://www.ijcai.org/proceedings/2018/0095.pdf
[Google Scholar] - Wu, Z., Su, L., & Huang, Q. (2019, June). Cascaded Partial Decoder for Fast and Accurate Salient Object Detection. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3902-3911). IEEE.
[CrossRef] [Google Scholar] - Zhao, J., Liu, J. J., Fan, D. P., Cao, Y., Yang, J., & Cheng, M. M. (2019, October). EGNet: Edge Guidance Network for Salient Object Detection. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (pp. 8778-8787). IEEE.
[CrossRef] [Google Scholar] - Zhao, X., Pang, Y., Zhang, L., Lu, H., & Zhang, L. (2020, August). Suppress and balance: A simple gated network for salient object detection. In European conference on computer vision (pp. 35-51). Cham: Springer International Publishing.
[CrossRef] [Google Scholar] - Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O. R., & Jagersand, M. (2020). U2-Net: Going deeper with nested U-structure for salient object detection. Pattern recognition, 106, 107404.
[CrossRef] [Google Scholar] - Pang, Y., Zhao, X., Zhang, L., & Lu, H. (2020, June). Multi-Scale Interactive Network for Salient Object Detection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 9410-9419). IEEE.
[CrossRef] [Google Scholar] - Wei, J., Wang, S., & Huang, Q. (2020, April). F3Net: Fusion, Feedback and Focus for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 12321-12328).
[CrossRef] [Google Scholar] - Wei, J., Wang, S., Wu, Z., Su, C., Huang, Q., & Tian, Q. (2020). Label decoupling framework for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13025-13034).
[CrossRef] [Google Scholar]
Cite This Article
TY - JOUR AU - Ali, Farhan AU - Ali, Muhammad AU - Muhammad, Zaid PY - 2026 DA - 2026/06/30 TI - MAFNet: Multi-level Attention Fusion Network for Precise Prominence Analysis in Visual Sensing Systems JO - ICCK Transactions on Sensing, Communication, and Control T2 - ICCK Transactions on Sensing, Communication, and Control JF - ICCK Transactions on Sensing, Communication, and Control VL - 3 IS - 2 SP - 124 EP - 138 DO - 10.62762/TSCC.2025.390515 UR - https://www.icck.org/article/abs/TSCC.2025.390515 KW - saliency detection KW - multi-level attention KW - feature fusion KW - contour awareness KW - frequency channel attention AB - Salient object detection aims to identify and segment the most visually prominent objects in images. Despite significant advances in deep learning, existing methods struggle to balance global context modeling, boundary preservation, and multi-scale feature integration. To address these limitations, we propose MAFNet (Multi-level Attention Fusion Network), a novel attention-driven framework that leverages specialized attention mechanisms tailored to different semantic levels. Our approach employs a Tokens-to-Token (T2T) Transformer backbone for hierarchical feature extraction, capturing both local structural details and global contextual relationships. The core contribution lies in a comprehensive attention framework comprising six specialized modules: Contextual Feature Extraction (CFE) for multi-scale context refinement, Contour Aware Attention (CAA) for boundary preservation, Pyramidal Spatial Attention (PSA) for hierarchical spatial reasoning, Efficient Multi-Head Attention (EMHA) for semantic enhancement, Semantic Relation Attention (SRA) for global context modeling, and Frequency Channel Attention (FCA) for frequency-domain feature enhancement. These refined features are integrated through a parallel multi-path decoder that efficiently fuses information from different semantic levels. Extensive experiments on six benchmark datasets (ECSSD, PASCAL-S, SOD, DUTS-TE, HKU-IS, and DUT-OMRON) demonstrate that MAFNet achieves state-of-the-art performance, with particular strengths in handling complex object configurations and preserving fine-grained boundaries. SN - 3068-9287 PB - Institute of Central Computation and Knowledge LA - English ER -
@article{Ali2026MAFNet,
author = {Farhan Ali and Muhammad Ali and Zaid Muhammad},
title = {MAFNet: Multi-level Attention Fusion Network for Precise Prominence Analysis in Visual Sensing Systems},
journal = {ICCK Transactions on Sensing, Communication, and Control},
year = {2026},
volume = {3},
number = {2},
pages = {124-138},
doi = {10.62762/TSCC.2025.390515},
url = {https://www.icck.org/article/abs/TSCC.2025.390515},
abstract = {Salient object detection aims to identify and segment the most visually prominent objects in images. Despite significant advances in deep learning, existing methods struggle to balance global context modeling, boundary preservation, and multi-scale feature integration. To address these limitations, we propose MAFNet (Multi-level Attention Fusion Network), a novel attention-driven framework that leverages specialized attention mechanisms tailored to different semantic levels. Our approach employs a Tokens-to-Token (T2T) Transformer backbone for hierarchical feature extraction, capturing both local structural details and global contextual relationships. The core contribution lies in a comprehensive attention framework comprising six specialized modules: Contextual Feature Extraction (CFE) for multi-scale context refinement, Contour Aware Attention (CAA) for boundary preservation, Pyramidal Spatial Attention (PSA) for hierarchical spatial reasoning, Efficient Multi-Head Attention (EMHA) for semantic enhancement, Semantic Relation Attention (SRA) for global context modeling, and Frequency Channel Attention (FCA) for frequency-domain feature enhancement. These refined features are integrated through a parallel multi-path decoder that efficiently fuses information from different semantic levels. Extensive experiments on six benchmark datasets (ECSSD, PASCAL-S, SOD, DUTS-TE, HKU-IS, and DUT-OMRON) demonstrate that MAFNet achieves state-of-the-art performance, with particular strengths in handling complex object configurations and preserving fine-grained boundaries.},
keywords = {saliency detection, multi-level attention, feature fusion, contour awareness, frequency channel attention},
issn = {3068-9287},
publisher = {Institute of Central Computation and Knowledge}
}
Article Metrics
Publisher's Note
ICCK stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and Permissions

Portico
